ViLT : Vision-and-Language Transformer Without Convolution or Region Supervision
- ViLT : Vision-and-Language Transformer Without Convolution or Region Supervision
- ALBEF: Vision and LanguageRepresentation Learning with Momentum Distillation
- Introduction
- VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
ViLT : Vision-and-Language Transformer Without Convolution or Region Supervision
Introduction
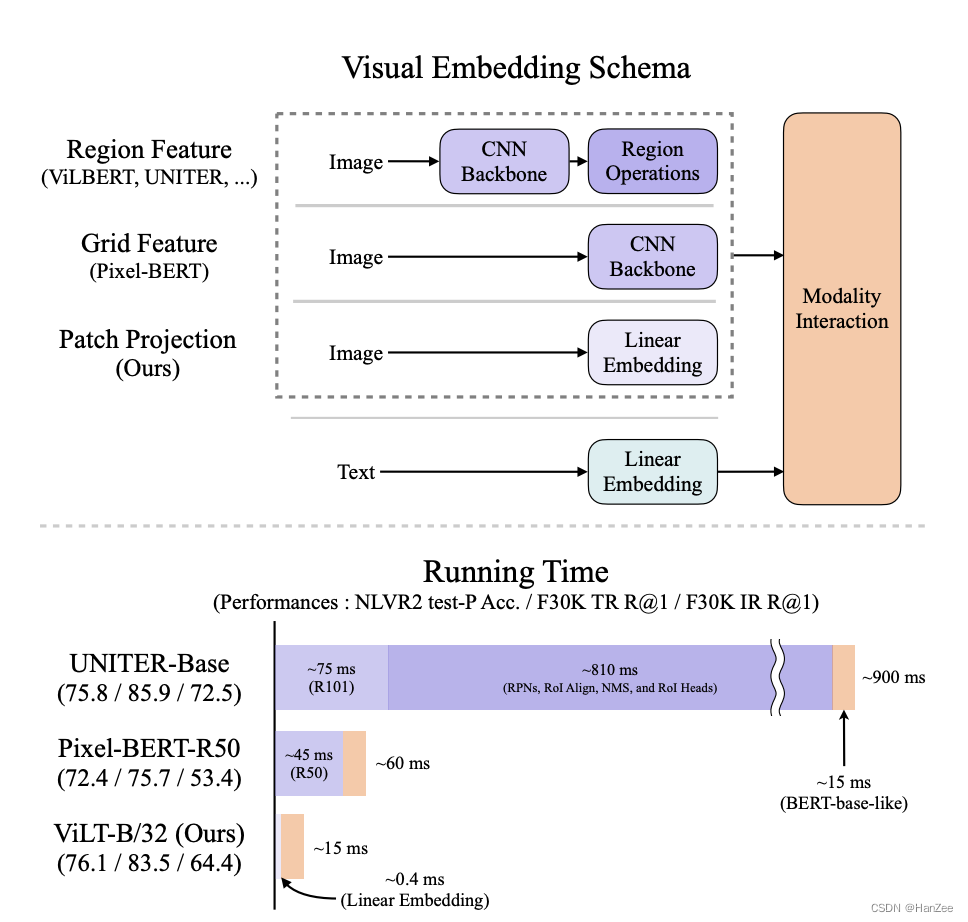
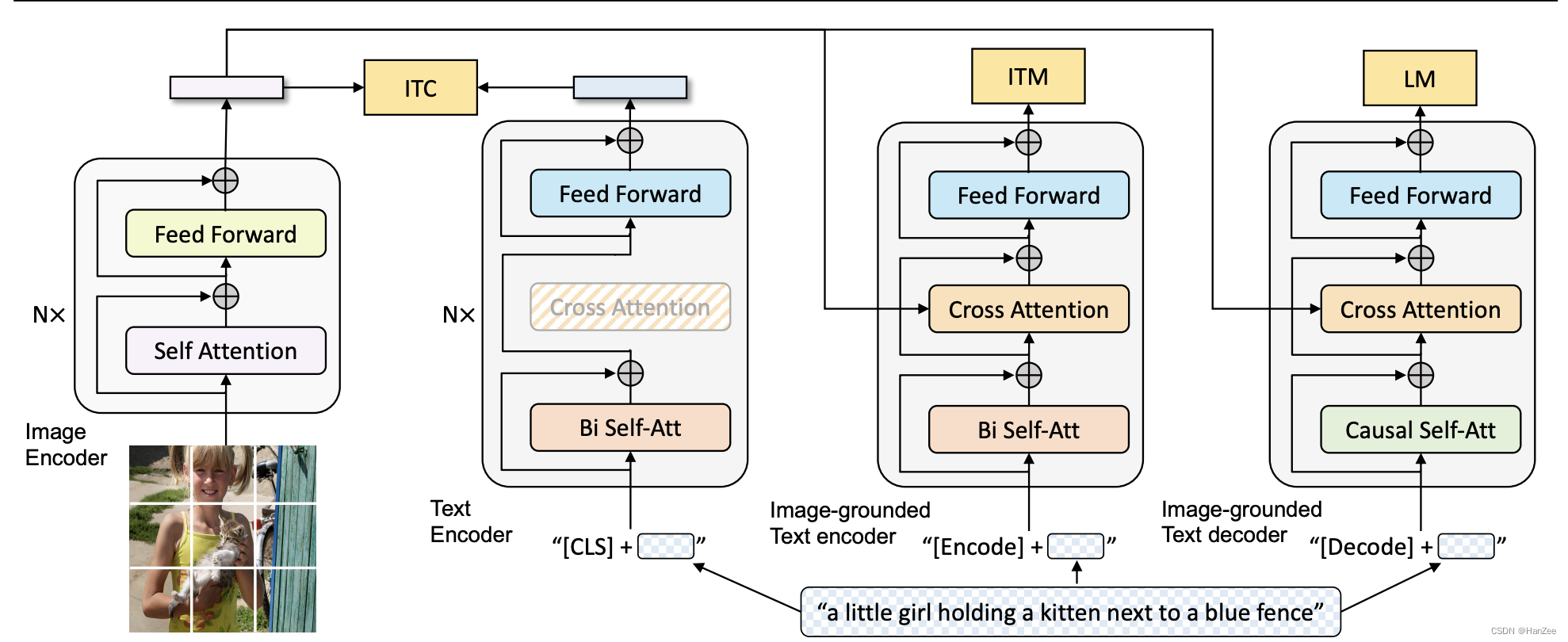
把多模态分为三部分,一部分提取图像特征,然后提取文本特征,然后融合二者。在当时多模态领域研究中,最常见的是通过CNN提取特征然后通过目标检测网络提取一些候选框的特征,作者指出这种方法时间很长,提出了ViLT,文本与图像分别只通过一个Linear Embedding(在当时VIT刚发布)就可以达到与前者类似的性能,并且时间大大减少了。
这篇文章的主要贡献是替换了臃肿的目标检测模块,改成了更为轻量的Patch Embedding 模块,验证了可行性,然后首次引入了图像数据增强。
Approach
网络结构如下:
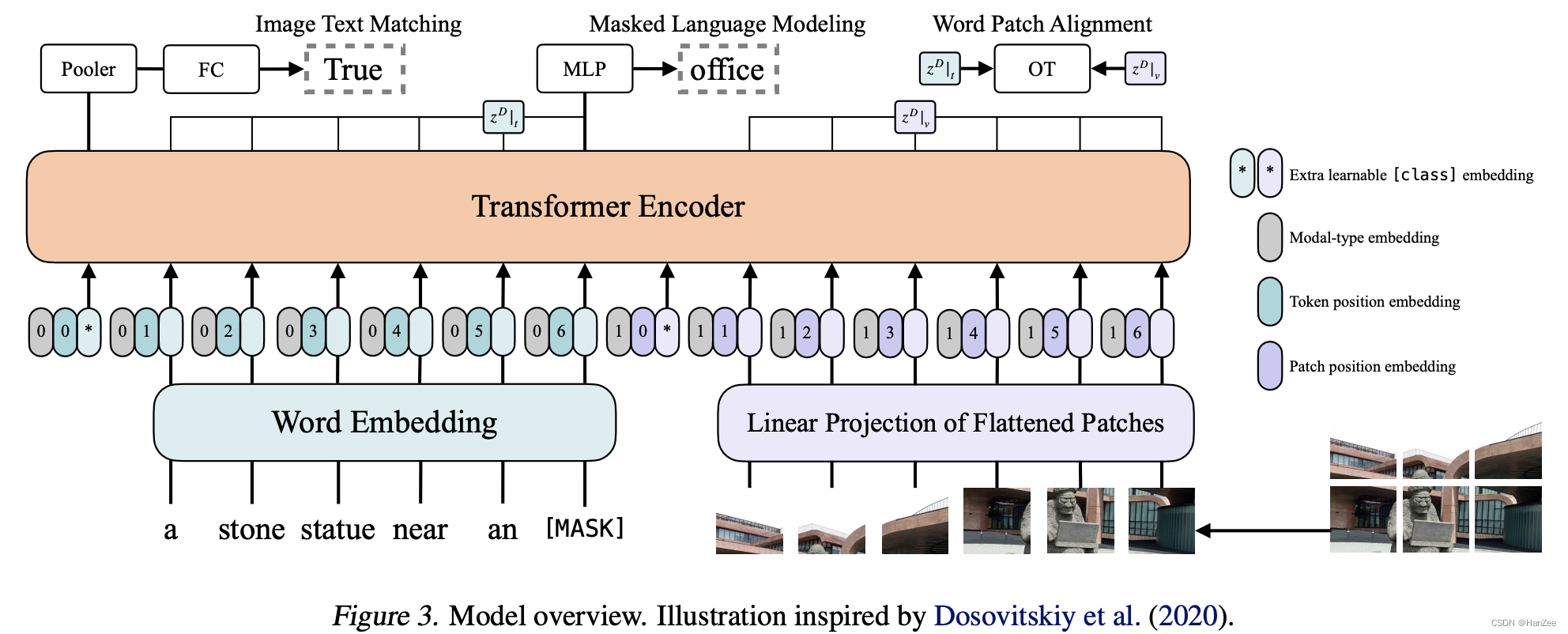
由于网络在后面研究中有很多模块被替换,就不再过多赘述。
参考
https://arxiv.org/pdf/2102.03334.pdf
ALBEF: Vision and LanguageRepresentation Learning with Momentum Distillation
Introduction
这篇文章与第一篇是同时期的文章,只差了一个月,所以作者认为用目标检测提取候选框的方法提取视觉特征,这种方法不能很好的与文本特征对齐,由于目标检测模型一般为pre-training model,文本输入与图像输入二者之间没有一个端到端对齐的过程。
所以作者提出了一个全新的Loss,可以使二者对齐并且可以去掉目标检测模块。
第二个问题是作者认为从互联网上爬去的图像文本对存在很多噪声,因为用来描述图像的文本,一般对搜索属性很友好,并不能很好的描述图像。
针对这个问题,作者提出了一个momentum model,去给数据打为标签,实现了一个半监督的过程。
根据上述改进,作者提出ALBEF,在VAQA与NLVR数据集上提高了2.3与3.84的表现,并且大大减少了训练时间。
Approach
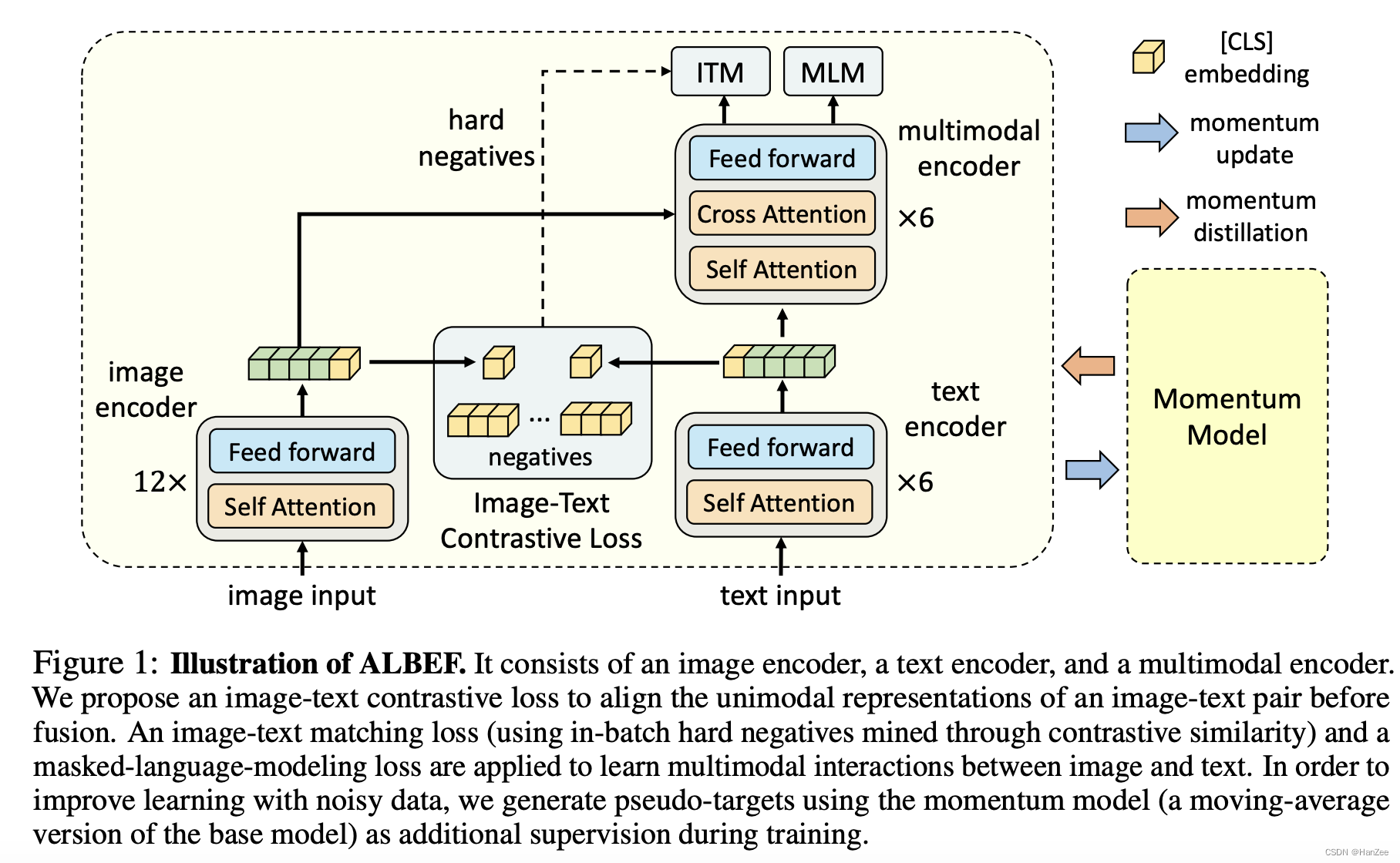
ALBEF的image input是一个VIT,text input是Bert的前6层,然后得到图像与文本的特征后,通过二者的cls token 进行ITC loss ,也就是clip的loss,在融合前尽可能让二者相接近。然后把二者的特征送入cross attention 做进一步的模态融合,计算两个loss,一个ITM,就是一个二分类问题,用来衡量图像图文本是否匹配(还从ITCloss中提取hard negative loss用来辅助)。第二个loss就是传统的MLM Loss,也就是Bert loss。
参考
https://arxiv.org/pdf/2107.07651.pdf
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
提出了新的模型结构:
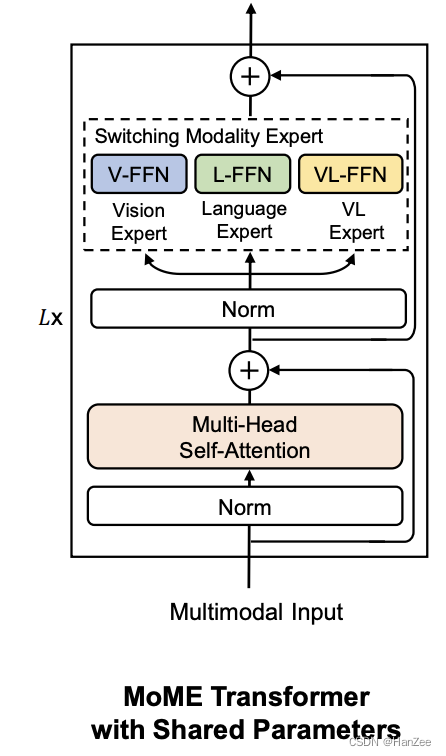
与新的训练方式
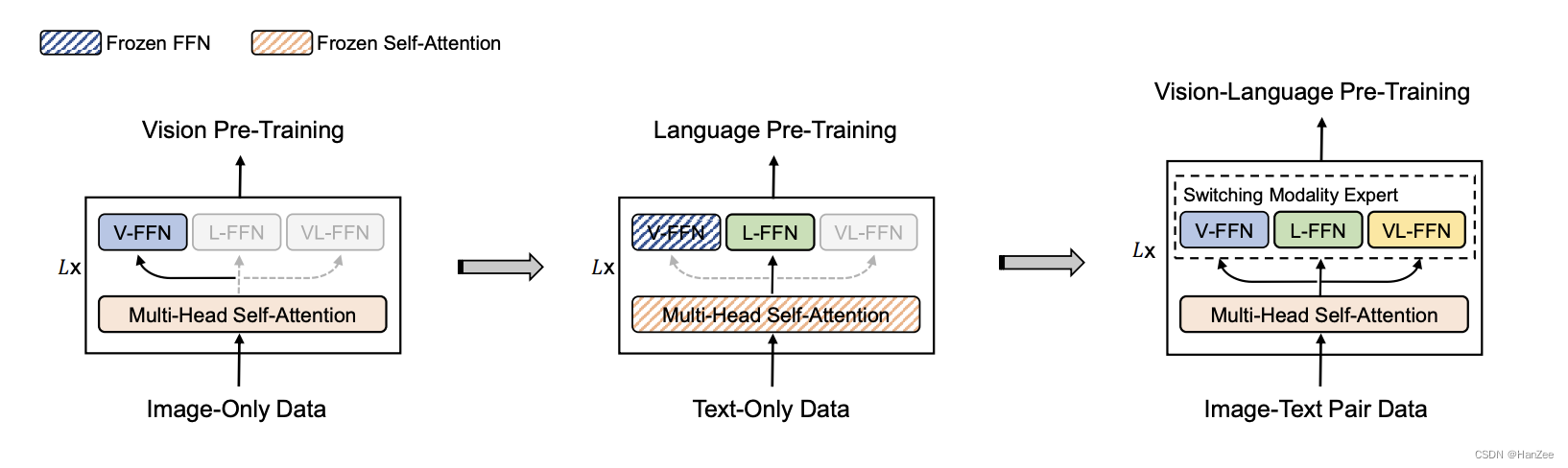
- 首先训练 视觉文本,只训练V-FFN与backbone,然后训练文本,只训练L-FFN,冻结V-FFN与backbone,然后在模态融合阶段,输入图像文本对,微调所有参数。
参考:https://arxiv.org/pdf/2111.02358.pdf
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
结合以前的工作提出了新的架构: