文章目录
- 前言
- ALBEF:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation(2021-10)
- VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts(2021-11)
- BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- CoCa: Contrastive Captioners are Image-Text Foundation Models
- BeiT V3--Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
前言
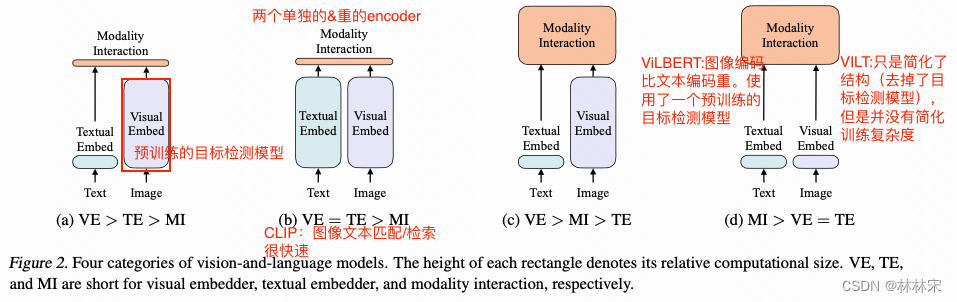
- 图文多模态任务的经验:(1)iamge encoder的能力要比text encoder更大才可以;(2)模态融合的部分也要大;(3)对比学习,masked language model,image text matching loss都被证明是有正向效果的。
- 文图下游任务:
