
Deeplab v3是v2版本的进一步升级,作者们在对空洞卷积重新思考的基础上,进一步对Deeplab系列的基本框架进行了优化,去掉了v1和v2版本中一直坚持的CRF后处理模块,升级了主干网络和ASPP模块,使得网络能够更好地处理语义分割中的多尺度问题。提出Deeplab v3的论文为Rethinking Atrous Convolution for Semantic Image Segmentation,是Deeplab系列后期网络的代表模型。
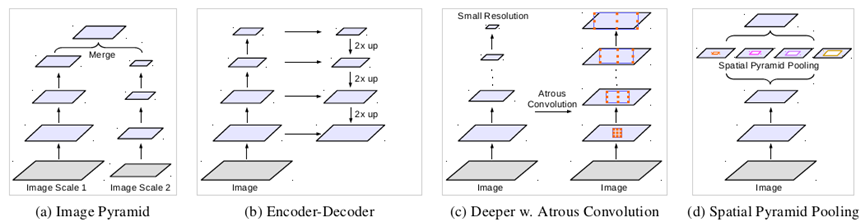
随着语义分割的发展,逐渐有两大问题亟待解决:一个是连续的池化和卷积步长导致的下采样图像信息丢失问题,这个问题已经通过空洞卷积扩大感受野得到比较好的处理;另外一个则是多尺度和利用上下文信息问题。论文中分别回顾了四种基于多尺度和上下文信息进行语义分割的方法,如图1所示,包括图像金字塔、编解码架构、深度空洞卷积网络以及空间金字塔池化,这四种方法各有优缺点,ASPP可以算是深度空洞卷积和空间金字塔池化的一种结合,Deeplab v3在v2的ASPP基础上,进一步探索了空洞卷积在多尺度和上下文信息中的作用。
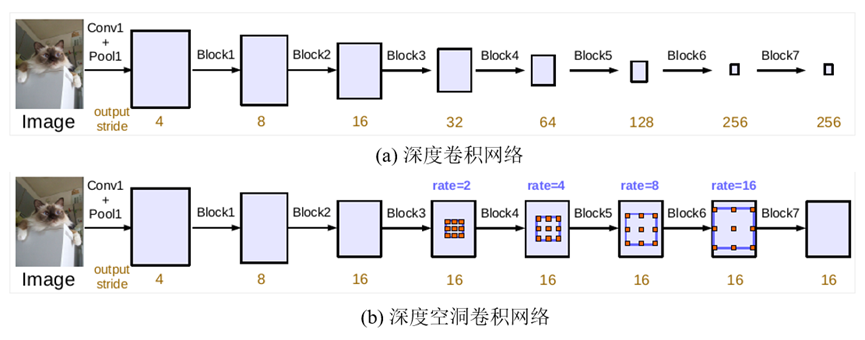
Deeplab v3可作为通用框架融入到任意网络结构中,具体地,以串行方式设计空洞卷积模块,复制ResNet的最后一个卷积块,并将复制后的卷积块以串行方式进行级联,如图2所示。
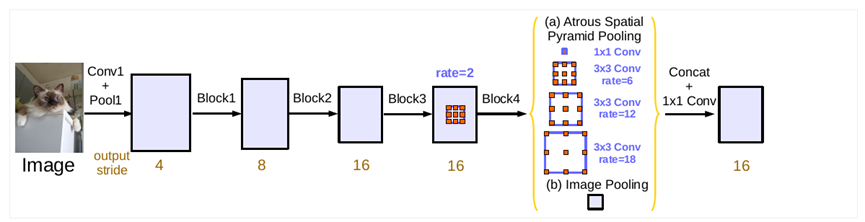
在卷积块串行级联基础上,Deeplab v3又对ASPP模块进行并行级联,v3对ASPP模块进行了升级,相较于v2版本加入了批归一化(Batch Normalization,BN),通过组织不同的空洞扩张率的卷积块,同时加入图像级特征,能够更好地捕捉多尺度上下文信息,并且也能够更容易训练,如图3所示。
总结来看,Deeplab v3更充分的利用了空洞卷积来获取大范围的图像上下文信息。具体包括:多尺度信息编码、带有逐步翻倍的空洞扩张率的级联模块以及带有图像级特征的ASPP模块。实验结果表明,该模型在 PASCAL VOC数据集上相较于v2版本有了显著进步,取得了当时SOTA精度水平。
Deeplab v3的PyTorch实现可参考:
https://github.com/pytorch/vision/blob/main/torchvision/models/segmentation/deeplabv3.py
往期精彩: