版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wwwhp/article/details/82113678
Abstract
- Yolo v3: an incremental improvement
- yolov3包含一堆小设计,可以使系统的性能得到更新;也包含一个新训练的、非常棒的神经网络,虽然比上一版更大一些,但精度也提高了。不用担心,虽然体量大了点,它的速度还是有保障的。在输入320×320的图片后,YOLOv3能在22ms内完成处理,并取得28.2mAP的成绩。它的精度和SSD相当,但速度要快上3倍。和旧版数据相比,v3版进步明显。在Titan X环境下,YOLOv3的检测精度为57.9AP5057.9AP50,用时51ms;而RetinaNet的精度只57.5AP5057.5AP50,但却需要198ms,相当于YOLOv3的3.8倍;
The Deal
- 在yolov3中,作者采用了其他论文中的方法,同时也训练了一个全新的/比其他网络更好的分类网络
Bounding Box Prediction
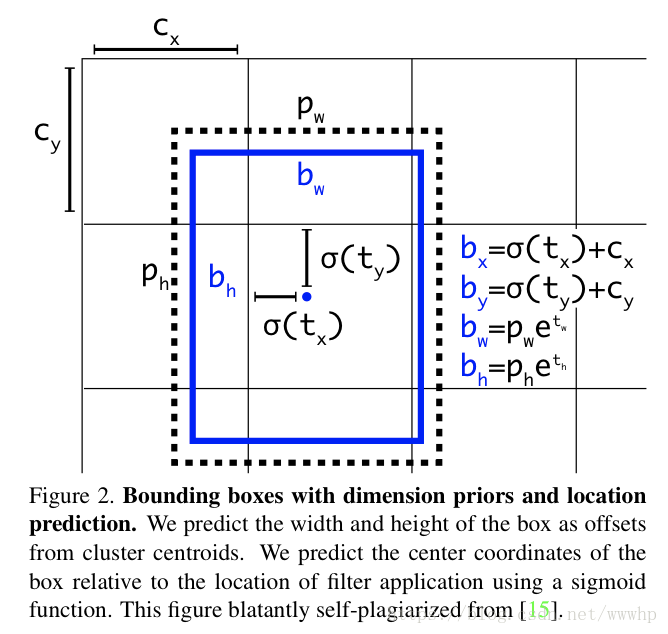
- 在yolov2/yolo9000之后,yolo系统开始利用dimensions clusters预测bounding box来作为anchor box,网络会为每一个bbox预测4个coordinate:tx/ty/tw/th,如果目标cell距离图像左上角的位移是(cx,cy),且对应的bbox prior的宽和高为pw/ph,则网络的预测值bx/by/bw/bh为:
- yolov3使用逻辑回归来预测每个边界框的objectness score。如果当前预测的边界框比之前的更好地与ground truth对象重合,分数为1。如果当前的预测不是最好的,但它和ground truth对象重合到了一定阈值以上,网络会忽视这个预测。文中阈值是0.5。其中系统只为每个ground truth对象分配一个边界框。如果一个bbox prior并未分配给相应对象,那它不会对坐标或分类预测造成loss,只对objectness造成影响;
Class Prediction
- 每个边界框都会使用多标记分类来预测框中可能包含的类。不使用softmax,而是用单独的逻辑分类器,因为我们发现前者对于提升网络性能没什么用。在训练过程中,用二元交叉熵损失来预测类别。 这个选择有助于我们把YOLO用于更复杂的领域,如Open Images Dataset 。这个数据集中包含了大量重叠的标签(如女性和人)。如果使用softmax,它会强加一个假设,使得每个框只包含一个类别。但通常情况下这样做是不妥的,多标记的分类方法能更好地模拟数据;
Prediction Across Scales And Feature Extractor
- yolov3预测3种不同尺寸的box,系统使用和特征金字塔类似的概念从这个尺寸中提取特征,在基本特征提取器中增加了几个卷积层,并用最后的卷积层预测一个三维张量编码bbox:边界框、框中目标和分类预测。在COCO数据集实验中,我们的神经网络分别为每种尺寸各预测了3个边界框,所以得到的张量是N*N*[3*(4+1+80)],其中包含4个边界框offset、1个目标预测以及80种分类预测;接着从前两个图层中得到特征图,并对它进行2次上采样。再从网络更早的图层中获得特征图,用element-wise把高低两种分辨率的特征图连接到一起。这样做能使我们找到早期特征映射中的上采样特征和细粒度特征,并获得更有意义的语义信息。之后,我们添加几个卷积层来处理这个特征映射组合,并最终预测出一个相似的、大小是原先两倍的张量;用同样的网络设计来预测边界框的最终尺寸,这个过程其实也有助于分类预测,因为我们可以从早期图像中筛选出更精细的特征。yolov3使用的prior box聚类方法和v2一样还是K-Means,它能用来确定边界框的先验。在实验中,我们选择了9个聚类和3个尺寸,然后在不同尺寸的边界框上均匀分割维度聚类。在COCO数据集上,这9个聚类分别是:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116 × 90)、(156 × 198)、(373 × 326);
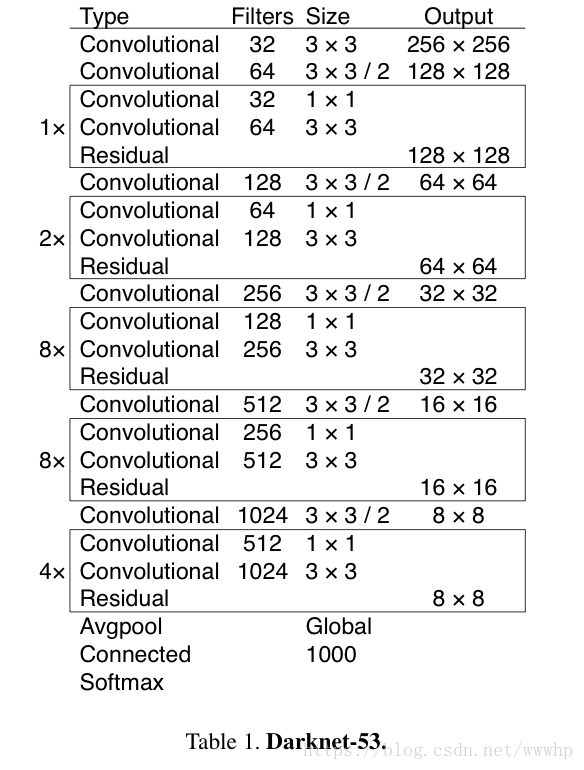
- yolov3用了一个新的网络来提取特征,它融合了YOLOv2、Darknet-19以及其他新型残差网络,由连续的3×3和1×1卷积层组合而成,当然,其中也添加了一些shortcut connection,整体体量也更大。因为一共有53个卷积层,称为Darknet-53
- Darknet-53在精度上可以与最先进的分类器相比,同时浮点数运算更少,速度更快,它可以实现每秒最高的测量浮点运算,可以更好地利用GPU;
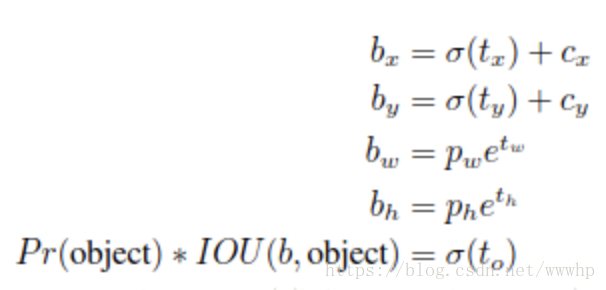