- Visual Question Answering (VQA):输入是一张图片及一个问题(用文本描述),输出是一组答案集合中的一个答案,即可以把他当成一个分类任务;
- Visual Reasoning(VR):输入是一句文本描述以及两张图片,输出是这个文本描述是否正确。同样是以acc作为metric,是一个二分类任务;
- Visual Entailment(VR,视觉蕴含):是从文本蕴含(一个文本作为前提,另一个文本作为假设,判断根据前提是否能推理出假设)到多模态一个新生的任务;视觉蕴含中的前提是图片,是一个三分类任务,判别结果为【是,中性,否】三类;
- Image Caption:根据一张图片生成对应的字幕;
其他的新工作:
- language interface:metaLM,Pali
- generalist model: Unified IO, UniPerceiver系列
ALBEF:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation(2021-10)

作者提出的两个改进工作:(1)在fusing之前,计算image和text的相似度,做align;(2)引入momentum distill,降低带噪数据在训练集中的干扰。本工作基于40w图片文本对开源数据集训练,8卡*4days。
-
借鉴之前的经验:visual encoder是12FFT,text encoder是6FFT, fusion encoder也是6*FFT;IMT,MLM,ITM三个loss都被保留;
-
实现细节:
- image text matching loss(ITM Loss):经由fc layer,实际上是一个二分类loss,判断一个【text,image】是不是一对数据,但实际训练中,会有大量的分类结果为否的情况,使得ITM Loss看起来很低,但实际并不一定起到足够的效果。因此,从ITC对比学习计算的cosine distance中选择和真实样本距离最近的(最难分辨的,称之为hard negatives),用于ITM loss训练;
- momentum distill
- 问题:爬虫的图片,大部分只有hash tag的关键词,并不是一句话描述,one-hot label不利于对比学习训练;其次,MLM在填空时,合适且正确的词选并不只有一个,one hot label也会影响MLM loss;
- 解决方法:模型不仅缩小真实样本对的距离, 还通过额外的momentum model生成伪标签,缩小image和伪标签的距离。(EMA算法)
-
损失函数:2个IT,2个MLM,1个ITM



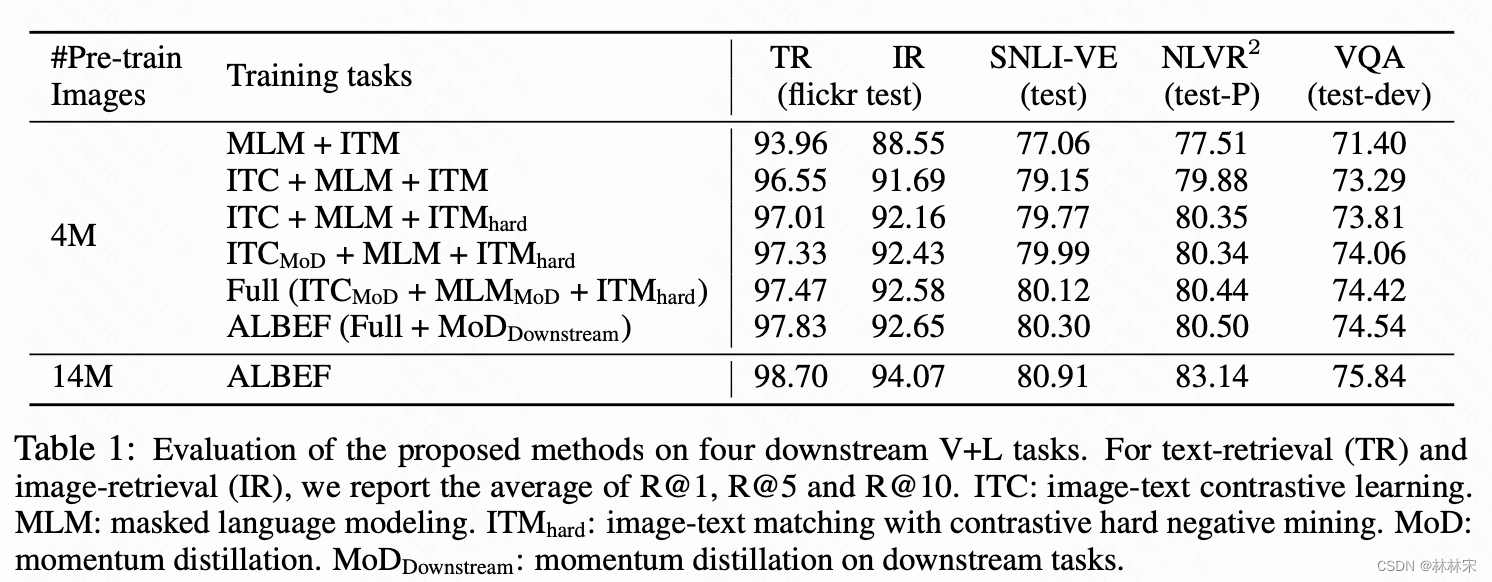
- 消融实验的对比结果:hard negative用在ITM loss上改善很明显;数据量加大,momentum distill的作用开始凸显。
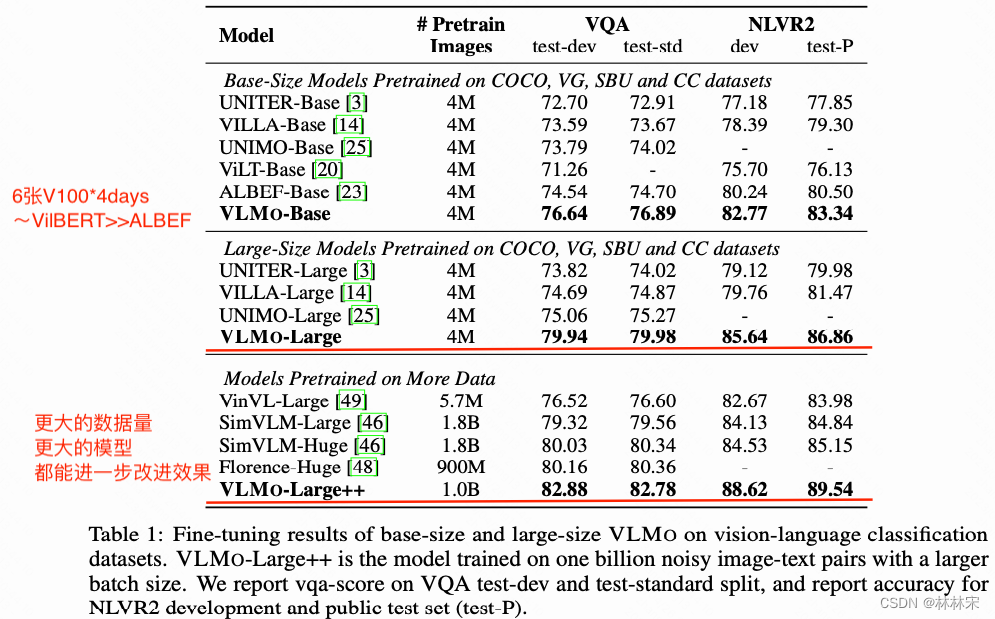
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts(2021-11)
- microsoft
- code and pretrained-model
- Hangbo Bao,Wenhui Wang,Furu Wei
- 改团队基于本工作的后续工作:WaveLM,MetaLM,BEiT V1/V2/V3
related
- 当前常用的结构:
- 双塔网络:image encoder和text encoder ,分别编码;优点在于inference的时候可以将可用的embedding提前计算好,另外一路image or text直接通过矩阵乘计算cosine similarity,很快速的完成检索;缺点在于模态融合的部分是shallow mix,对于复杂任务(比如VR/VE/VQA)表现不好;
