目录
-
论文解读
-
代码解析
-
小结
论文解读
在介绍inception V2时提到过,inception V3的论文依据是Rethinking the Inception Architecture for Computer Vision 虽然此文中介绍的网络结构叫做inception V2,但是在代码的实现中却是叫做inception V3。可能google在实现代码的时候觉得可以把加了BN的网络称为inception V2,那这篇论文的实现就更名为inception V3了。
1.前言
近几年分类网络精确度的提升对其他相关的机器视觉应用有很大的帮助,比如人脸识别,物体检测之类,因为他们都可以用分类网络来提取特征。Inception网络相对AlexNet和VGG来说不仅精确度有了提升,而且参数量大大减少,所以inception网络可以应用在有大量数据的场景,因为在大量数据的场景我们需要合理分配有限的计算和存储资源。但是现在inception网络的结构比较难以修改,如果我们需要放大网络,可能网络中部分信息是失效的,这样很难适应新的场景。因此本文主要是介绍一些通用的规则和一些优化的思想,让我们能够比较灵活的修改网络来适应不同的场景。
2.基本设计原理
- 避免在网络的前面使用像bottleneck的结构。就是说size需要缓慢的降低,不能一开始降低的太快,这样会丢失很多信息。
- 对高维度的表达进行局部处理,会加快网络的训练速度。
- 在较低维度的输入上进行空间聚合,将不会造成任何表达能力上的损失,因为feature map上,临近区域上的表达具有很高的相关性,如果对输出进行空间聚合,那么将feature map的维度降低也不会减少表达的信息。这样的话,有利于信息的压缩,并加快了训练的速度。
- 平衡网络的宽度和深度。增加网络的宽度和深度对网络的精确度提升都有帮助,但是如果同时增加宽度和深度,计算量会增大,因此在有限的计算资源下,应该平衡网络的宽度和深度。
3.分解卷积中大size的filter
1.用更小size的filter
用大size的filter对计算资源消耗比较大,比如用5x5的filter相比用3x3的filter需要25/9倍的计算消耗。当然5x5的filter确实能够带来更多的信息,于是我们考虑用两个3x3的filter替代5x5的filter,如下图:

