1.介绍
1.1 视觉语言(VL)预训练的两种主流架构
(1)dual-encoder:分别对图像和文本进行编码
优点:检索任务
缺点:图像和文本之间的浅层交互不足以处理复杂的VL分类任务
(2)单编码器:对模型图像-文本对进行跨模态关注的融合编码器
优点:在VL分类任务上实现了卓越的性能
缺点:需要对所有可能的图像文本进行联合编码,大数据集下的不适合检索任务
1.2 VLMO论文介绍
提出了一种统一的视觉语言预训练模型(VLMO),该模型既可以用作双编码器,对检索任务的图像和文本进行单独编码,也可以用作融合编码器,对分类任务的图像-文本对的深度交互进行建模。
1.3贡献
除了VLMO本身,个人认为本篇论文比较大的两个贡献是:
(1)多模式转换器 SA共享,只依靠FFN调整
(2)分阶段的训练策略:先训练单一模态,最后训练多模态
2. 方法

2.1 输入表示
2.1.1 图像表示
图像表示=补丁嵌入、可学习的1D位置嵌入和图像类型嵌入(其实就是用vit输出的feature表示)
2.1.2 文本表示
- 增加序列开始标记([T_CLS])和特殊边界标记([T_SEP])
文本表示=单词嵌入、文本位置嵌入和文本类型嵌入
2.1.3 文本图片表示
将图像和文本输入向量连接起来
2.2 Mixture-of-Modality-Experts Transformer (MOME)
- MOME Transformer引入了模态专家的混合,以替代标准Transformer的前馈网络。
- 每个MOME Transformer块通过切换到不同的模态专家来捕获模态特定信息,并使用模态之间共享的多头自注意(MSA)来对齐视觉和语言内容。
其实看下图就很容易理解了。三个模态共享多头自注意力(MSA),但是使用独立的FFN用来捕获不同模态下的信息。这个思想后面也被许多工作借鉴和学习

2.3 训练目标
经典老三样:①ITC图像-文本对比学习 ②MLM掩蔽语言建模 ③ITM图像-文本匹配 。
提出了全局hard negatives挖掘,并从所有GPU收集道德的更多训练示例中的hard negative图像-文本对进行采样。区别于ALBEF的单个gpu

2.4 分阶段预训练
首先对纯图像数据进行视觉预训练,然后对纯文本数据进行语言预训练,以学习一般的图像和文本表示
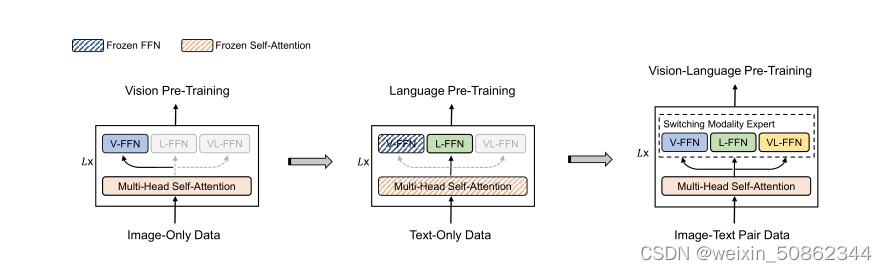
- 纯图像数据:预训练视觉专家(V-FFN)和自注意模块
- 纯文本数据:冻结视觉专家和自注意模块的参数,训练语言专家 (L-FFN)。
- 图像-文本数据:对整个模型进行了视觉语言预训练。
3.代码
代码上的精髓就在这了哈哈哈哈哈...