- 单塔fusion encoder:使用单个encoder处理image和text,使得两个模态得到充分的融合;缺点:在处理检索问题的时候比较复杂,耗时高。
- 是否能够将两种结构的优点结合一下。本文的idea
- 结构改进:先使用共享的fusion module,使得不同的模态充分的融合,再对不同的模态使用单独的专家网络(FFN),在下游任务时保证了高效性;
- 预训练过程分阶段:因为【image,text】的数据比较稀缺,利用大量的单模态数据对网络参数进行预训练,然后再利用【image,text】数据进行训练。
method
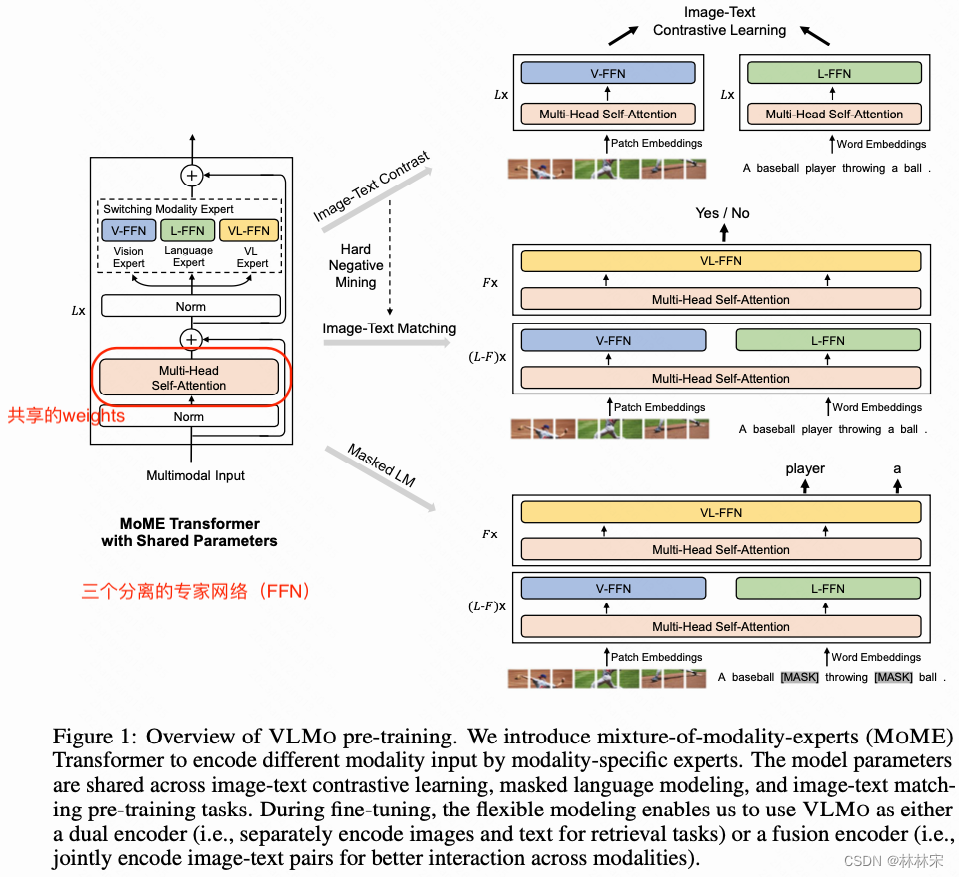
- 如上图所示,multi-head attention是fusion module,文本/图像/文本-图像分别是三个单独的专家网络;根据不同的输入,选择不同的专家网络计算损失函数,也是一个iter需要多次forward,不同的输入计算不同的loss;
- 分阶段预训练:参考下图,先基于image数据;再基于text数据,值得注意的是,text-only训练的时候,slf-attn的参数是共享image的,不做更新;最后基于【image,text】数据训练。

BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 问题
- encoder-only的结构不能用于生成任务;encoder-decoder的结构不利于检索任务,是否有统一的框架;
- 训练的数据集是网上爬取的,存在很多噪声,影响训练的结果,使用预训练的模型对数据进行清洗
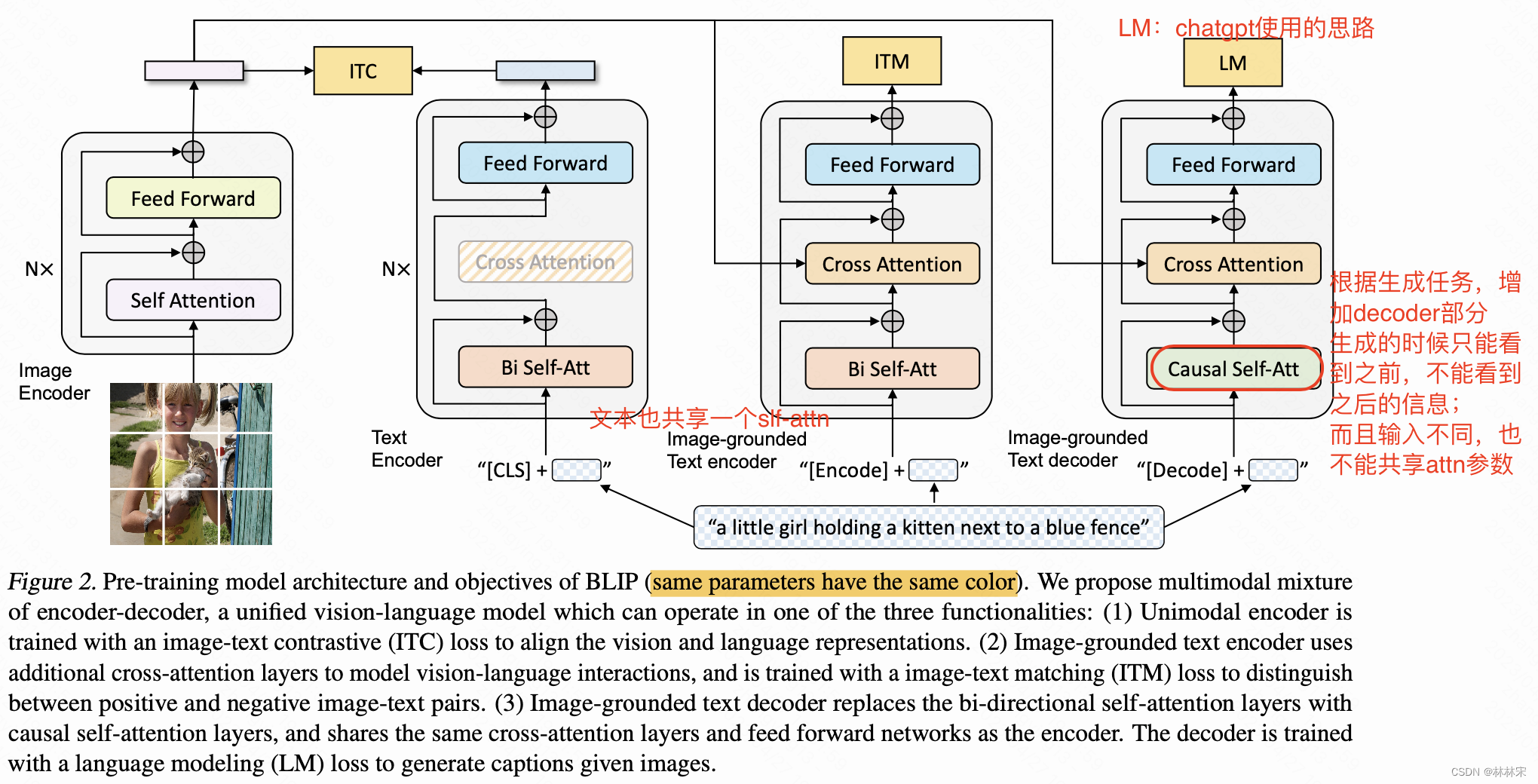
- 如上图所示,BLIP结构借鉴了VLMo共享权重的思路,一个image encoder,针对不同的任务训练不同的text encoder和image-grounded text decoder。相同颜色的模块表示共享一组权重。image-grounded text decoder因为是生成任务,所以使用的是单独训练的causal self-att,mask掉后边的信息。
- ITC Loss,ITM loss,LM Loss,因此模型一个iter要走三次前向计算不同的loss
filter-caption数据清洗
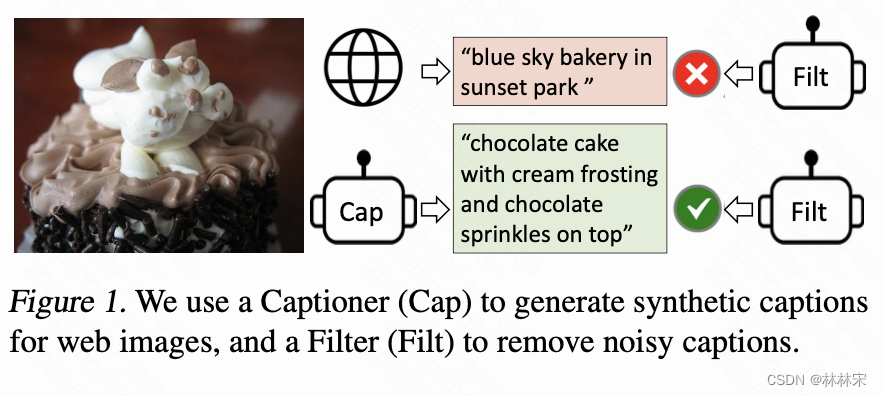
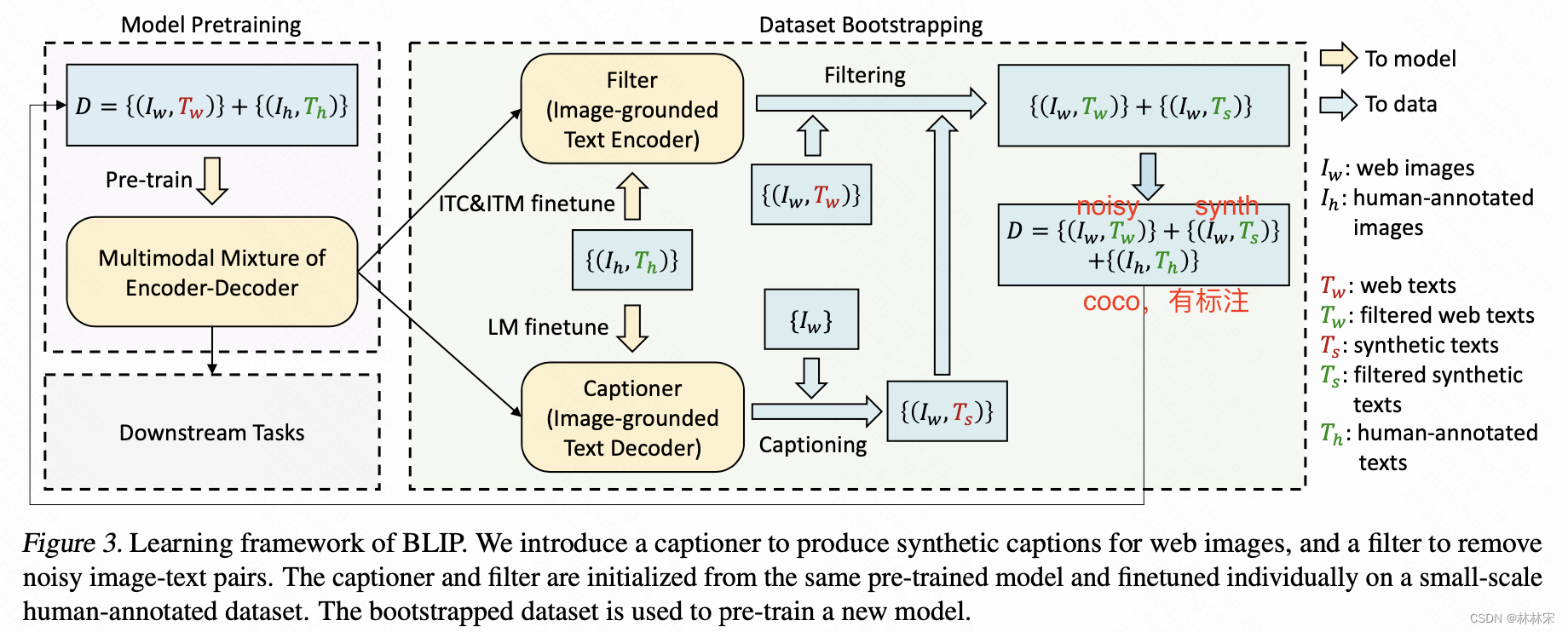