可以计算出改进后计算量是之前的(9+9)/25,计算量节省了28%.
如果在第一个3 x 3Convolution后使用线性激活,第二个3 x 3Convolution后使用Relu,应该和使用一个5 x 5 Convolution+Relu的效果一样。但是作者实验发现,在第一个3 x 3Convolution后使用Relu激活精确度会有提升。所以使用两个3 x 3Convolution并且每次Convolution后进行Relu激活不仅节省了计算量而且精确度还能有轻微的提升。
2.使用非对称的filter
使用大于3 x 3的convolution不如分解成一系列的3 x 3Convolution效果更好。那是否能用更小的filter呢,比如2 x 2。但是作者想到了使用非对称的filter,比如一个1 x 3后面跟着一个3 x 1,这样相比3x3的filter计算量减少了1-(3+3)/3*3=33%,而使用2x2的filter计算量会减少1-(2*2+2*2)/3*3=11%,所以使用非对称的filter会更优。
我们会想到是否需要将所有的 x
的filter都改成1 x
和
x 1呢?作者试验下来发现这样得分解在网络前面几层效果不好,而且只对比较中间尺寸的feature map效果好(feature map
x
, m在12到20之间),作者发现分解7 x 7为1 x 7和7 x 1是比较合适的。
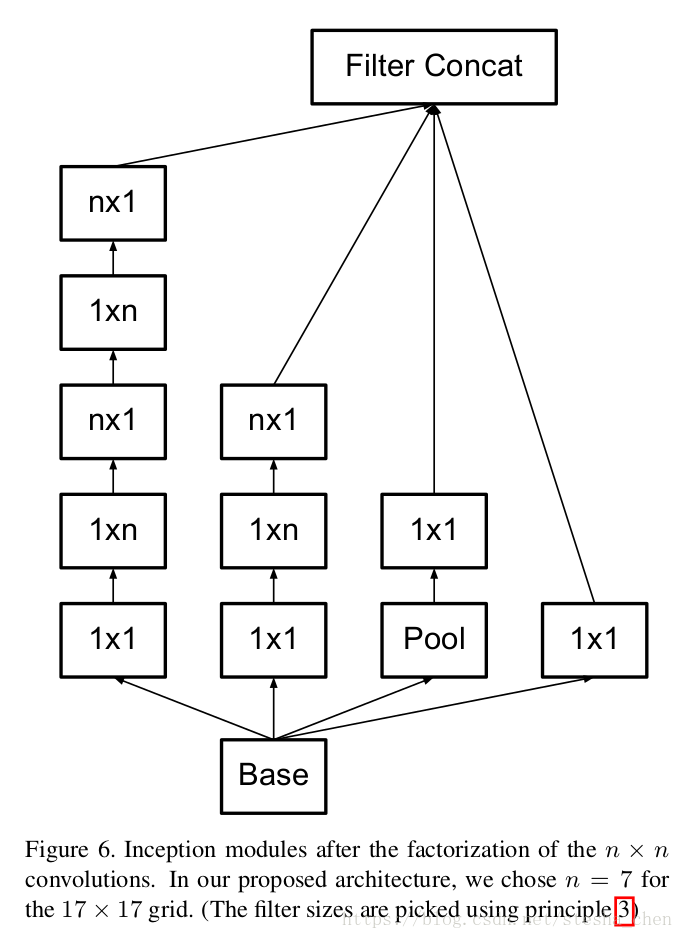
4.辅助分类器
在GoogleLeNet的论文中作者认为增加辅助的分类器对精确度有帮助,但是在此文作者发现移除辅助分类器对精确度没有影响,只有当辅助分类器中增加BN或者dropout时有一些帮助,所以辅助分类器只能起到正则化的效果。
5.有效的缩减grid size
如果我们有一个feature map为要缩减size增加channel为
,按照以前的操作有以下两种方法。右边的方法是先利用convolution计算升channel,在利用pooling降feature map 尺寸,计算量为
,不可取的原因是计算量太大。左边的方法是先用pooling降feature map尺寸,然后用convolution计算升channel,计算量为
。左边结构的计算量比右边减少了3/4,但是左边的结构违背了前面提到的准则1.
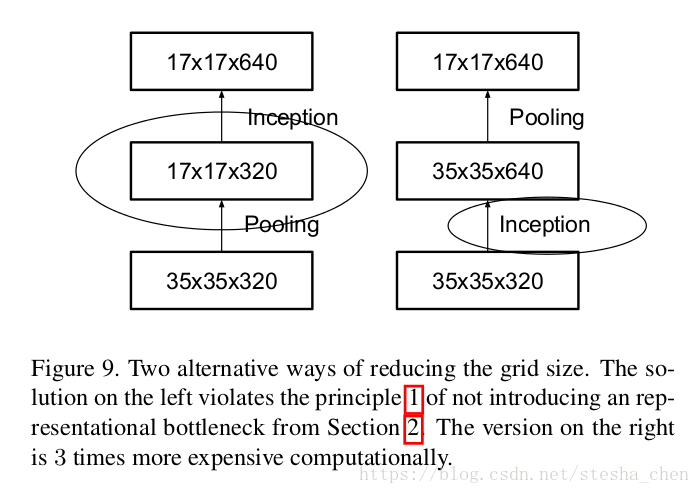
所以作者按照下图的结构进行改进,其实inception v2的代码中已经使用了这种方法进行feature map size缩减。
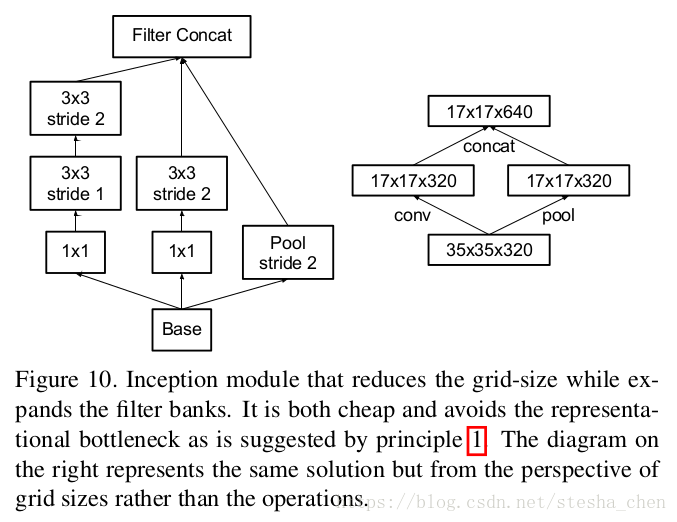
6.Inception-V2
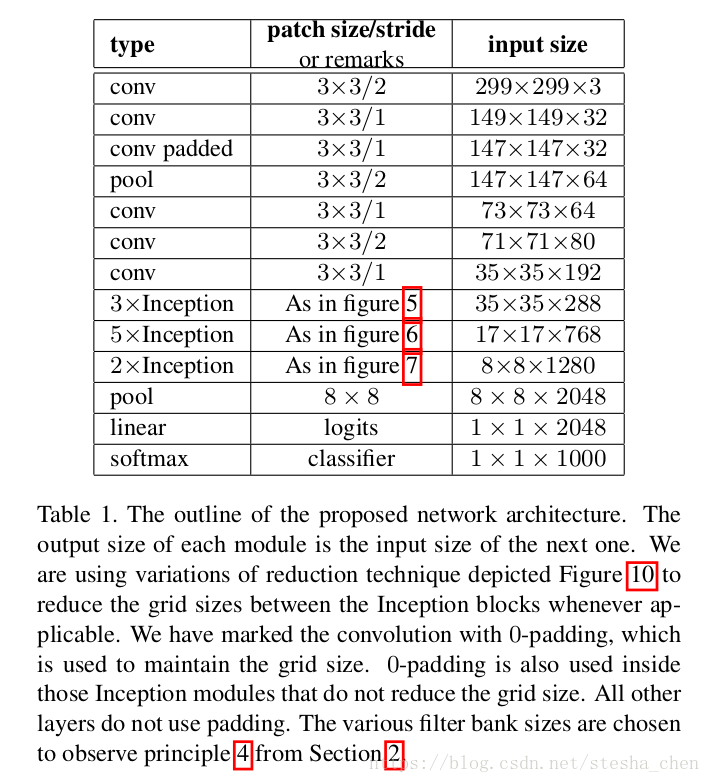
论文中叫做V2,代码实现叫做V3。下表格是v3网络的结构,可以看到input size改为299 x 299 x 3了,有些Inception block会重复使用。后面代码分析中会更细节的分析网络结构。
7.对于小尺寸图片网络的改进
- 对于299x299的图片,在第一层使用stride为2的conv,后面跟着一个maxpooling
- 对于151x151的图片,在第一层使用stride为1的conv,后面跟着一个maxpooling
- 对于79x79的图片,在第一层使用stride为1的conv,后面不需要maxpooling
代码解析
网络结构
下图为根据代码画出来的网络结构图,input为299 x 299 x 3,忽略了代码中的辅助分类器softmax。
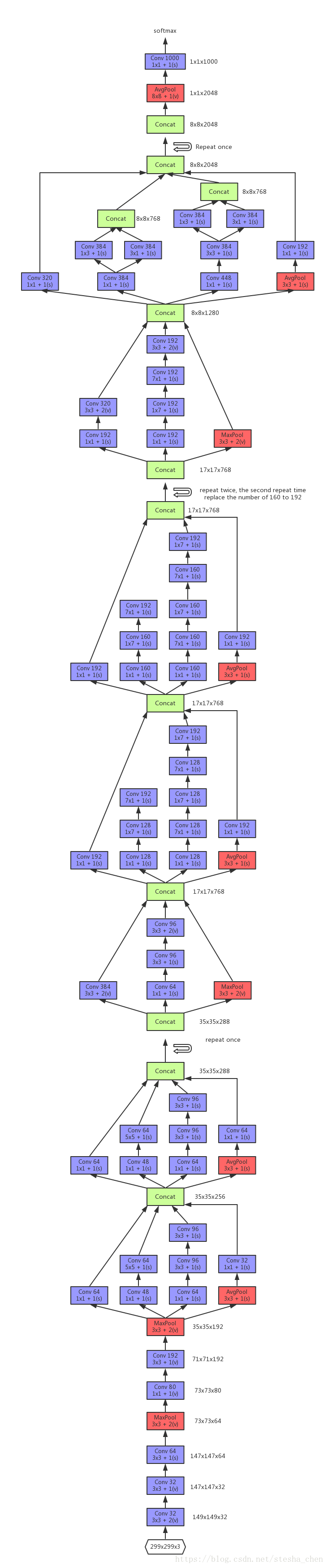
代码细节
1. 关于BN的实现,是在inception_v3_arg_scope = inception_utils.inception_arg_scope中设置默认值
2. create_aux_logits是关于辅助分类器的实现,代码中可以看到是从Mixed_6e中拉出来的辅助分类器。
3. 在最后一层Convolution之前有一个dropout。
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')小结
Inception V3将inception的结构发挥到了极致,包括:
- 用小size filter替代大size filter
- 用非对称的filter
- 用inception block中最后一层stride设置为2来实现feature map size缩减
后面提出的inception v4基本也是遵循这些原则,不过在inception v4的论文中结合了resnet的结构,有是对inception block的改进,后面再继续解读。