beit,beit2都还只是单模态的工作,到第三代变成了一个多模态的工作,半响不敢确认是不是beit3... 这篇工作还是能看到他们组其他工作的影子,beit系列自不必多说,还有vlmo等,可以算是一个集大成的工作。

六边形战士
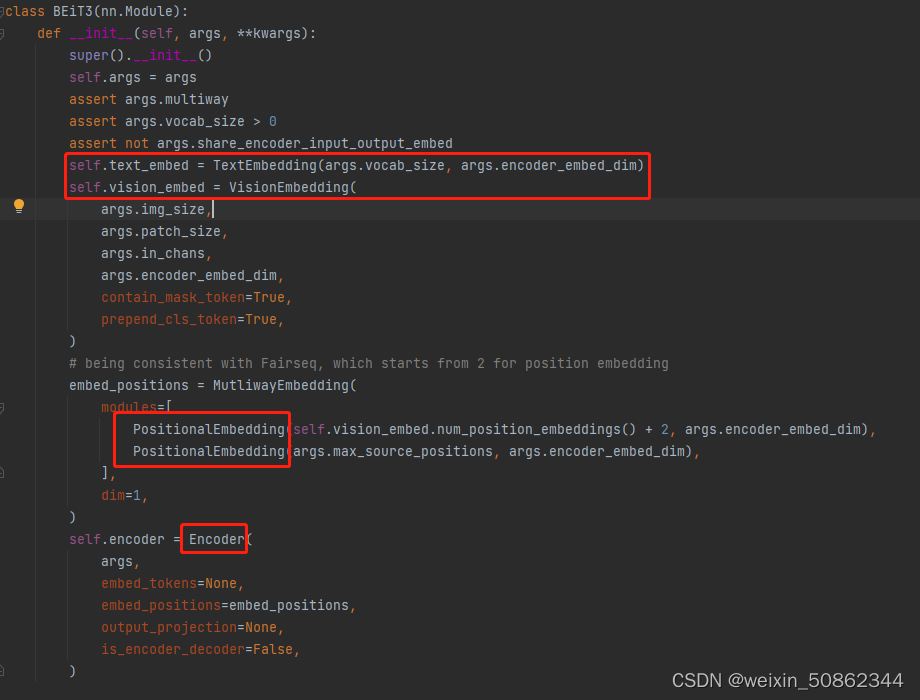
1. BEIT 3
1.1 基本骨架:Multiway Transformer
每一层都包含一个视觉专家和一个语言专家。
最后三层拥有为融合编码器设计的视觉语言专家。

1.2 预训练任务
区别与之前的工作舍弃了经典三样,训练任务只有一个:掩蔽数据建模 。(确实是很呼应标题了)
(1)文本数据
由SentencePiece tokenizer标记,随机屏蔽了15%
(2)图片数据
图像数据由BEIT v2的令牌化器进行令牌化,以获得离散视觉令牌作为重建目标,掩蔽40%的图像块。
(3)图像-文本对
随机屏蔽50%的文本标记,掩蔽40%的图像块。
2.代码
2.1 beit3
beit3最基础的代码在torchscale库中
from torchscale.model.BEiT3 import BEiT3