- 首先用noisy 数据+coco人工标注数据,训练BLIP对训练集重新生成caption,然后进行筛选【Iw,Tw】/【Iw, Ts】cosine similarity;
- 再次用筛选后的数据,包含(noisy,人工标注,生成数据),对decoder进行训练。
- caption生成的内容具有多样性,更有利于大模型(见更多分布的数据)
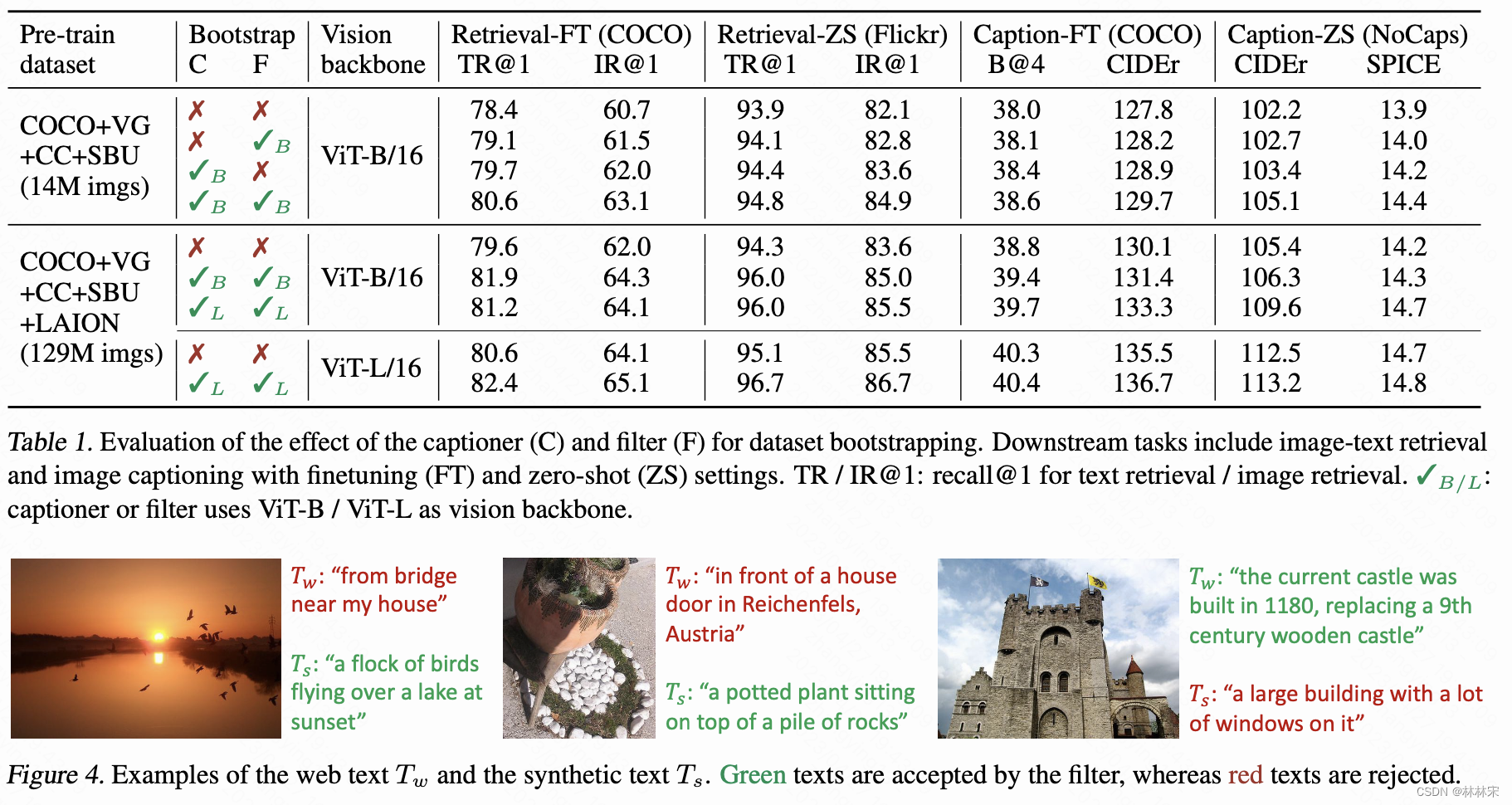
- 实验结果以及展示的case都证明了filter+caption方式的有效性。这是一种可以推广到所有同类任务的训练策略。
CoCa: Contrastive Captioners are Image-Text Foundation Models
-
google research
-
使用了非常大的数据集和模型参数量;没有开源代码实现
-
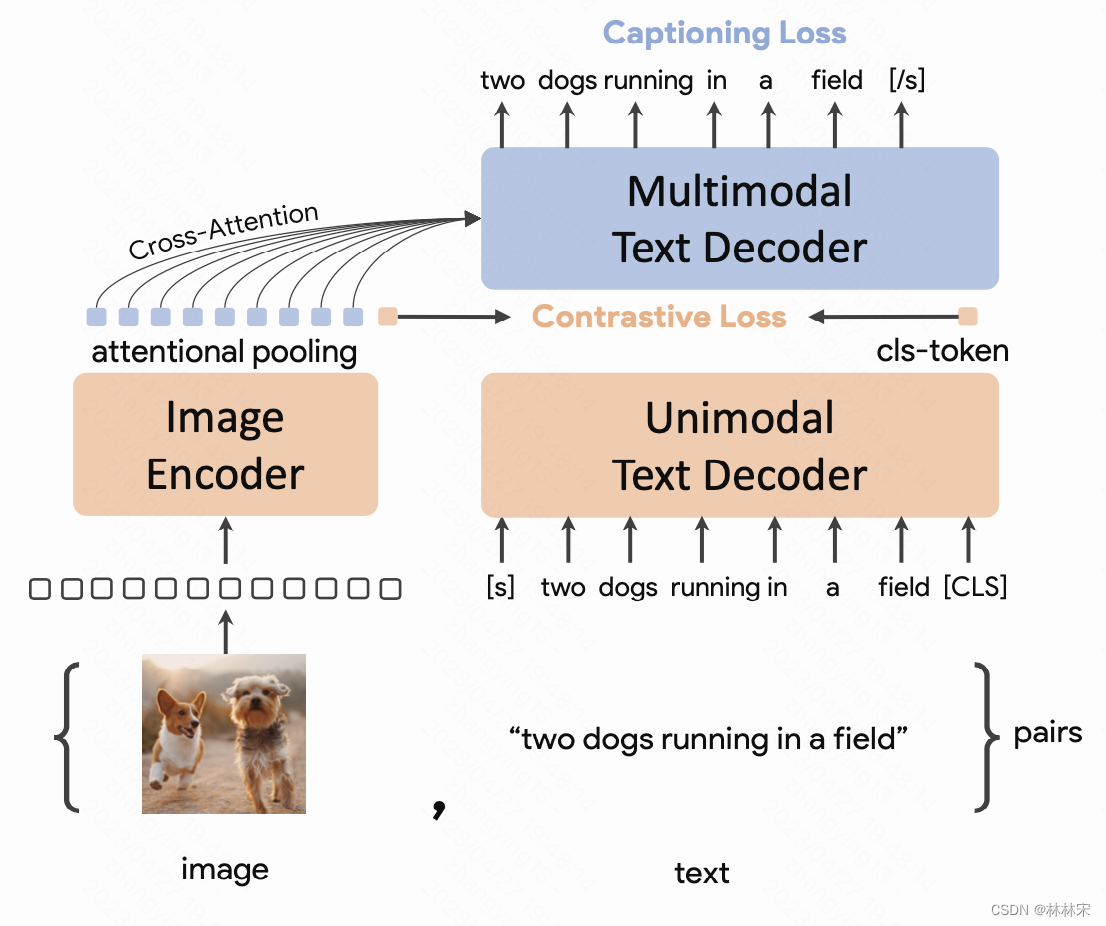
一个image encoder,两个text decoder;
-
只有ITC loss和captioning loss,因此一个iter只需要进行一次前向,训练速度大大加快。

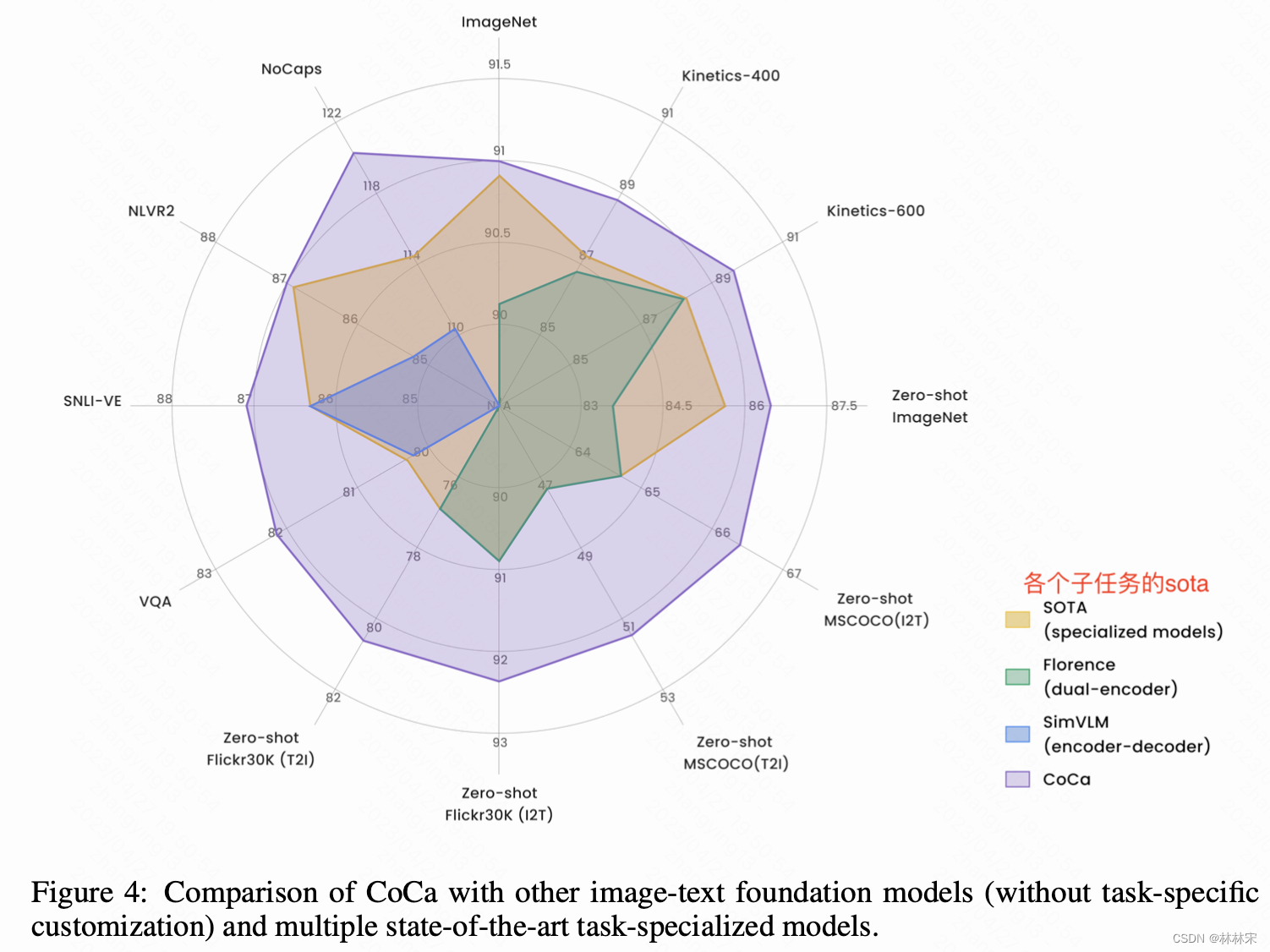
- 六边形战士图:和其他的模型在不同的任务对比,和当前各个子任务的sota对比,结果也都是更好的。
- 这个图非常直观,是当前多模态领域论文的很好表现形式,自己的工作总结也可以尝试借鉴。
BeiT V3–Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
-
microsoft
-
Wenhui Wang, Hangbo Bao,
-
motiovation:想要做一个大一统的模型,不仅能够处理不同的模态数据,更能用于各种下游任务。从结构,目标函数上实现一统,并且可以scale up到不同的模型尺寸以及数据量上。
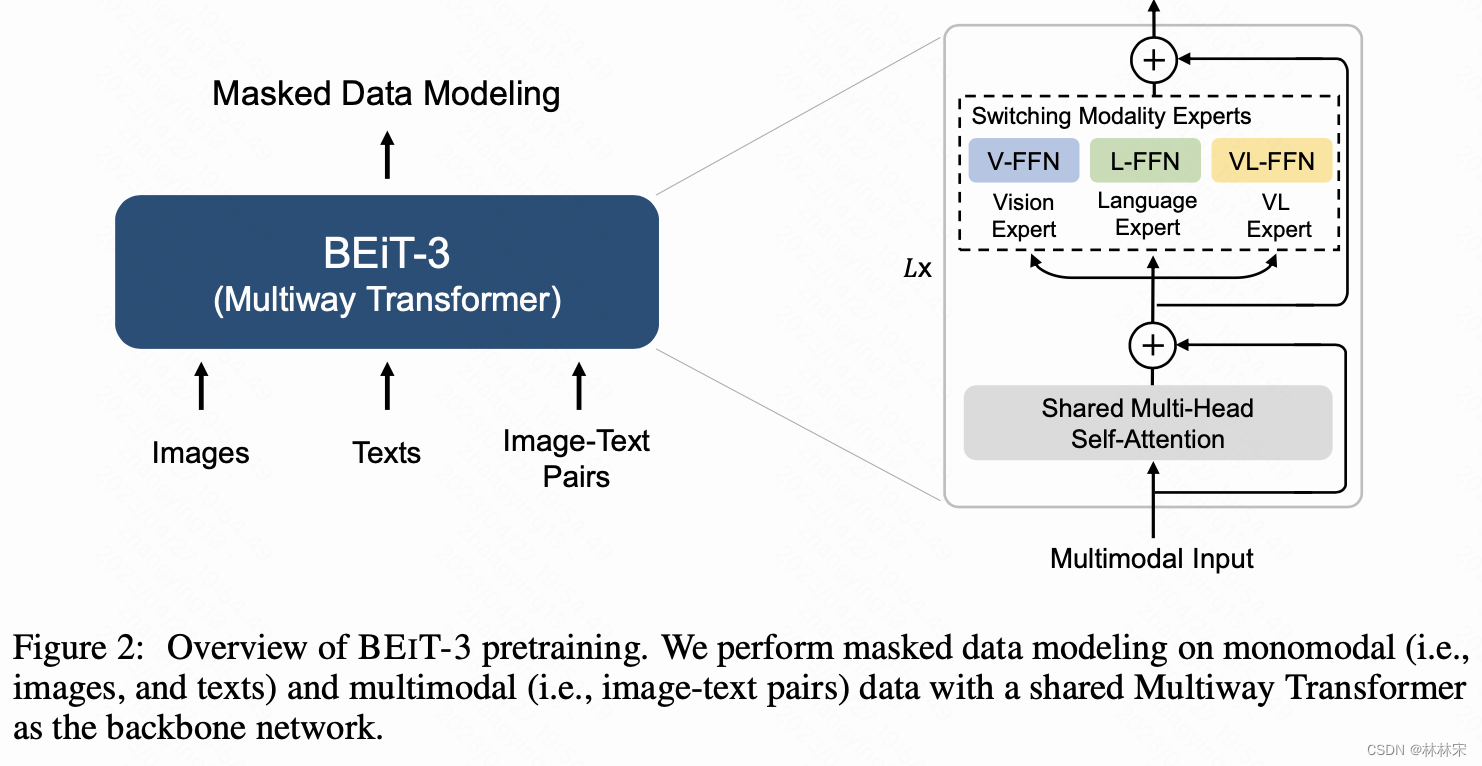
- 模型结构:VLMo结构的模型,multi-way transformer,因为transformer结构可以在各个模态的数据上都表现很好;
- 目标函数:仅使用masked modeling的方式,将图片也看作是language,可以基于【image language】 or 【text language】 or 【image-text pair(parallel sentences) 】,使用语言模型训练的方法