How We Do
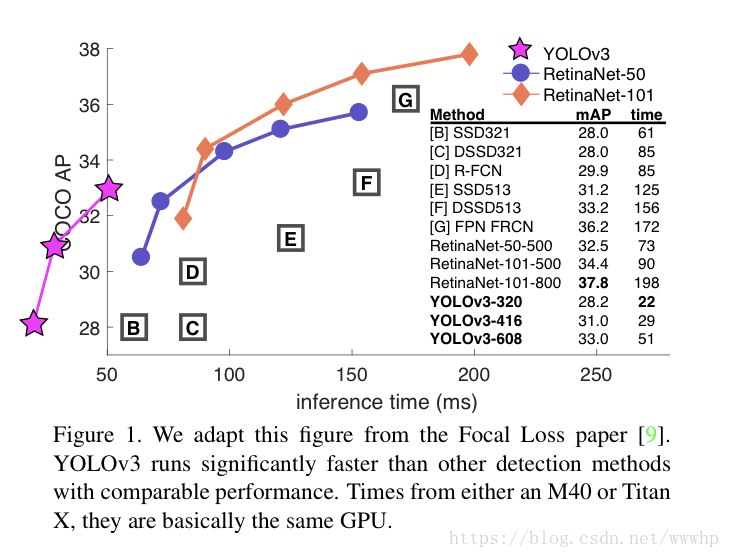
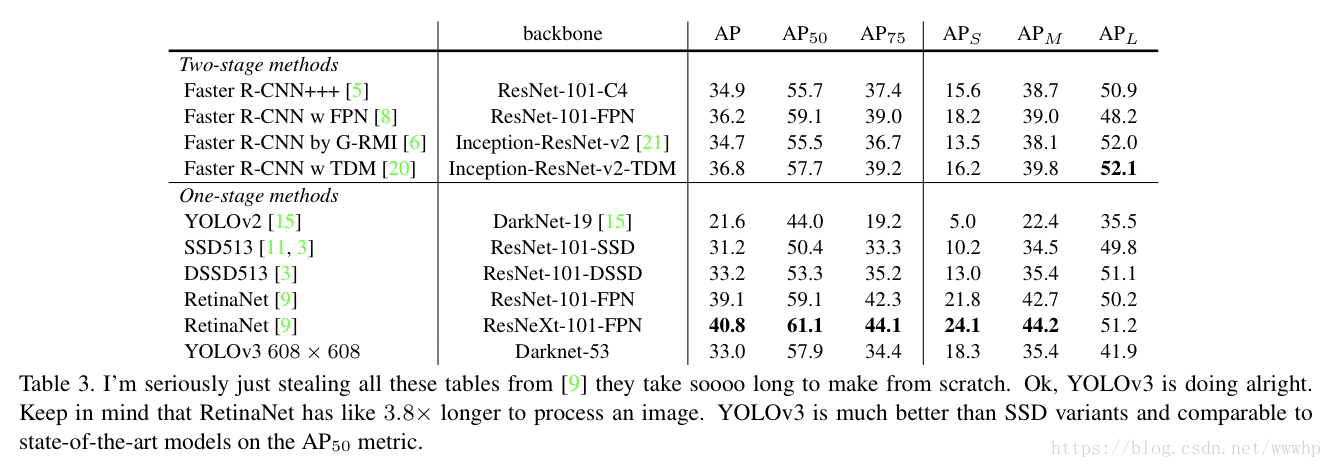
在IOU=0.5(即AP50)时,yolov3非常强大。它几乎与RetinaNet相当,并且远高于SSD variants。这就证明了它其实是一款非常灵活的检测器,擅长为检测对象生成合适的边界框。然而,随着IOU阈值增加,yolov3的性能开始同步下降,这时它预测的边界框就不能做到完美对齐了;但现在我们可以预见其中的演变趋势,随着新的多尺寸预测功能上线,yolov3将具备更高的APS性能,但是它目前在中等尺寸或大尺寸物体上的表现还相对较差,仍需进一步的完善。 当基于AP50指标绘制精度和速度时,我们发现YOLOv3与其他检测系统相比具有显着优势即它的速度正在越来越快。
Network Structor Analyze
#include <iostream> --------------------------------------------- darknet yolov layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs 1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs 2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs 3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs 4 res 1 208 x 208 x 64 -> 208 x 208 x 64 5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs 6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs 7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 8 res 5 104 x 104 x 128 -> 104 x 104 x 128 9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs 10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 11 res 8 104 x 104 x 128 -> 104 x 104 x 128 12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BFLOPs 13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 15 res 12 52 x 52 x 256 -> 52 x 52 x 256 16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 18 res 15 52 x 52 x 256 -> 52 x 52 x 256 19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 21 res 18 52 x 52 x 256 -> 52 x 52 x 256 22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 24 res 21 52 x 52 x 256 -> 52 x 52 x 256 25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 27 res 24 52 x 52 x 256 -> 52 x 52 x 256 28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 30 res 27 52 x 52 x 256 -> 52 x 52 x 256 31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 33 res 30 52 x 52 x 256 -> 52 x 52 x 256 34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 36 res 33 52 x 52 x 256 -> 52 x 52 x 256 37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512 1.595 BFLOPs 38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 40 res 37 26 x 26 x 512 -> 26 x 26 x 512 41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 43 res 40 26 x 26 x 512 -> 26 x 26 x 512 44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 46 res 43 26 x 26 x 512 -> 26 x 26 x 512 47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 49 res 46 26 x 26 x 512 -> 26 x 26 x 512 50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 52 res 49 26 x 26 x 512 -> 26 x 26 x 512 53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 55 res 52 26 x 26 x 512 -> 26 x 26 x 512 56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 58 res 55 26 x 26 x 512 -> 26 x 26 x 512 59 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 60 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 61 res 58 26 x 26 x 512 -> 26 x 26 x 512 62 conv 1024 3 x 3 / 2 26 x 26 x 512 -> 13 x 13 x1024 1.595 BFLOPs 63 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 64 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 65 res 62 13 x 13 x1024 -> 13 x 13 x1024 66 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 67 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 68 res 65 13 x 13 x1024 -> 13 x 13 x1024 69 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 70 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 71 res 68 13 x 13 x1024 -> 13 x 13 x1024 72 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 73 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 74 res 71 13 x 13 x1024 -> 13 x 13 x1024 75 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 76 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 77 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 78 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 79 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 81 conv 75 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 75 0.026 BFLOPs 82 yolo 83 route 79 84 conv 256 1 x 1 / 1 13 x 13 x 512 -> 13 x 13 x 256 0.044 BFLOPs 85 upsample 2x 13 x 13 x 256 -> 26 x 26 x 256 86 route 85 61 87 conv 256 1 x 1 / 1 26 x 26 x 768 -> 26 x 26 x 256 0.266 BFLOPs 88 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 89 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 90 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 91 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 93 conv 75 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 75 0.052 BFLOPs 94 yolo 95 route 91 96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BFLOPs 97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 128 98 route 97 36 99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOPs 100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 105 conv 75 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 75 0.104 BFLOPs 106 yoloconv:
- layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
输入层:
- 输入:像素为416*416,通道数为3的的图片(开启random参数的话可以自适应以32为基础的变化)
- BN操作:对输入进行BN操作(这里未显示)。
- 卷积操作:32层卷积核(filters),每个卷积核大小为3*3,步伐为1(每个卷积窗口逐步进行卷积)
- 输出:32个通道的416*416大小的feature map
res(shortcut操作):
- layer filters size input output
4 res 1 208 x 208 x 64 -> 208 x 208 x 64
res层:
- 输入与输出:输入与输出一般保持一致,并且不进行其他操作,只是求差。
- 处理操作:res层来源于resnet,为了解决网络的梯度弥散或者梯度爆炸的现象,提出将深层神经网络的逐层训练改为逐阶段训练,将深层神经网络分为若干个子段,每个小段包含比较浅的网络层数,然后用shortcut的连接方式使得每个小段对于残差进行训练,每一个小段学习总差(总的损失)的一部分,最终达到总体较小的loss,同时,很好的控制梯度的传播,避免出现梯度消失或者爆炸等不利于训练的情形。
darknet-53:
- 从第0层一直到74层,一共有53个卷积层,其余为res层。这就是Joseph Redmon大神提出的darknet-53经典的卷积层了。作为yolov3特征提取的主要网络结构。预训练(以imagenet数据集为训练基础)的权重文件可以通过官网下载。该结构使用一系列的3*3和1*1的卷积的卷积层。这些卷积层是从各个主流网络结构选取性能比较好的卷积层进行整合得到。它比darknet-19效果好很多,同时,它在效果更好的情况下,是resnet-101效率的1.5倍,几乎与resnet-152的效果相同的情况下,保持2倍于resnet-152的效率。
yolo layer
从75到105层我为yolo网络的特征交互层,分为三个尺度,每个尺度内,通过卷积核的方式实现局部的特征交互,作用类似于全连接层但是是通过卷积核(3*3和1*1)的方式实现feature map之间的局部特征(fc层实现的是全局的特征交互)交互。
- 最小尺度yolo层:
- 输入:13*13的feature map ,一共1024个通道。
- 操作:一系列的卷积操作,feature map的大小不变,但是通道数最后减少为75个。
- 输出;输出13*13大小的feature map,75个通道,在此基础上进行分类和位置回归。
中尺度yolo层:
- 输入:将79层的13*13、512通道的feature map进行卷积操作,生成13*13、256通道的feature map,然后进行上采样,生成26*26、256通道的feature map,同时于61层的26*26、512通道的中尺度的feature map合并。再进行一系列卷积操作,
- 操作:一系列的卷积操作,feature map的大小不变,但是通道数最后减少为75个。
- 输出:26*26大小的feature map,75个通道,然后在此进行分类和位置回归。
大尺度的yolo层:
- 输入:将91层的26*26、256通道的feature map进行卷积操作,生成26*26、128通道的feature map,然后进行上采样生成52*52、128通道的feature map,同时于36层的52*52、256通道的中尺度的feature map合并。再进行一系列卷积操作,
- 操作:一系列的卷积操作,feature map的大小不变,但是通道数最后减少为75个。
- 输出:52*52大小的feature map,75个通道,然后在此进行分类和位置回归。
Related Source
Thanks