文章目录
准备知识
-
OSCAR 和 UNITER :在没有 Transformer 之前,做多模态的就是 OSCAR 和 UNITER 等工作,其中用的是 object detection 的模型来做视觉特征的抽取,这个代价很大
-
ViLT:transformer (ViT)出现之后,ViLT 的作者就想到使用 linear embedding 来代替视觉特征的抽取,大大的简化的视觉特征的抽取过程和代价
-
CLIP:能高效的做图文对比学习来实现高效的图文检索
-
ALBEF:根据 ViLT 的简单结构、CLIP 的对比学习的高效和强悍、UNITER 的多模态融合的有效,结合了三家长处,得到了 fusion-encoder 的结构,能够实现更高效的更强悍的图文理解
-
CoCa:在 SimVLM 和 ALBEF 的基础上,提出了对不同任务框架的统一
-
VLMO:基于 ViLT 和 ALBEF,提出了共享参数的统一任务框架
-
BLIP:基于 ALBEF 和 VLMO,提出了一个能实现文本生成的框架,也相当于一个普适的工具,能生成很好的文本描述
-
BEIT:在 ViT 的基础上,顺着 BERT 的 mask 的思想,提出了 BEIT,能在视觉上做 mask model
-
VL-BEIT:结合了 BERT 在文本上的 mask 方法和 BEIT 在视觉上的 mask 方法,推出了多模态的 mask 方法
-
BEIT-V3:结合了 VMLO、BEIT、VL-BEIT,推出了 BEIT-V3,超过了单模态和多模态的大量方法
-
MAE:在 ViT 的基础上,mask 掉 pixel,很有效的做了 mask model,MAE mask 掉了大量的视觉 patch,只把没有 mask 的 patch 送入了 vision transformer 学习,计算量就变小了
-
FLIP:结合了 CLIP 和 MAE 的特性,模型就是 CLIP,在视觉那端只用了没有 mask 的 token,降低了计算量,所以 Fast
还有很多研究者聚焦于模型的统一,因为 VLMO 和 BEIT 这些虽然号称自己是大一统的模型,其实是多种模块的拼接,用的时候需要哪个用哪个,而不是真正意义上的一个模型
所以很多工作聚焦于 Language interface 和 generalist model,依然想建立真正意义上的大一统模型
- Language interface:就是使用 prompt 来控制模型,在做不同任务的时候使用 prompt 来告诉模型现在要做什么任务,然后控制模型的输出,如 metaLM、PaLi 等
- generalist model:通用模型,也是想在预训练和下游任务的时候训练一个模型,不需要调整结构和添加 head,如 unified-IO、unipercivier 等
一、CLIP:不同模态简单对比的方法更适合于图文检索
论文:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/OpenAI/CLIP
官网:https://openai.com/research/clip
出处:OpenAI
时间:2021.02
贡献:
- 基于图文匹配,不受限于分类类别,有很强的扩展性!!!这是 CLIP 最炸裂的地方,彻底摆脱了预定义标签列表了
- 不仅仅能识别物体的类别,而且通过引入文本语义和视觉语义进行了联合,所以语义性非常强,迁移效果也很好,因为和语言信息的结合,所以 CLIP 学习到的视觉特征和用语言描述的物体产生了强烈的联系,无论是动漫、素描、真实的香蕉,能在域变化很剧烈的情况下,仍然很好的识别出香蕉
- 提出了一个基于图文匹配的多模态模型, 通过对图像和文本的模型联合训练,最大化两者编码特征的 cosine 相似度,来实现图和文的匹配
- 基于图文匹配的模型比直接学习文本内容的模型效率高很多
CLIP 的核心就是利用自然语言的监督信号来指导模型训练
作者强调这种思路并不是一种很新的思路,因为之前就有方法做了相关研究,但描述的很凌乱,同样的思想却被分别称为无监督、自监督、弱监督、有监督的方法,看的很混乱,而且规模也没做大,所以本文就是总结了这些方法且用很多的实验证明了效果
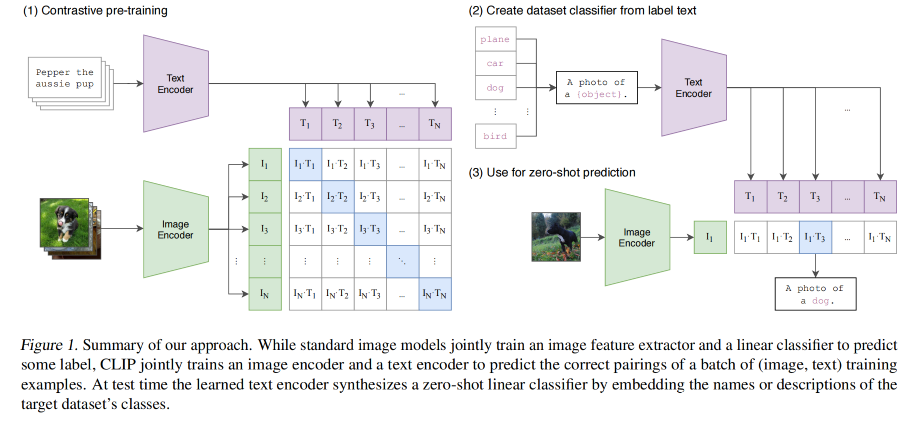
预训练流程:
- 利用自然语言的监督信号来学习迁移到视觉模型
- 对文本使用文本编码器,提取文本特征,对图像使用图像编码器,提取图像特征
- 一个迭代中,假设有 N 个文本特征和对应的 N 个图像特征,CLIP 就是在这些特征上进行对比学习
- 对比学习只需要正样本和负样本的定义
- 这里的正样本就是配对的图文 pairs,也就是图 1(1) 中的对角线位置上的特征对儿,负样本就是其他位置上的特征对儿,这里有 N 个正样本,N^2-N 个负样本
- 这里是无监督的训练方式,所以需要大量的数据,所以使用了 4 亿 图文对儿来预训练
推理:
- 既然 CLIP 是无监督的方式,那么其实是没有分类头的,所以 CLIP 提出了使用 NLP 那边的 prompt template 的方式
- 也就是把 ImageNet 的每个类别名称(如 car)变成一个句子(a photo of car),1000 个类就有 1000 个句子,通过预训练好的文本编码器,就能得到特征
- 为什么要把类别名称变成一个句子呢,因为在预训练的时候模型见到的都是句子,所以使用句子形式的文本就比较好
- 然后把图片特征和文本特征算相似性,和哪个文本最相似,就挑出来这个文本作为类别作为结果
1.1 CLIP 在分割上的改进工作
分割任务其实是对像素级别的分类,所以分类任务的技术很容易就能用到分割任务上来
1.1.1 LSeg
论文:Language-Driven segmantic segmentation
出处:ICLR2022

1、模型效果
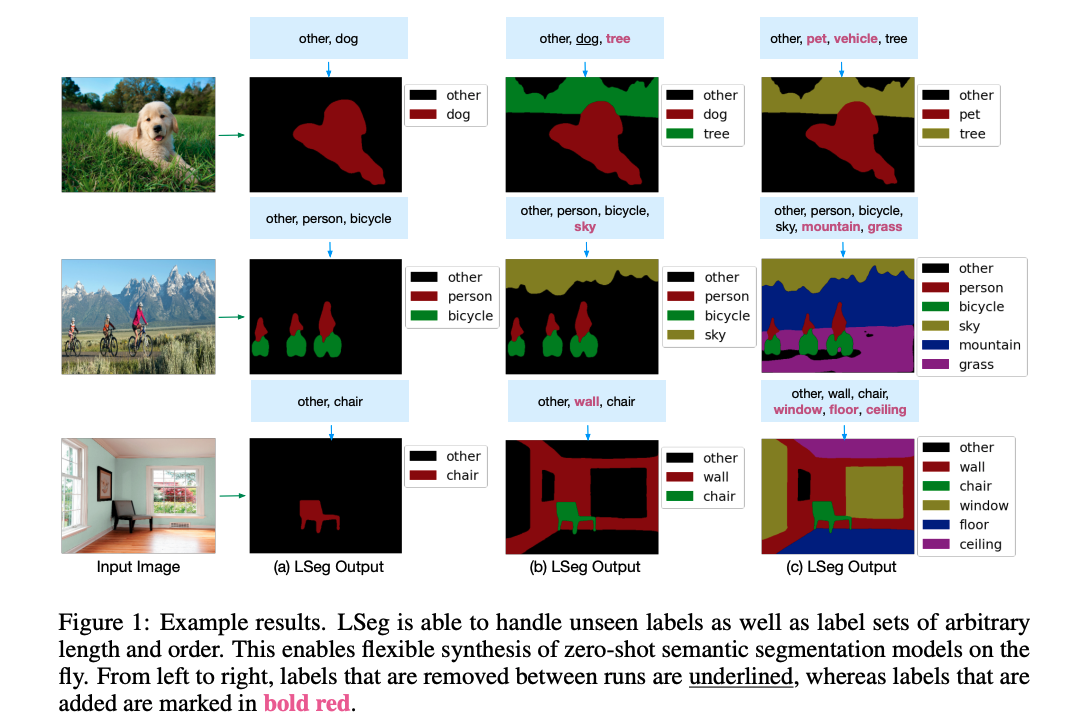
2、模型架构
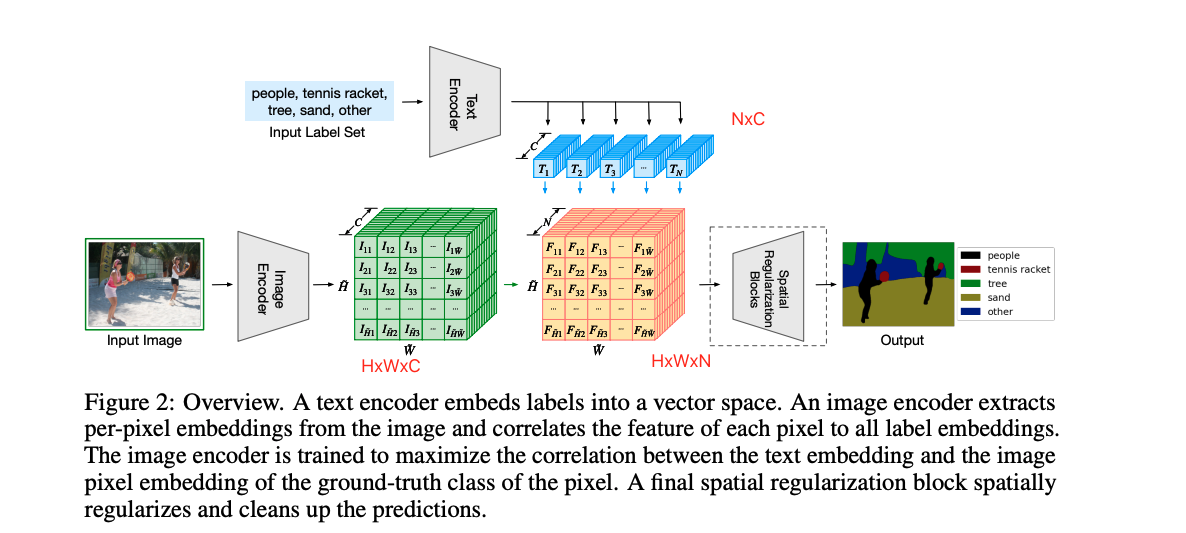
模型结构和 CLIP 看起来非常像:
-
单看下面的图像特征的处理过程,和有监督的图像分割结构完全一致,都是对图像进行特征提取,得到特征图,然后上采样得到输出特征图,输出和 gt 做 loss 就可以了
-
文本的处理也是先输入 label,假设有 N 个 label,经过 text encoder 就会得到 N 个文本特征,也就是 NxC 的特征,而且这里的文本编码器是使用的 CLIP 训练好的编码器,在训练的过程中是不参与训练的,是冻住的
这个方法就是将文本引入了分割任务,但终究使用的是有监督的训练方式,就是使用了 7 个分割数据集的 gt 来监督模型的训练,计算 CE loss
1.1.2 Group ViT
论文:GroupViT: Semantic Segmentation Emerges from Text Supervision
代码:https://github.com/NVlabs/GroupViT
出处:CVPR2022

因为 LSeg 虽然很类似于 CLIP 的结构,但目标函数不是对比学习,也并没有把文本当做监督信号来使用,还是依据于人工标注的 mask 来训练的,手工标注 mask 是很贵的,所以还需要研究如何真正使用文本来监督训练
GroupViT 是真正的利用的文本特征,使用图像-文本对来监督模型训练,不需要使用 mask,从而让模型来实现简单的分割任务
视觉上很早之前做无监督分割的时候,其实就是一种自下而上的方式,就是使用 group 的方法,就是假如有聚类的中心点,然后从中心点开始发散,把附近周围相似的点来扩展成 group,这个 group 就相当于一个 mask
本文作者重新审视了一下 group 的方法,提出了一个计算单元 grouping block,还有一些可学习的 tokens,希望模型在初始学习的时候就能慢慢的把相邻相近的像素点 group 起来,慢慢形成一个 mask。
可以看到在初始浅层上,学到的 group token 分割的效果还不是很好,经过学习的深层 group token 就做的挺好的了,所以 GroupViT 就是在原始的 group 框架中,加入了 group block 和可学习的 group token。
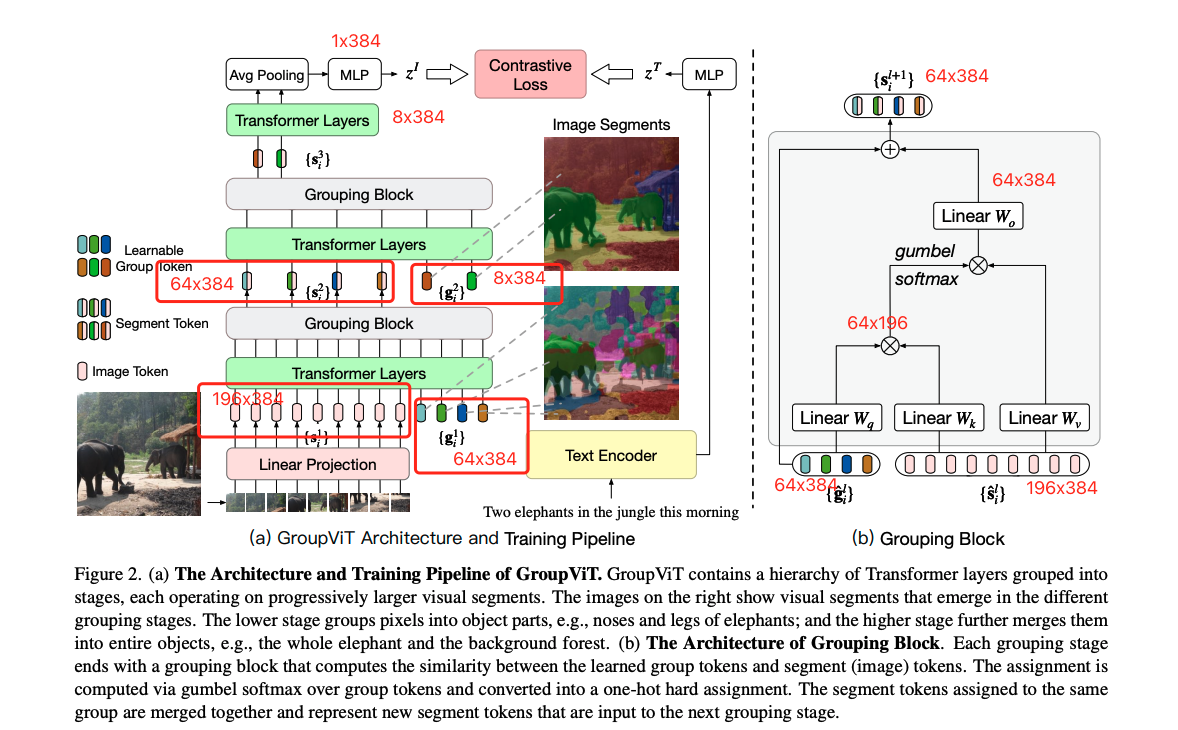
模型训练:
图像编码器是 transformer,一共有 12 层,输入有两部分:
- 图像 patching embedding:图像 patch 大小为 16x16,就有 14x14 个块儿,经过 linear projection 后得到 196x384 特征,196 =14x14, 384 是将每个 patch 编码成 384 的特征
- 可学习的 group token:64x384 大小,384 是为了维持维度不变,为了和前面的图像 384 维的特征进行拼接,64 是希望开始的时候有尽可能多的聚类中心,可以理解为 cls token,就是想用这个 token 代表整个图像的类别,之前 cls token 只有一个的原因是用整个 cls token 代表整个图像特征,这里的 64 表示 64 个聚类中心,或起始点,把看起来相似的或语义接近的点都归结到这 64 个聚类内,让模型学习这些 patch 哪些属于哪个 token。
- 在 6 层 transformer layer 后加入了 group block:作者认为在 6 层 transformer layer 后呢,已经教会了这个些 group token 学的差不多了,然后就把这 64 个 cluster 聚合一下,学到更高语义的一些信息,所以就利用 group block 把这些图像 patch embedding 分配到对应的 token 上,然后就只剩下了 64 个 token,得到 64x384 的特征,也会降低序列长度,降低模型计算复杂度,类似层级式的网络结构
- 完成了第一次 group 呢,作者还希望把 64 个聚类中心变得更小一些,因为常见数据中类别也不会太多,所以又加了一次 8 个 group token,8x384,也就是把 64 个 token 映射到 8 个 token上,作者在第九层 transformer layer 上加了这 8 个 token,后面会再经过 3 层 transformer layer 的学习,也就是图像分成了 8 大中心,每个中心对应了不同的特征。
- 得到了 8x384 的特征序列后,怎么得到最终的图像级别的特征来做对比学习特征呢,作者使用 avg pooling 得到了 1x384 的特征,然后最后做一次 MLP 得到 1x384 的特征,然后计算图像-文本对的对比学习的 loss

模型推理:
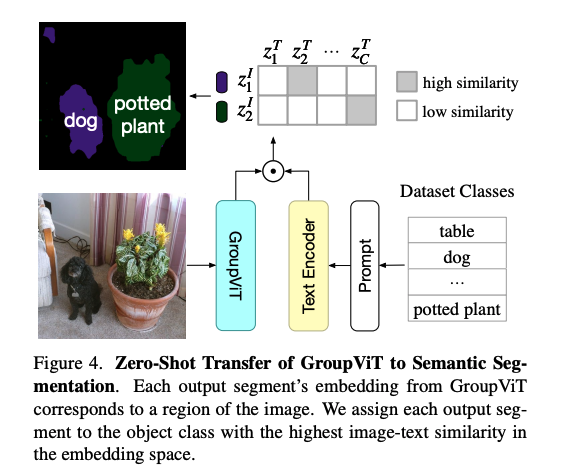
- 给定一个图片,经过 GroupViT 得到 8 个 group embedding
- 将输入的 prompt 文本通过文本编码器得到文本特征,计算 group embedding 和文本的相似度,就可以得到每个 group 和 text embedding 的关系就可以了
- 但有一个局限就是,输出只能是 8 个类别
可视化 group token 的作用:能够起到不同类别划分到不同 group 上的作用
- stage 1 关注比较小的区域,第 5 个 group 对应的就是眼睛,第 36 个 group 对应的就是四肢
- stage 2 关注比较大的区域,第 6 个 group 对应的就是草地,第 7 个 group 对应的是人脸

效果:
- 虽然超越了之前的无监督的方法,但和当前的有监督的 SOTA 有二三十个点的差距
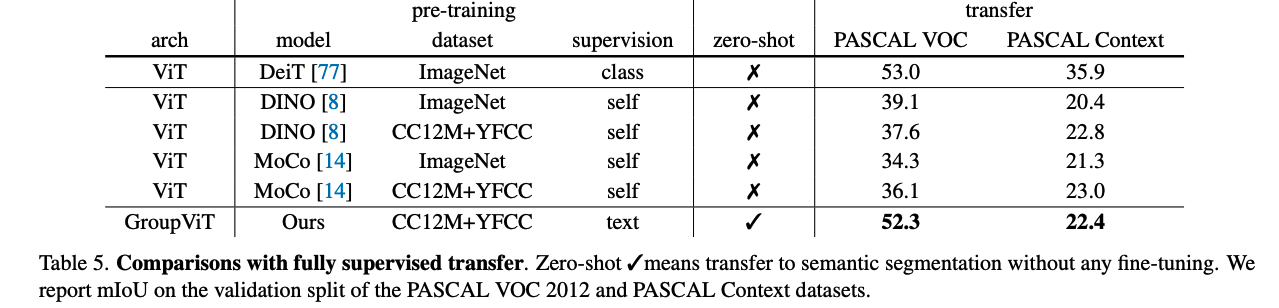
局限性:
- 结构还是更偏向于图像编码器,没有很好的用到密集预测的特性,如多尺度、多感受野等等
- 分割效果好,但分类效果差
分割中存在背景类,作者为了尽可能的提高前景类的性能,作者这里设定了一个阈值,如 PASCAL VOC 设置为 0.9,就是当匹配的相似度超过 0.9 时,才会说 group embedding 属于这个类别,如果都没有超过阈值的话,就说明不是前景
这个操作都 PASCAL VOC 上这种前景特别明显类别少的数据集上表现还好,但在复杂数据集上前景类和背景类的得分差不了很多,设置一个很高的阈值就会导致把很多很多前景部分分割成了背景部分,设置很低的阈值就会造成错误分类,相似度最高的那个类别不是真正正确的那个类别。
这是作者自己发现的问题,通过观察发现 group token 学的挺好的,就是分割效果做的挺好的,就是最后的分类会分错。
所以作者直接拿了 gt 的类别标签,只使用 group vit 输出的 mask 和 gt 的标签进行 IoU 计算,IoU 最大的 gt label 直接给到预测 mask 作为类别,用这样的方式来验证到底是不是分类效果影响了最后的分割评价效果。
作者用这样的方式来验证后就得到了 table c.3 的结果,提高了二三十个点,和有监督的 SOTA 基本逼近了。这也验证了 group vit 已经把分割做的很好了,只是说语义没识别正确。
这种结果究其原因还是在于 CLIP 的这种训练方式,只能学到物体语义信息非常明确的物体,而无法学习到语义信息很模糊的东西。

1.2 CLIP 在目标检测上的改进工作
1.2.1 ViLD
这篇文章的开头就说明白了,本文要实现的就是能够检测任意的物体类别,做的方法就是把 CLIP 当做 teacher,蒸馏自己的网络

作者先给出了当前目标检测方法的限制,就是只能检测有限的基础类别,比如蓝框标出来的就叫 toy,那么模型就只能检测 toy,如果想检测绿色的玩具,或者鸭子,模型是没有办法检测的
所以是否能做到不额外标注鸭子、绿色玩具的情况下,模型就能识别这些目标呢,也就是能检测新类别的能力

论文的主体方法:
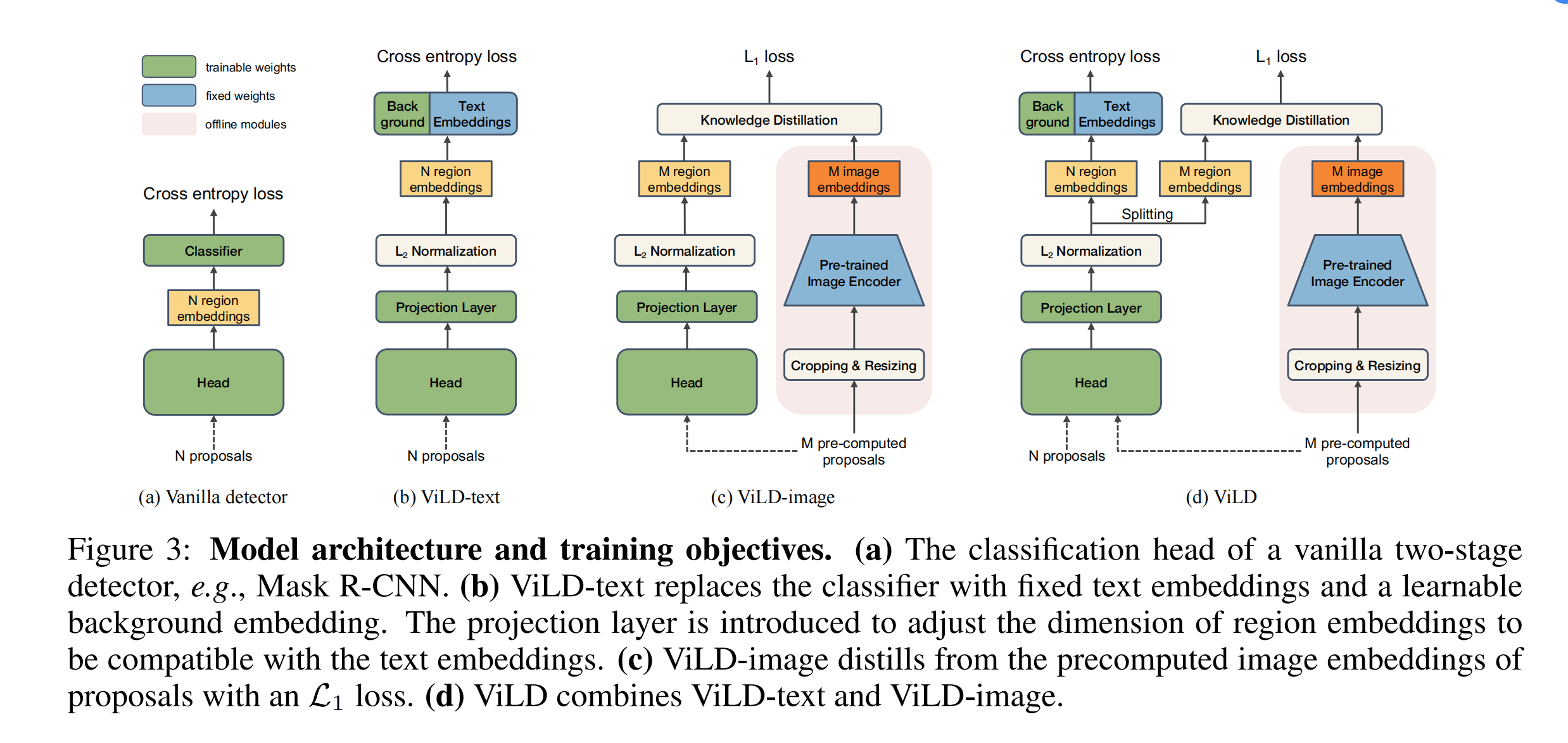
这个论文的思路其实是在基础类别上做有监督的训练的,也就是有监督的训练
A base line:
只涉及基础类别 C B C_B CB,也是 mask rcnn,第一阶段输出 N 个 proposal,然后抽特征,最后分类,会使用分类和定位来衡量目标检测的效果。ViLD 相当于把分类和定位这个两个任务给分开来了,输入的时候直接就是 N 个 proposal 了,第一阶段提取 proposal 的阶段没有体现在其中,也就是说文章的重点不在于提取 proposal,而在于第二阶段
B ViLD-text:
ViLD-text,只涉及基础类别 C B C_B CB,会从头开始训练,和 Mask rcnn 的差别在于适用固定的 text embedding 代替了可学习的分类器,这里的 N 个 proposal 输入是来自于第一阶段的 RPN 网络,和 mask rcnn 中的一样,是参与训练的。
主要是将图像特征(黄色 region embedding)和文本特征(蓝色 text embedding)做了关联,计算相似度。
输入是 N 个提取好的 proposal,经过一些映射得到 N 个 region embedding,对应 N 个 proposal 的特征
文本的 embedding 就是将物体要检测的类别拿过来先变成 prompt 模板(a phtot of {}),然后送入固定的文本特征提取器,也就是图中蓝色框中,得到对每个类别的文本编码特征,这里是使用基础类别的名称来监督检测的训练的,所以在这里也只是将文本和图像的特征做了关联,zero-shot 的特征还有待加强。
而且这里还有 background ,就指的是除过基础类别之外的其他类别的 text embedding,全部塞给背景类,背景类的文本编码是可学习的。N 个 region embedding 要同时和固定的 text embedding 和 background embedding 计算相似度。

C ViLD-image:
ViLD-image,同时涉及基础类别 C B C_B CB 和新类别 C N C_N CN。使用的是用训练好的 RPN 预提取的 M 个 proposal
因为 ViLD-text 已经有了一定的图文关联能力了,但毕竟只是在基础类别上去训练的,如何扩展到新的类别上呢,或者如何把 CLIP 的能力引入到这个框架里边来呢,作者就提出了 ViLD-image。
作者认为 CLIP 预训练好的图像编码器很好,而且和文本的关联也很好,所以,如果这里这个黄色块的图像编码结果能尽可能的像 CLIP 输出的橘色块里边的图像编码,想做到这点就可以使用知识蒸馏。
具体做法就是粉色背景区域中(teacher 网络),对抽出来的 proposal 从原图中 crop,crop 出原图的区域并 resize,然后送入 CLIP 预训练好的编码器来得到 CLIP 的图像编码特征,这里 CLIP 图像编码器是不会参与训练的,是固定的参数。
ViLD-image 左边的这个分支呢就是 student 网络,包括检测头、特征映射层等,使用 L1 loss 做蒸馏。注意,这里的类别就不受基础类别的限制了,因为 proposal 是与类别无关是,是第一阶段的 RPN 网络提取的,监督信号是从 CLIP 来的。
但这里值得注意是 M 个 proposal,而不是之前的 N 个 proposal(前面这个 RPN 网络输出的就是 N 个 proposal),但肯定用全部生成的 proposal 会更好一些,但事实上,如果每次在训练的时候再抽取 CLIP 的特征(蓝色)呢就很费时间,而且作者想用最大最好的 CLIP 模型,这样就会更耗时。如果每次训练有 1000 个 proposal,那么就要进行 1000 次的图像特征提取,而且每次迭代都要提取这些 proposal 的特征,肯定会拉长训练时长。所以作者就在训练之前,先利用 RPN 预抽取 M 个 proposal,通过 CLIP 模型提取好特征,然后存储起来,在训练的时候直接拿来 embedding 就可以。所以这 M 个 proposal 和那 N 个可以在训练的时候改变的 proposal 是不一样的。
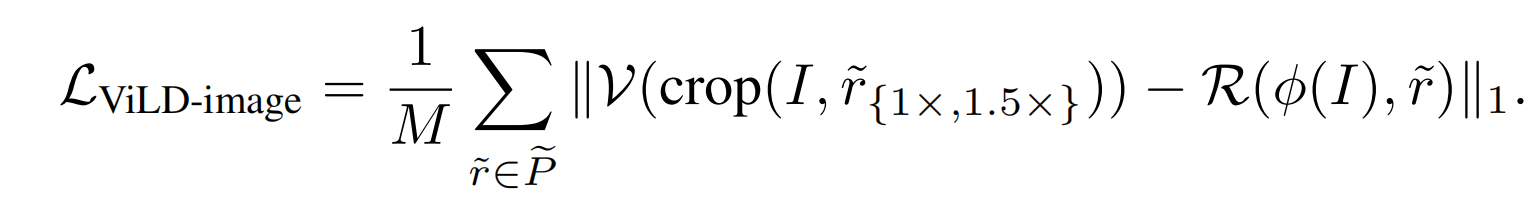
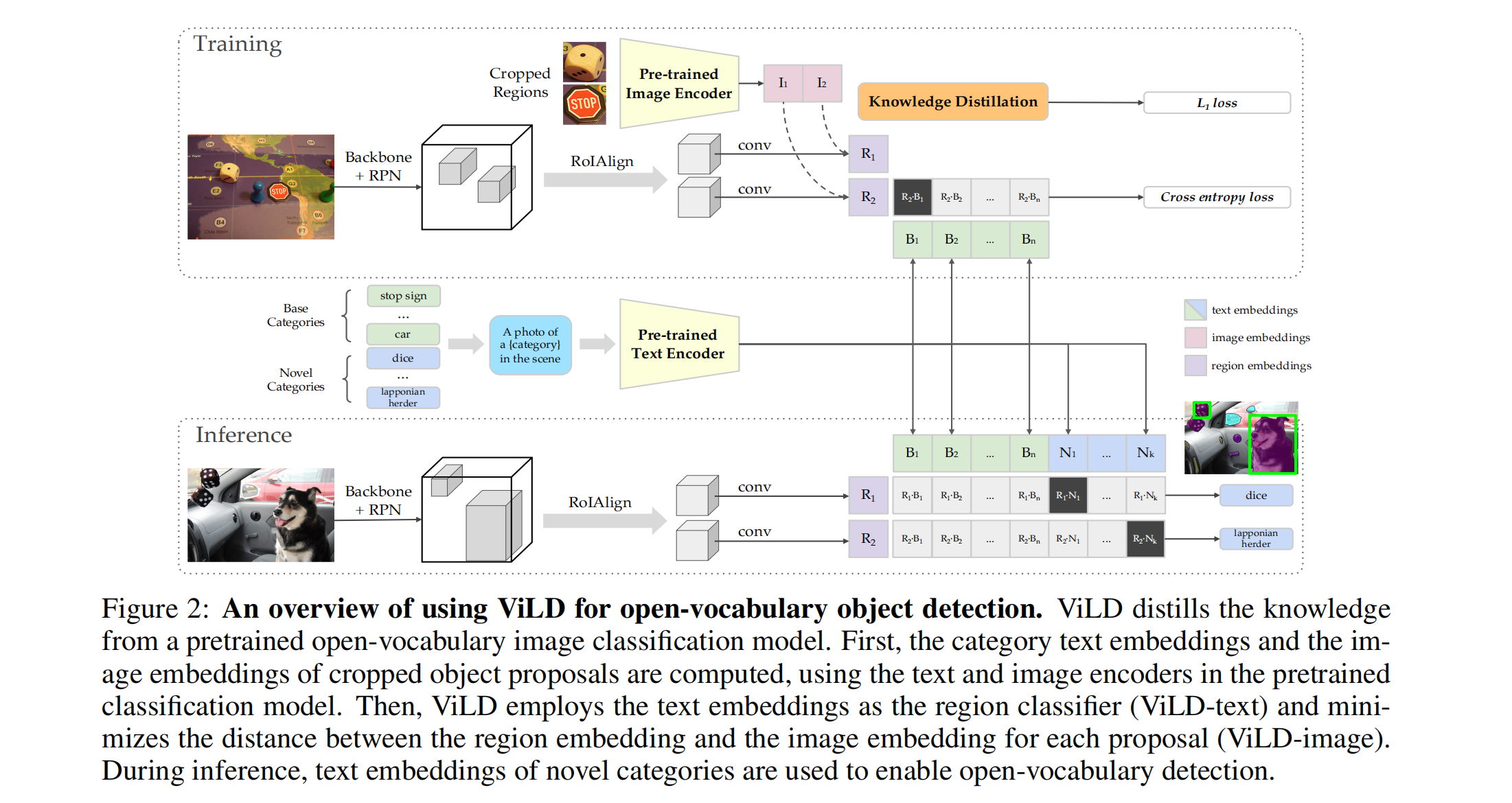
C ViLD:
左边是目标检测分支,右边是 CLIP 图像 embedding 的分支,右边只有在训练的时候才会用的,推理的时候是不会使用的。
具体的就是把 N 个 proposal 和 M 个预抽取的 proposal 全部输入检测头,得到 N+M 个 region embedding,N 个 embedding 去计算 cross entropy loss,M 个预抽取的 region embedding 去计算蒸馏的 L1 loss

训练整体过程:
ViLD-text 的过程:从头开始使用基础类别来训练特征提取器和图文匹配能力(基于第一阶段训练得到的 N 个 proposal )
- 给定图片,先经过 RPN 得到 proposal,进行 RoIAlign,和 conv 层得到 embedding,得到图像编码
- 给定绿色基础类别,先进行 prompt 模板化,然后使用预训练好的文本特征提取器来提取 text embedding,得到文本编码
- 有了两组编码后,使用 cross entropy loss 来计算 loss
ViLD-image 的过程:使用 M 个 proposal 的 CLIP 特征指导学生网络的训练
- 对抽取好的 M 个 proposal,经过 CLIP 预提取 teacher 图像编码特征
- 让 student 网络学习这 M 个 proposal 的 teacher embedding
也就是说这 M 个预提取的 proposal 用于指导蒸馏,N 个可训练的 proposal 用于参与 proposal 特征的提取和图文的匹配
推理的过程:
- 给定图片,提取 proposal ,经过 RoIAlign,得到 region embedding
- 给定检测类别,送入 prompt 模板,得到 text embedding
- 对所有 region embedding 和 text embedding 计算相似度,得分最高的就是对应的类别
效果:
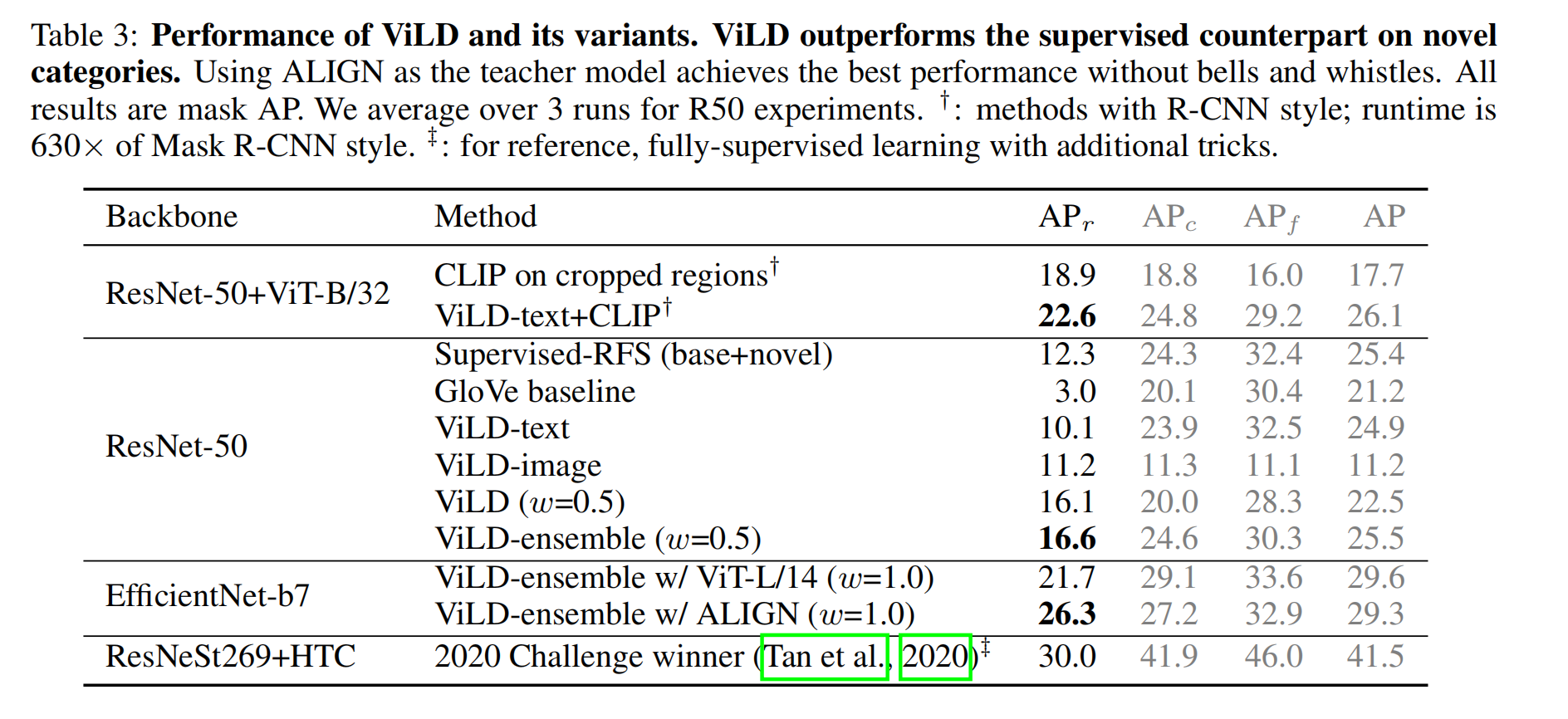
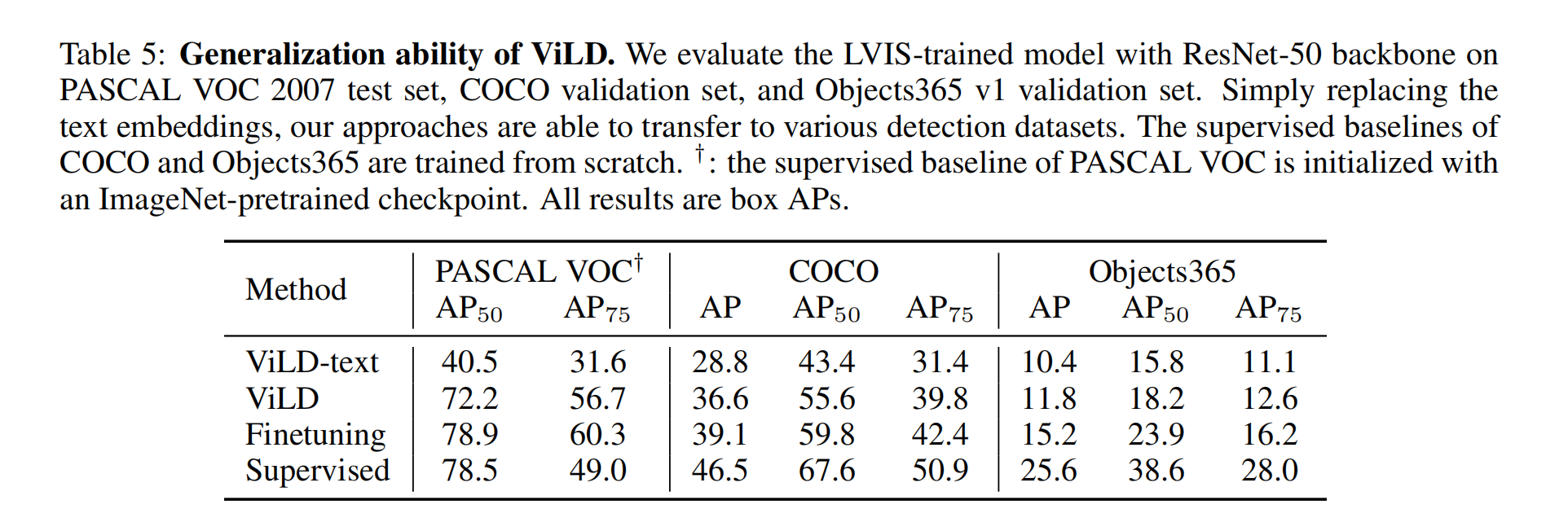
总结:
- ViLD 算是第一个 LVIS 这么大的数据集上做开放词汇检测的方法,利用了 CLIP 的参数,也借鉴了 CLIP 了权重
1.2.2 GLIPv1

GLIP 的动机:如何像 CLIP 一样利用超多的容易获得的图像文本对儿来实现对任意目标的识别
所以本文主要围绕的也是如何扩大数据量级这个目标来做的
因为 phrase grounding 其实和目标检测的本质是一样的,那么是否能够将两个任务结合起来,将两种数据都利用起来,从而实现能够利用更多的数据就是作者思考的问题
此外,作者还把伪标签那种方法加进来,就是 self-training 的方法,在没有标注过的图像文本对儿上生成伪标签,从而扩大整个数据集的数量,来将整个模型训练的更好。
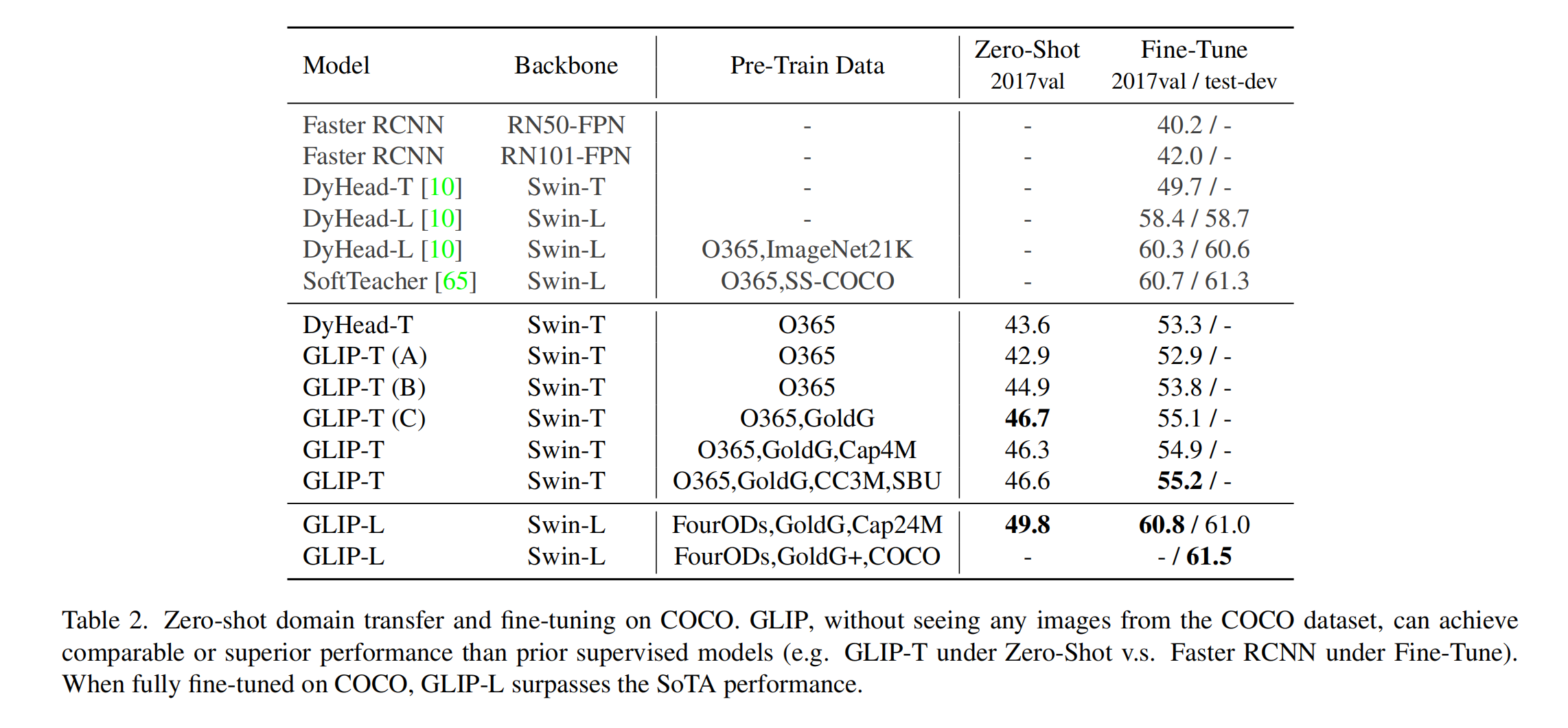
所以 GLIP 在 COCO 上 zero-shot 的效果就达到了 49.8AP,这在有监督里边都是很能打的效果

GLIP 是怎么把目标检测和 phrase grounding 结合起来的:将目标检测的类别全部放入 prompt 中作为检测类别
- 目标检测一般就是使用分类+定位的 loss 来实现
- 定位部分两个任务是差不多的,区别就在于如何计算分类的 loss,检测的类别标签是一个单词,phrase grounding 的标签是一个句子
- 检测的分类是用分类器来预测的,一个可学习的分类器
- phrase grounding 的分类是用匹配分数来计算的,但都是类似的
作者验证了可行性后,就可以把 phrase grounding 数据集和检测数据集结合起来了,但还想进一步扩大数据集来支持各种各种的物体识别
所以作者进一步引入了 Cap4M 和 Cap24M 这些 caption 数据集,这些数据集是没有框的信息的,所以作者使用基于 Object365 和 GoldG 数据集训练好的 GLIP-T© 模型对这些图像-文本对儿进行推理,推理出来的 bbox 就当做 gt,但肯定不是很准确,所以叫做伪标签,通过提供伪标签的方式来进一步提高数据量。
总体的数据量是 3M 标注数据集+24M 伪标签数据集 = 27M数据量
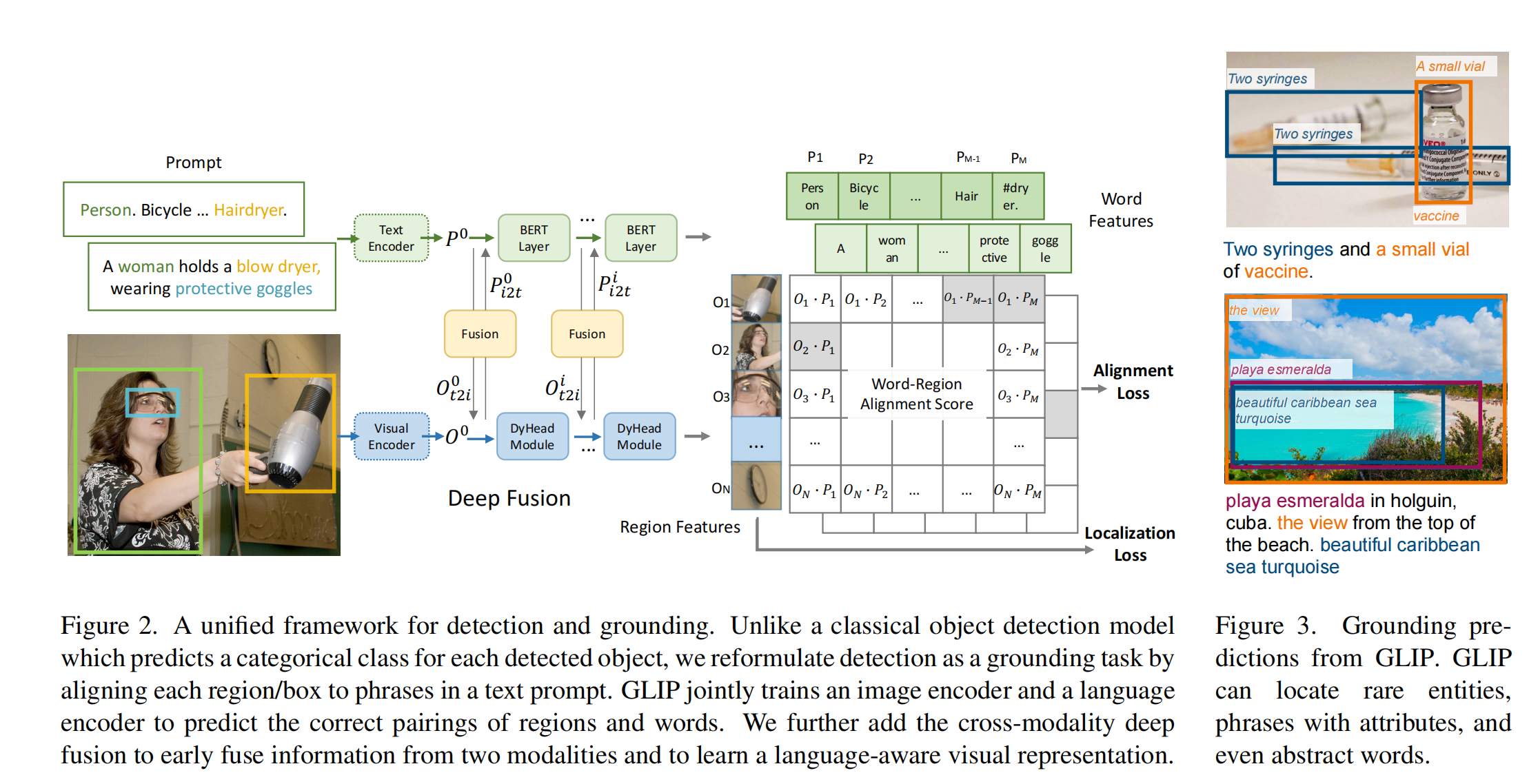
总体框架:
- 分别抽取文本 embedding 和图像 embedding,都是单模态的特征
- 然后使用一些层来进行多模态特征的融合,让不同模态之间的特征多进行一些交互,就能让模型进一步将相似的图像-文本对儿的距离拉近,不相似的图像-文本对儿的距离拉远,总之能让特征更加有关联性,这里用的是 cross-attention
- 抽取完的图像特征和文本特征后,计算相似度矩阵,然后计算 alignment loss 和 localization loss 即可
效果:
- 单模态的模型都不能做 zero-shot,必须微调
- GLIP-L zero-shot 已经很好了,fine-tuning 后更好
1.2.3 GLIPv2
将更多视觉定位和视觉理解任务都结合起来了,比 GLIPv1 做了更多的工作拓展,能做检测和分割,还能做 VQA 和 Image caption,而且为每次的迭代引入了更多的负样本,让不同图文对能拉的更远。
二、ViLT/ALBEF :多模态融合在 VQA/VR 任务中更重要
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
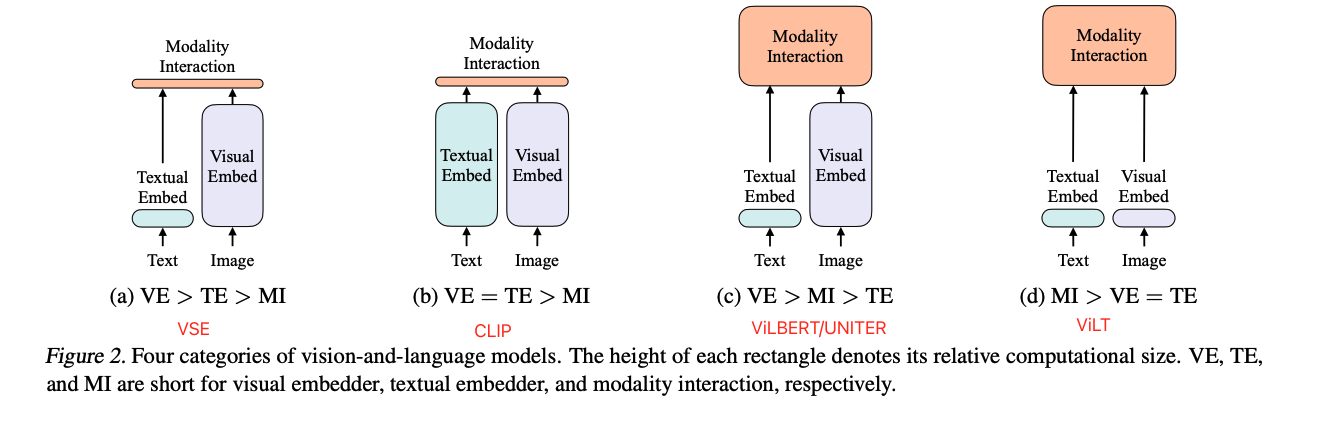
我们已知 CLIP 在对有明显语义特征或者说很好描述的任务上表现的比较好,如图像分类,很好的描述这是狗或猫,但在难以很容易用语言描述清楚的任务,或者说文本描述比较复杂的任务上(VQA/VR)表现不太好,究其原因就在于 CLIP 只是对两个模态的特征进行了简单的融合匹配,并没有让模型学习到更深层次的图像-语言之间的内在关系
所以,我们已经知道在多模态中,图像编码器是要比文本编码器更重要的(虽然 ViLT 使用了轻量级的图像编码器达到了 trade-off,但效果是在是不太好),然后模态之间的融合也是很重要的,也就是类似于 c 中的样式,当然其中的视觉模型是使用 Vision transformer (而不是 ViLT 中的 linear embedding)
从 CLIP 的成功中可以知道使用 Image-text contrastive loss (ITC)一定是很有用的,所以一定要使用的,而且 ViLT 中的 WPA loss 计算起来非常慢,所以训练起来很费劲,还有两个常用的 loss,一个是Mask Language Modeling loss(MLM)在 NLP 里边应用的很多也很成功,还有一个是 Image-text Matching loss(ITM)在 ViLBERT 和 ViLT 中都取得了很好的效果,所以也继续采纳。
从这可以发现,一个好的多模态模型,可能使用 ITC+MLM+ITM 这三个 loss 就能取得较好的效果了
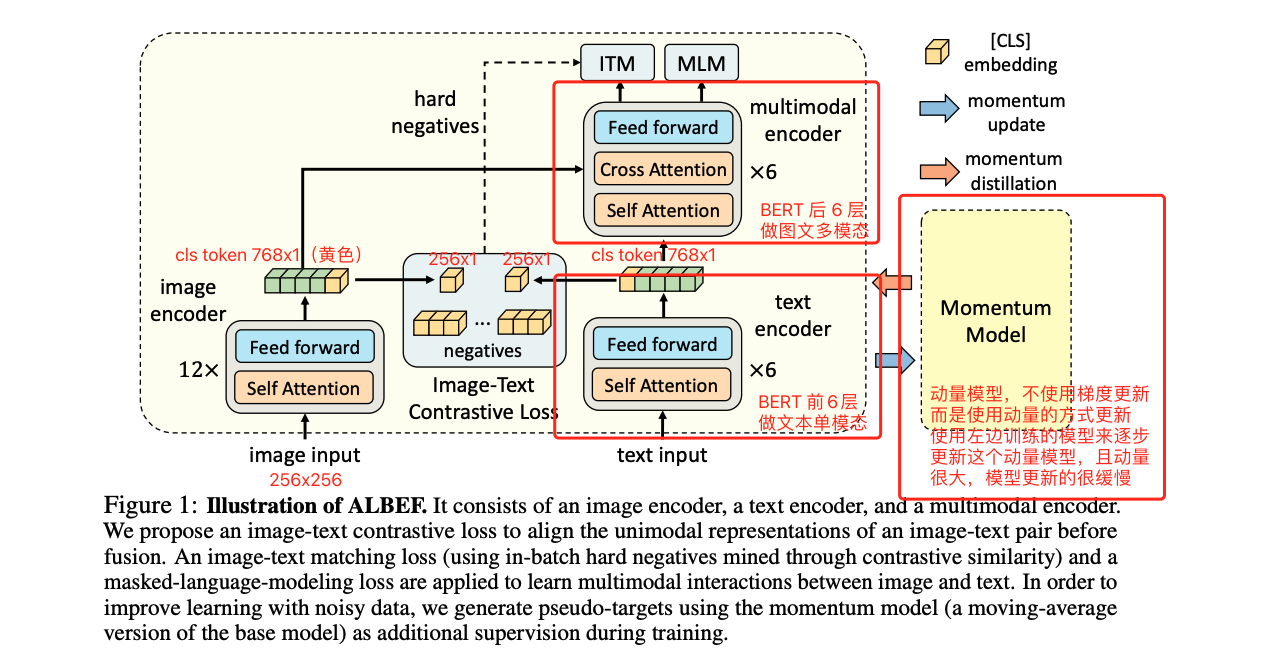
所以现在可以来看 ALBEF 的结构
ALBEF:
- 图像的编码器:12 层 transformer
- 文本的编码器:将 12 层的 BERT 分成了两部分,前 6 层做文本的编码器,后 6 层做多模态融合的编码器
- 这样的结构就是图像编码器更大,融合模型更大,文本编码器较小的结构
- loss 也是使用了 ITC+MLM+ITM 这三个 loss
ViLT 的出发点:视觉编码使用目标检测方法的速度太慢了,想让速度变的更快一些
ALBEF 出发点和贡献:
-
贡献 1:使用对比学习 loss 在两个模态的特征融合之前先进行了特征对齐
用了预训练的目标检测器提取的视觉特征,和文本特征是没有 align 的,因为目标检测器是提前训练好的,用于抽特征,将两个距离很远的两种模态的特征同时送入 transformer 编码器的话,编码器不太好学习,就是很难以学习到图像和文本之间的交互信息。所以 ALBEF 就提出了一种对比学习的 loss(就是 ITC),能够在 fusing 之前就通过 cross-modal attention 把文本和图像特征进行对齐。
-
贡献 2:为了从 noisy 的数据中更好的提取特征,所以使用了 self-training 的方式来训练了模型(也就是伪标签),所以还使用了 MOCO 中提出的 momentum model 来生成伪标签,从而达到自训练的效果。为什么作者说从网上爬取的图像文本对儿是 noisy 的是因为,直接爬取的,很多文本并没有很好的描述对应的图像,而这些文本都是具有搜索性的,不是描述性的。
ALBEF 的效果:
- ALBEF 在图文检索上超过了 CLIP
- 在 VQA 和 NLVR 上也超过了 SOTA
- 4M 数据集 8 卡训练 3 天,很亲民
ALBEF 的主体结构:左边是梯度更新的模型,右边是使用动量更新的模型,图像模型更大,文本模型更小,文本模型原始的 BERT 分了 6 层用于模态融合了,所以总体参数还是没有很大的变化的
- 图像模型:给定输入图片,切分成 patch,经过 patch embedding 送入 transformer encoder,输入为 256x256
- 文本模型:使用 BERT 做初始化,前 6 层用于提取文本特征,后 6 层用于多模态融合
- 动量模型:为了做 momentum distillation ,也为了给 ITC loss 提供更多的负样本,所以还有一个 momentum model,这个蒸馏模型不会梯度反传,而是使用 moving average 的方式来更新,产生的特征会更稳定
训练图像 embedding 和 BERT embedding 前 6 层的目标函数:
-
ITC Loss:用于训练图像 embedding 和 BERT embedding 的前 6 层
图像-文本对比学习,对比学习的目标是将一对样本拉近,非一对的样本拉远
图像和文本分别经过各自的编码器,都会有 768x1 的 cls token,然后将 cls token 映射为 256x1 的向量,两个 cls token 就分别代表图像和文本的特征,就希望一对的特征尽可能的近,和其他有 momentum model 产生的负样本(存在 q 里,共 65536 个负样本)特征尽可能的远,也是模型的第一阶段的学习。
也就是文章题目中 align before fuse 中的 align 过程。这里的 ITC loss 就是和 MOCO 完全一样,计算的是 cross entropy loss。
训练多模态融合的 目标函数:
-
ITM Loss:Image-text matching,给定一个图像,给定一个文本,对各自 embedding 通过 attention 得到交互后的特征,然后使用分类头(FC)来判断 I 和 T 是不是一个对儿。
这个 loss 实际在想做好其实比较难,因为判断谁和谁是正样本对可能比较难,但判断谁和谁是负样本对很简单,因为一个图像匹配的文本只有一个,其他很多很多的文本样本都是负样本,所以在训练的时候精度能得到很大的提升,然后训练再久都没什么意义。
所以常见的做法就是在选负样本的时候给一些限制,这里就选择了难负样本来参与训练,也就是选择和正样本很接近的负样本来参与训练。
这里 batch size 假设是 512,那么一个迭代中正样本对就是 512,对于每一张图片,从哪里找 hard negative 文本呢,ALBEF 借助了上面的 ITC 来进行 hard negative 文本样本的选择,就是使用 ITC 计算一遍整个 batch 中所有图像和所有文本的相似度 cos similarity,选择除了自己之外的相似度最高的那个文本作为负样本,也就是这个文本和图像都非常相似了,但其实是一个负样本,所以 ITM loss 就变的很难了,这样才能进行有意义的训练
-
MLM Loss:把原来完整的句子进行 mask,擦除掉一些单词,把擦除了一些单词的句子和其对应的图片一起输入到 ALBEF 中,然后需要把之前完整的句子预测出来,这里不像 NLP 中单纯的 MLM,而是借助的图像信息
总体 loss(不带动量的):
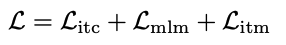
每次迭代前向传播的次数:2
- ALBEF 这里计算 ITC 和 ITM 的时候使用的是图像和原始文本,需要进行一次前向传播
- 计算 MLM loss 是使用的是图像和 mask 后的文本,还需要进行一次前向传播
- 多模态任务很多模型都需要多次的前向传播,满足各种条件,所以一般训练时间都比较长
动量蒸馏:
为什么要做动量蒸馏:
- 爬取的图像文本对通常不是很匹配,会导致计算 loss 的时候会有偏差,因为可能比所谓的 gt 匹配更优的负样本,所以 one-hot label 这种 gt 方式(就是一个图像对应一个描述,其他都是负样本描述,或者一个 mask 中只能填一个单词)对 ITC 和 MLM 都不是很好,因为有的负样本也包含了很多好的信息,一味的惩罚这些负样本也不好
- 所以,如果能找到额外的监督信号,最好是 multi-hot 或另外一个模型的输出就更好的,作者先构建一个 momentum model ,来生成一个 pesudo-label,这个 pseudo targets 其实不是一个 one-hot 向量,而是 softmax score。
- 动量模型就是在已有模型之上进行指数移动平均(EMA),希望在训练原始 model 的时候,不只希望预测结果和原始输入(one-hot)很接近,还希望预测结果从动量模型的输出很接近,在一般情况下从 gt one-hot label 中学,如果 one-hot label 是 noisy 的时候或者是错的时候,模型能从动量模型中学习到一些改进。
带动量的 ITC loss :
- 原来的 ITC loss 就是 L I T C L_{ITC} LITC,是基于 one-hot label 的,新的 loss 还加了后面一项,把 gt 换成了 q(pseudo-label),因为 q 是 softmax 分布,所以就计算 KL 散度
- 最终的带动量的 ITC loss就是使用 gt 的 ITC + 使用 pseudo-label 的 ITC,两者使用权重相加

带动量的 MLM loss:
- 和 ITC 思路一样
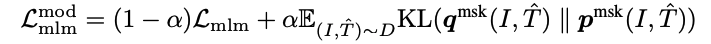
注意:加入动量蒸馏后的全部 loss 一共有 5 个!!!
图 2 展示了使用动量模型能实现的效果,伪标签其实比 gt 更能准确形象的描述这个图像中的内容

预训练的数据集:
- follow 了 UNITER 使用的数据集,CC3M(一张图一个文本),SBU(一张图一个文本), COCO(一张图5个文本),VG(一张图多个文本),总共 400w 多图片,共 510 万 image-text pairs (5.1M)
- 当作者为了验证文中提出了 pseudo-label 的效果是不是有效的,就使用了更 noisy 的 CC12M 来验证的效果,将整个图像数量提高到了 14.1M,在各个下游任务上又涨了,也证明了其有效性
下游任务:
1、图文检索:图像到文本的检索,文本到图像的检索
衡量的指标是 Recall,使用一般是 Recall@1,Recall@5,Recall@10 这种衡量方式,就是判断在检索回来的这 1 个、5个、10 个样本中,有没有真正的样本,如果有就算找到了
fine-tuning 的效果比 SOTA 要好,使用更大数据集还是更好的
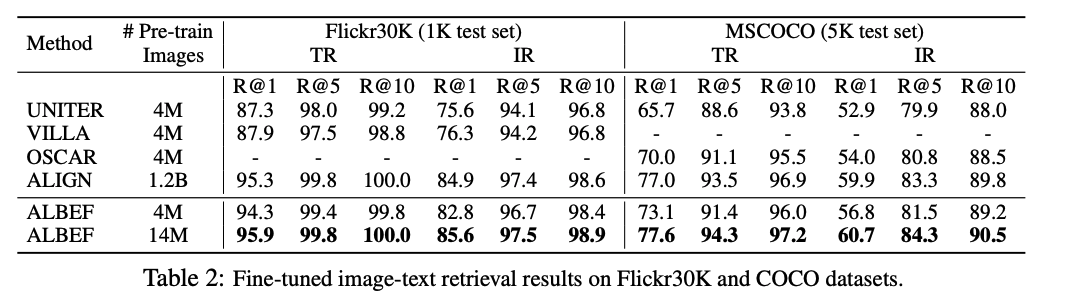
因为在 coco 上做了预训练了,所以作者只在 Flickr30K 上做了 zero-shot 测试,在 4M 上训练,zero-shot 的结果就比 CLIP 还要好
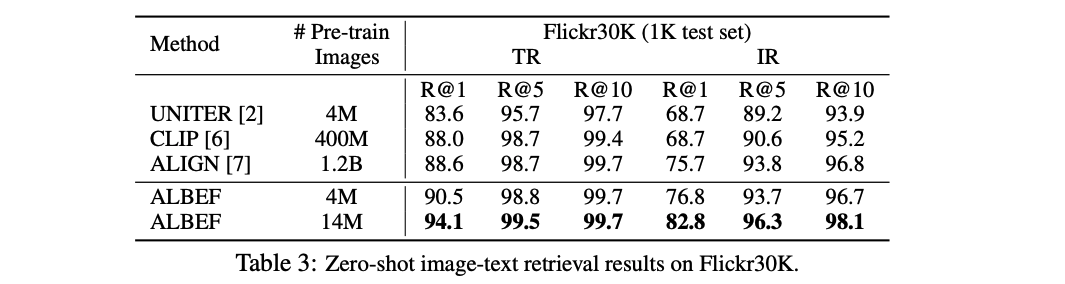
2、视觉蕴含:Visual Entialment
给定一个假设,能不能推理出来这个前提,如果能推理出来就是蕴含 entialment,如果没推理出来就是 contradictory,如果不知道能不能推出来就是中立 neutral。一般情况下都变成了3分类问题,衡量指标就是分类准确度
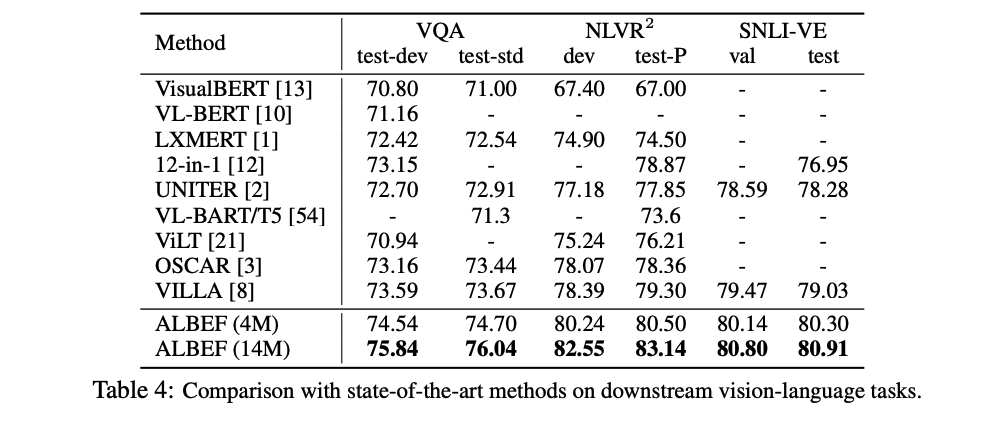
3、视觉问答:VQA
一般有两种方式来解决:
- 第一种闭集 VQA,answer 的 set 是闭合的,就是也看做分类任务,答案都是固定的,从里边去选,VQA2.0 数据集中就有设定好的 3192 个 answer
- 第二种开集 VQA,answer 的 set 是随机的,也就是为本是模型生成的,需要 decoder 生成 answer,难度就大了一些,有可能生成了很好的回答但是和 gt 不一致,那也会被判定错误
虽然 ALBEF 说能够做 answer generation 的任务,但推理的时候还是把生成的答案限制到了 3192 中,还是分类问题,衡量指还是准确度
4、视觉推理:Natural Language for Visual Reasoning( N L V R 2 NLVR^2 NLVR2)
预测文本能不能同时描述一对图像,是一个二分类任务,衡量指标也是准确度
5、Visual Grounding:视觉定位,一般视觉定位单独属于一个领域,很多做多模态表征学习的论文里都不会涉及到这个任务,专门做 grounding 的论文才会做这个任务
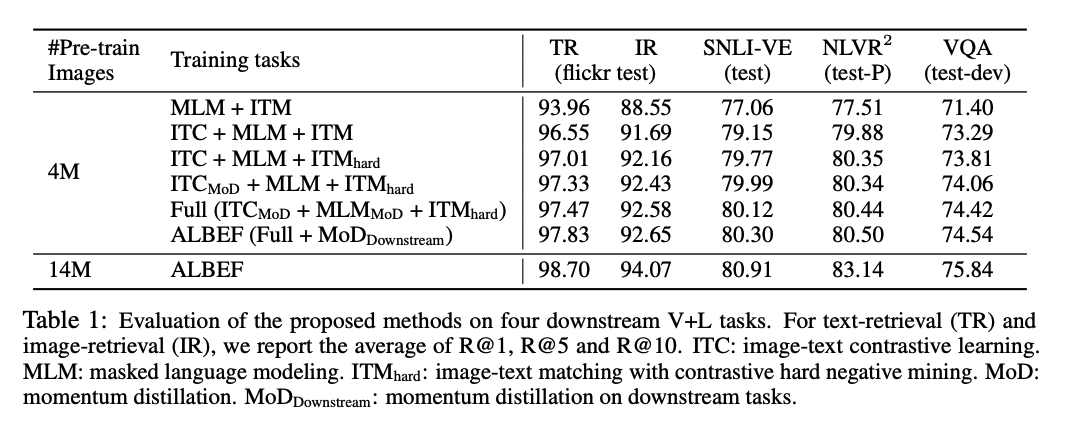
消融实验:
- 把 MLM+ITM 作为 baseline,然后加上了 ITC,在四个任务上分别提升了两三个点,所以说对比学习的 loss 是非常能打的,很有潜力
- ITM 中的 hard negative ,有约 0.5 的提升
- MoD:momentum distillation,预训练上使用 MoD,提升了约 0.3 个点,其实提升不是很大,但值得后续的研究
三、BLIP:提出了一个很好的为图像生成 caption 的方法
论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
代码:https://github.com/salesforce/BLIP
BLIP 是 ALBEF 的后续工作
题目中有两个关键词,也就是两个贡献点:
- bootstrapping:使用直接爬取的数据集,训练一个模型,然后使用模型得到更干净的数据,使用更干净的数据来训练更好的模型
- unified:统一视觉语言理解和生成任务
研究动机:
- 模型角度:最近的方法使用的就是 encoder-based(CLIP、ALBEF)或 encoder-decoder 的方法,这种 encoder only 的模型没法用到 text generation 的任务(比如为图像生成字幕)因为没有解码器的输出就没法直接的生成。encoder-decoder 的模型虽然有 decoder 能做生成的任务,不能直接的去做 image-text retrieval 的任务。所以两种框架都有限制,没法用一个模型来解决所有任务。BLIP 就是使用了 ALBEF 的很多想法,把他设计成了统一的框架,能用一个模型解决所有任务,也是利用了很多 VLMO 的想法
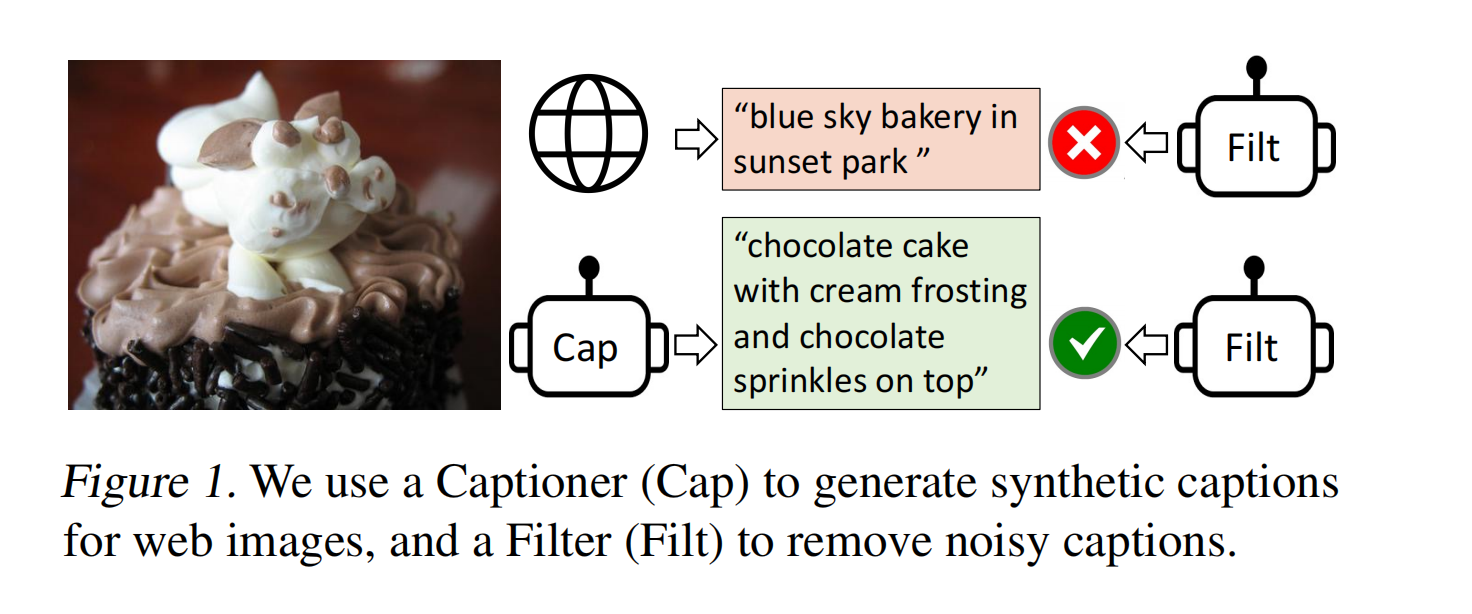
- 数据角度:当前表现好点方法 CLIP、ALBEF 等都是使用从网络上爬取的大量数据集来预训练的,虽然数据集中有很多噪声,但足够多的数据能弥补一些噪声带来的影响。但 BLIP 就证明使用这些带噪声的数据集不是最优的,于是 BLIP 就提出了 caption 和 filter model,caption 就是给图片生成文本,就能得到大量合成数据,filter model 就是将图像-文本不匹配的对删掉,如下图中的巧克力蛋糕,从网络上爬取时对应的描述是 ’blue sky bakery in sunset park’,也就是一个在 sunset 公园的叫 blue sky bakery 的蛋糕店。图文是明显不匹配的,不符合我们想要的描述。caption 模型能生成很好的描述,所以在训练的时候就使用的是 caption 生成的文本。
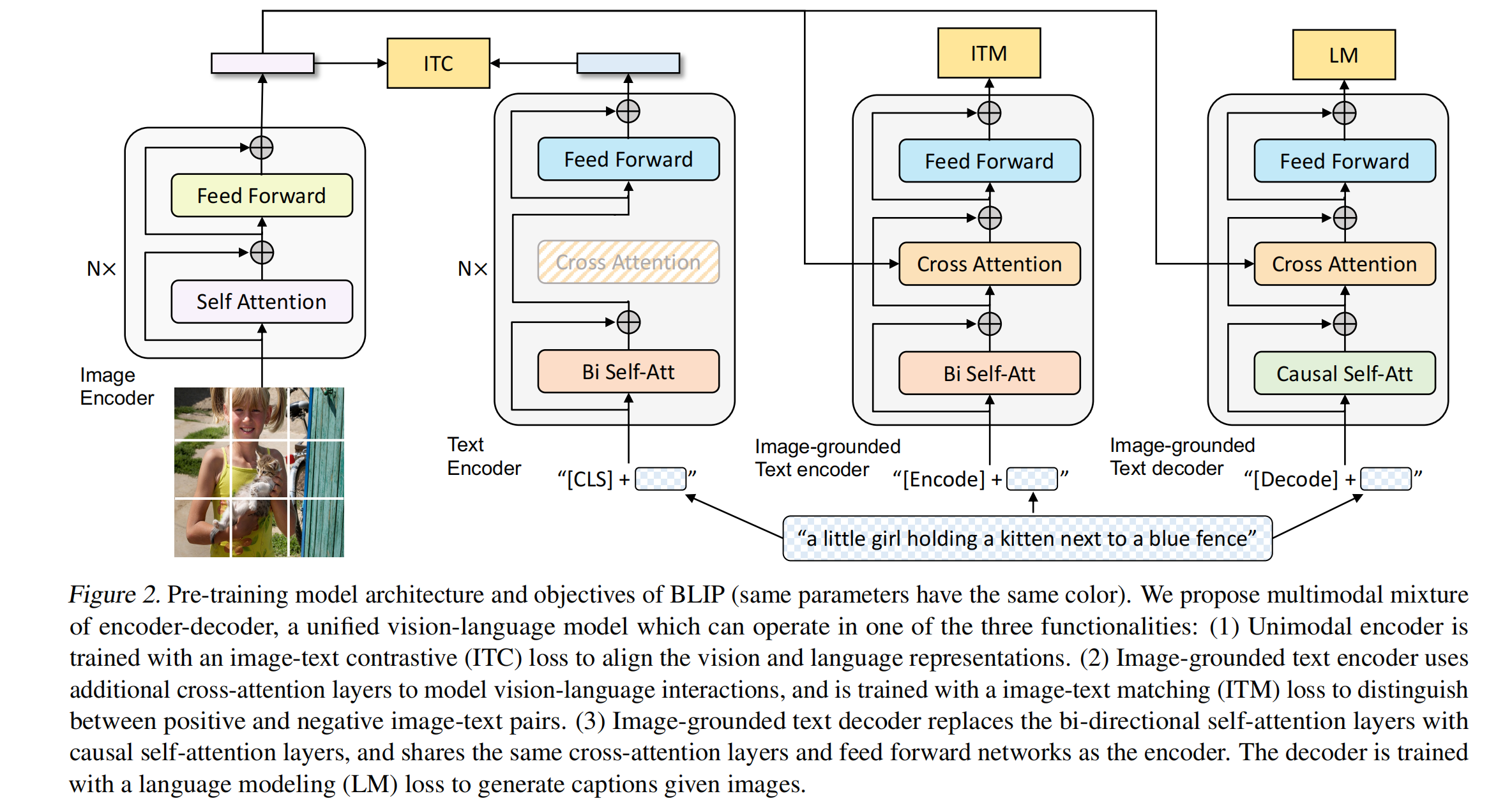
预训练框架结构如图 2:MED:Mixture of Encoder and Decoder
- 共包含了 4 个部分,图像有 1 个模型,文本有 3 个模型(分别来算 3 个 loss),每个文本模型对应的 token 是不同的,在训练的时候图像需要一次 forward,文本需要三次 forward,每次文本需要经过 3 个网络分别计算输出,训练很耗费时间
- 第一个文本模型 Text Encoder:使用 N 层,根据输入的文本进行分类的任务,就是对文本特征和视觉特征做对比学习 ITC loss,里边也用到了 ALBEF 的计算,使用了 momentum encoder 来做 distillation 和数据集的清理
- 第二个文本模型 Image-grounded Text encoder:主要做的是 VQA、VR 的这种理解任务,是多模态的编码器,借助的图像的信息来完成多模态的任务,计算的是图文匹配 ITM loss,同样的颜色是共享参数的,也就是前两个文本编码器的 attention 和 FF 都是共享的参数。这里计算 ITM 的时候也使用了 hard negative 的操作,就是计算了一个最难的负样本来作为负样本计算 ITM loss
- 第三个文本模型 Image-grounded Text decoder:做生成的任务,就是加了一个文本 decoder,绿色的 causal self-attention(推理自注意力) 输入的文本是需要 mask 的,要盖住后面的单词,只有前面的单词是可见的,根据前面的单词来推理后面的单词,这里不和前面两个 attention 共享参数(共享参数的性能会下降),后面的 Cross Attention 和 FF 都是共享参数的,计算 Language model loss,就是给定单词预测剩下的词。不同于 MLM 的扣掉词来预测这个词的方法。
对数据的处理:Caption model 和 Filter model
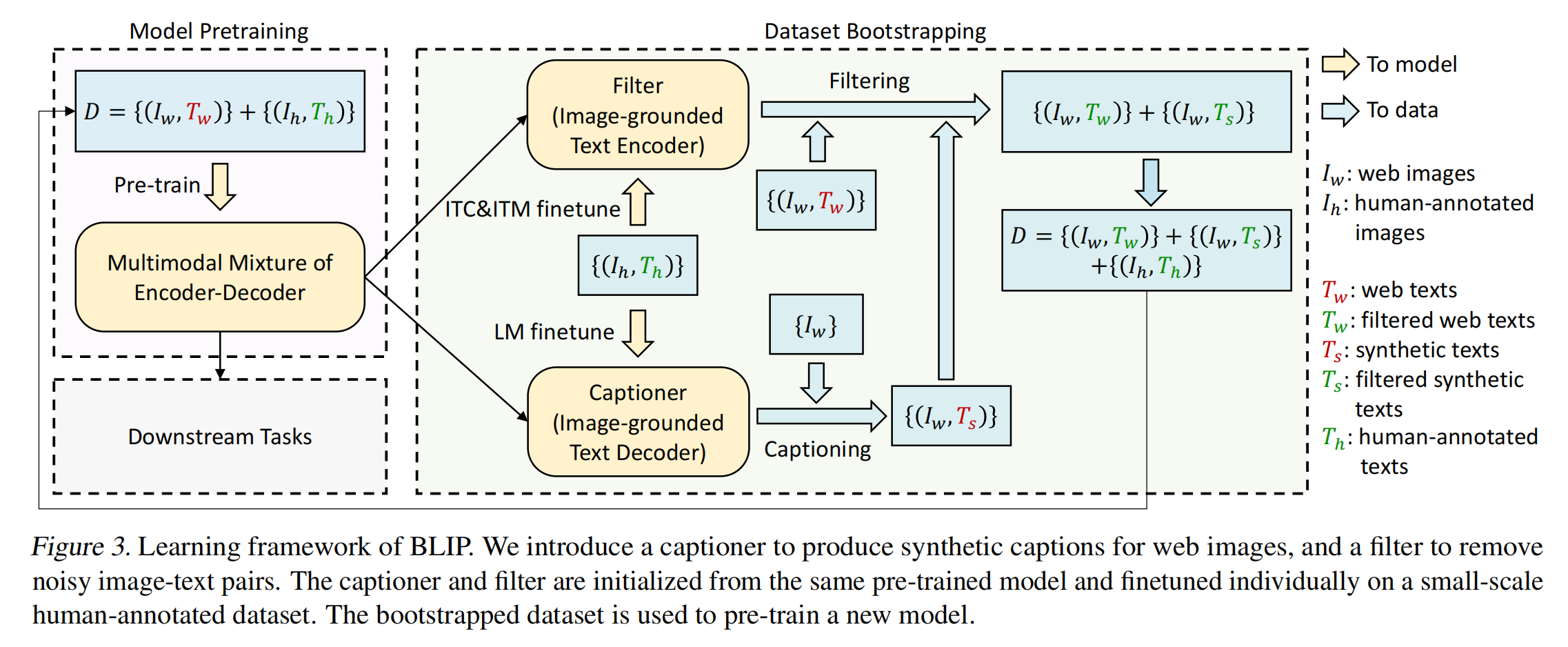
数据集 D 中有网络爬取的数据集和手动标注的数据集,最大的问题就是爬取的数据中图片-文本不匹配,作者认为 COCO 这种手工标注的数据是匹配的,使用 noisy 的数据集预训练的模型效果肯定是不够好的,所以如果想清理数据集达到最优解的话,就需要做一些操作
清理数据集的方式可以使用一个有一定能力的模型,来计算图像和文本的相似度,相似度高的就说明匹配,不高的就说明不匹配。这就是 Filter 模型的由来
Filter 模型的训练方式:使用 COCO 微调预训练好的 MED 中的前两个文本编码器来做 noisy 图文对的删除
- 先使用所有的数据集 D 来预训练一个模型,也就是图 3 左侧中间的 encoder-decoder
- 然后把其中的 ITC 和 ITM 的两个文本模型拿出来,使用 coco 这种高质量的数据再进行一次 fine-tuning,右上箭头,微调过后的 MED 就是 Filter,然后使用 Filter 计算图像-文本的相似度,就可以知道是否 match,不 match 就删掉,就把红色的 Tw 变成了绿色的 Tw
Captioner 模型的训练方式:使用 COCO 微调预训练好的 MED 中的最后一个文本编码器来做优质文本的生成
- 为什么作者要加上这个 captioner 呢,就是给图像生成文本的这个模块
- 作者发现训练好的 decoder 非常强,有时候生成的句子比原始的文本更匹配
- 所以作者也是基于预训练好的 MED ,使用 COCO 数据集进行了 LM fine-tuning,得到了微调后的 Image-grounded text decoder,用这个 decoder 来为那些 Iw \text{Iw} Iw (来自网络的图像) 生成对应的文本描述,也就是伪文本描述。
- 因为生成的伪文本描述毕竟是模型生成的,所有质量有好有坏,水平有高有低,所以作者把生成的伪文本描述和对应的图像还会过一遍 Filter,保留下来匹配度更好的伪标签
经过了 Filter 和 Caption 这两步后,可以用的数据集就变成了三部分:
- 没有被 Filter 掉的优质原始图文对(优质 Tw)
- 没有被 Filter 掉的优质生成图文对(优质 Ts)
- 手工标注的高质量图文对(如 COCO)
下图 4 中,Tw 是网络上的文本,Ts 是模型生成的文本,红色是被过滤掉的文本,绿色是被 Filter 保留下来的文本,直观看起来就能感受到模型的强大之处,说明 Filter 把数据集清理的相当好

对数据集进行了过滤和扩充后,作者使用这些优质的数据再重新预训练一个 MED ,就能很好的再次提升模型效果
模型效果展示:
主要结果和消融实验:
- 模型 backbone 保持一致的时候,数据集从 14M 到 129M 时,模型效果是普遍变好的
- 使用同样的数据集,把模型变大,模型效果也会更好
Caption-Filter 模式带来的效果:
- 不用的是最差的
- 使用 Caption 带来的描述的多样性,是更会让模型受益的,因为大模型一般都能自己消化掉 noisy,但因为模型巨大,所以一般都是 data hungry 的,非常需要大量的数据,所以使用更多更好的数据就能得到较好的受益
- 这里打对号的 B 和 打对号的 L :模型是分多阶段训练的,先使用粗糙数据预训练 MED,然后微调 Filter 和 Caption,最后再使用干净的数据重新预训练 MED。所以可以使用更大的模型 Large 来生成更好的 Caption,不用限制为 Base。也就是使用大的生成 decoder 来生成好的文本描述,来训练小的 MED。
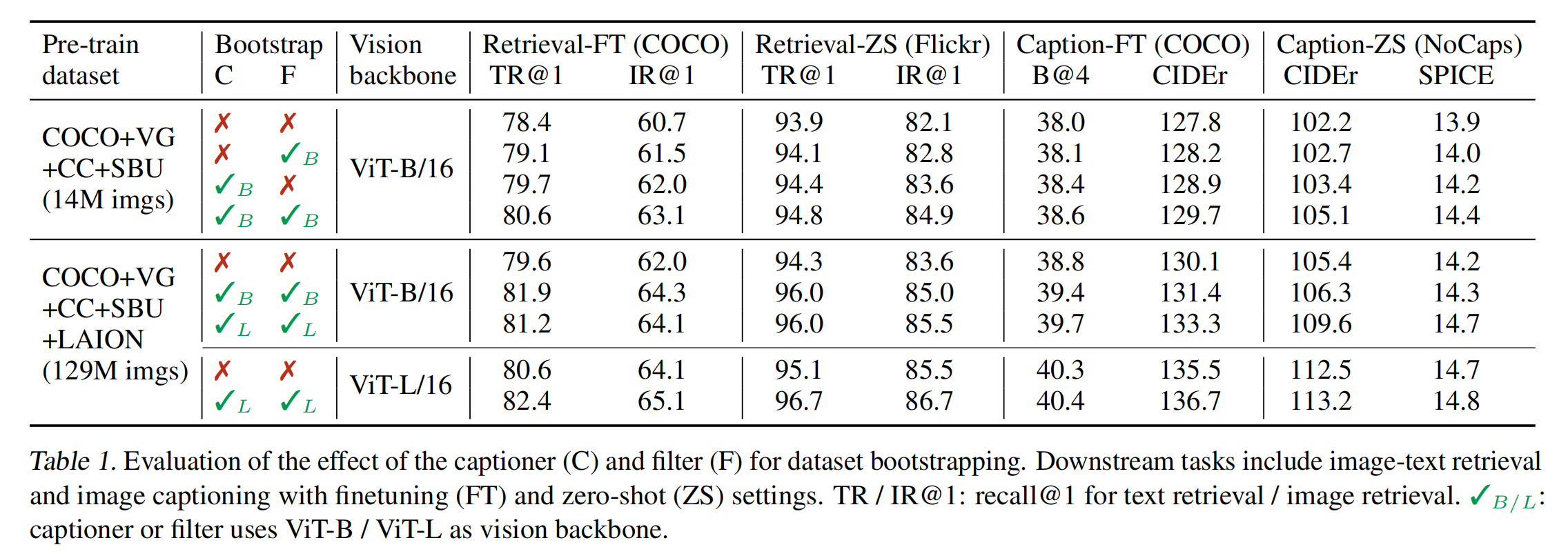
BLIP 提出的 Caption 方法非常具有普适性,很有用
四、CoCa:视觉-文本任务在模型上的统一
论文:CoCa: Contrastive Captioners are Image-Text Foundation Models
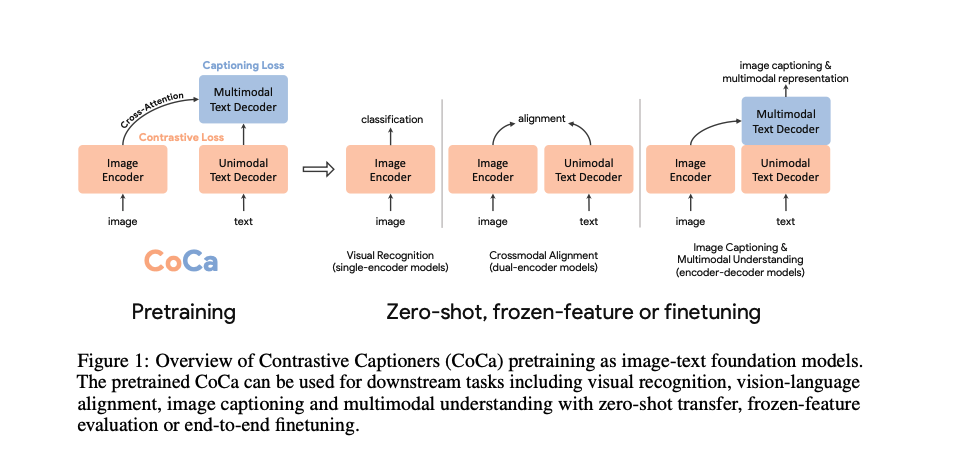
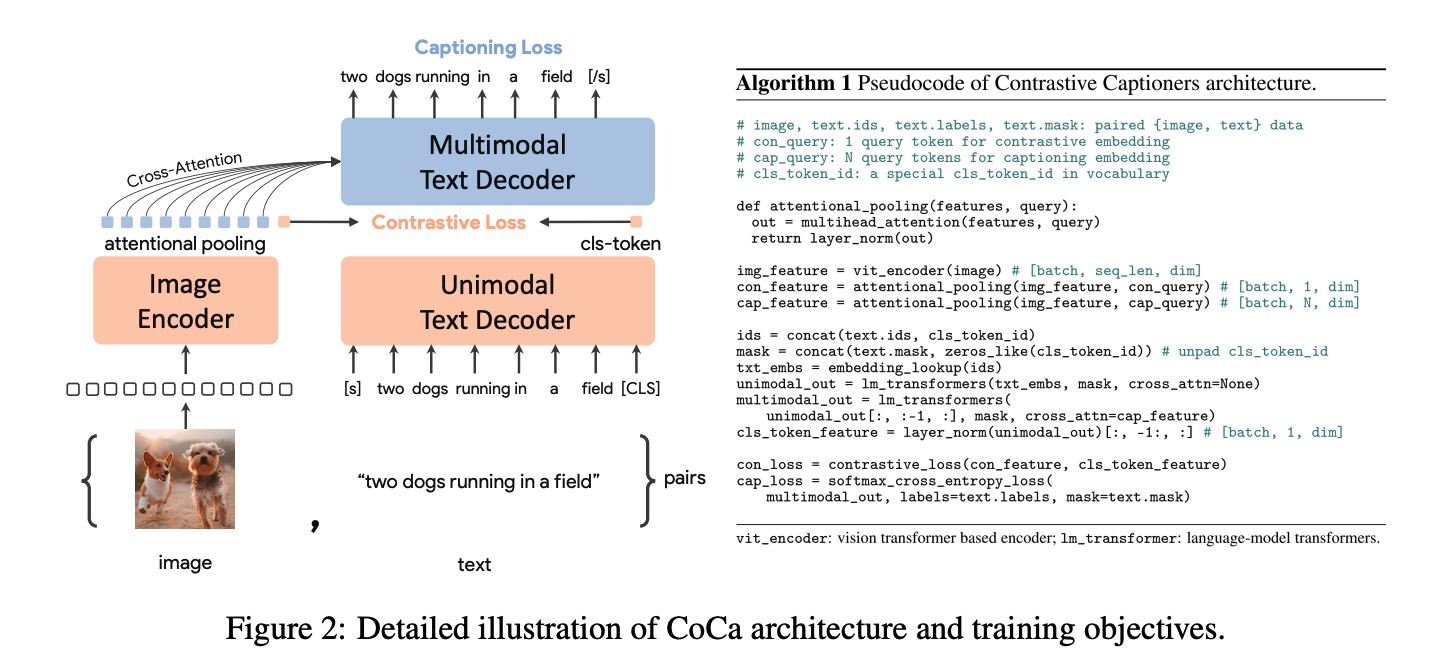
CoCa 是 ALBEF 的一篇后续工作
- 左边是 image encoder,右边是 text decoder,右边文本的部分的前一半是做 unimodel 文本的特征,后面一般是做多模态的特征。
- image encoder 是先对图像切 patch,然后使用 emcoder 来提取到一系列的 token,其中也包括 cls token,cls token 的作用是和 文本特征做对比学习,其他的蓝色小框特征进行 attention pooling 传入多模态 decoder 中做 cross-attention
- text decoder 是通过文本解码器得到文本的 cls-token
- 将第一阶段得到的图像 cls token 和文本特征 cls token 做对比学习,ITC loss
- 多模态特征的学习使用的是 Captioning loss,输入的是文本的特征和图像的特征,做 cross-attention 。这里的 Captioning loss 其实就是 BLIP 中用的 language modeling loss
- 整个模型有两个目标函数,所以就是 CoCa
CoCa 和 ALBEF 的两个区别:
- 一个明显的区别在于,这里图像特征使用了一个可学习的 attentional pooling,可学习的 pooling 能够针对不同的任务学到对应的特征,对多模态融合效果更好。
- 另外一个区别在于文本全部使用的 decoder,而且最后的 loss 是 caption loss,也就是这里文本的输入是 causal 的,也就是挡住后面的句子,只输入前面的句子。
为什么不用 ITM loss:
- 作者认为要训练更多的 loss 往往很复杂,一次训练需要多次进行前向传播,训练时间很长,代价很大
- 所以作者想要一次训练只进行一次前向传播,减少计算量和训练时间
- 所以文本的输入必须是 causal 的,这样才能保证一次前向传播能同时计算两个不同的 loss
训练数据集:几十亿的训练数据,模型大小 2.1B
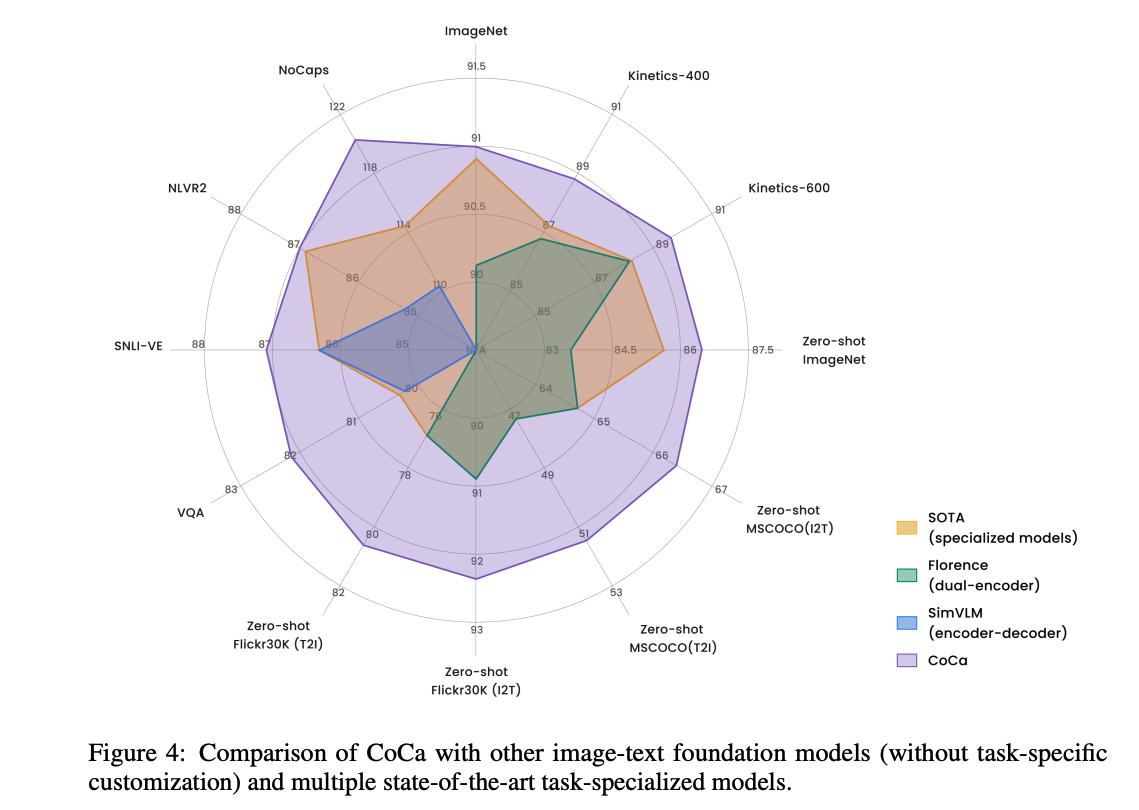
CoCa 是多边形战士,没有角的就是不能做这个任务
CoCa 比之前所有的 SOTA 在所有数据集上的效果都是最优的


五、BeiTv3:模型、目标函数、模型和数据集 scale 也要统一
论文:Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
本文的出发点:将图像也看做语言,使用一个统一的目标函数,使用的数据都是开放的(CoCa 的训练数据量几十倍于 BeiTv3)
- 把图像叫做:Imglish
- 把语言叫做:English
- 模型:Multi-way Transformer
采取了 CoCa 的多边形图,展示了效果,在每个任务上都取得了最好的,紫色的圈
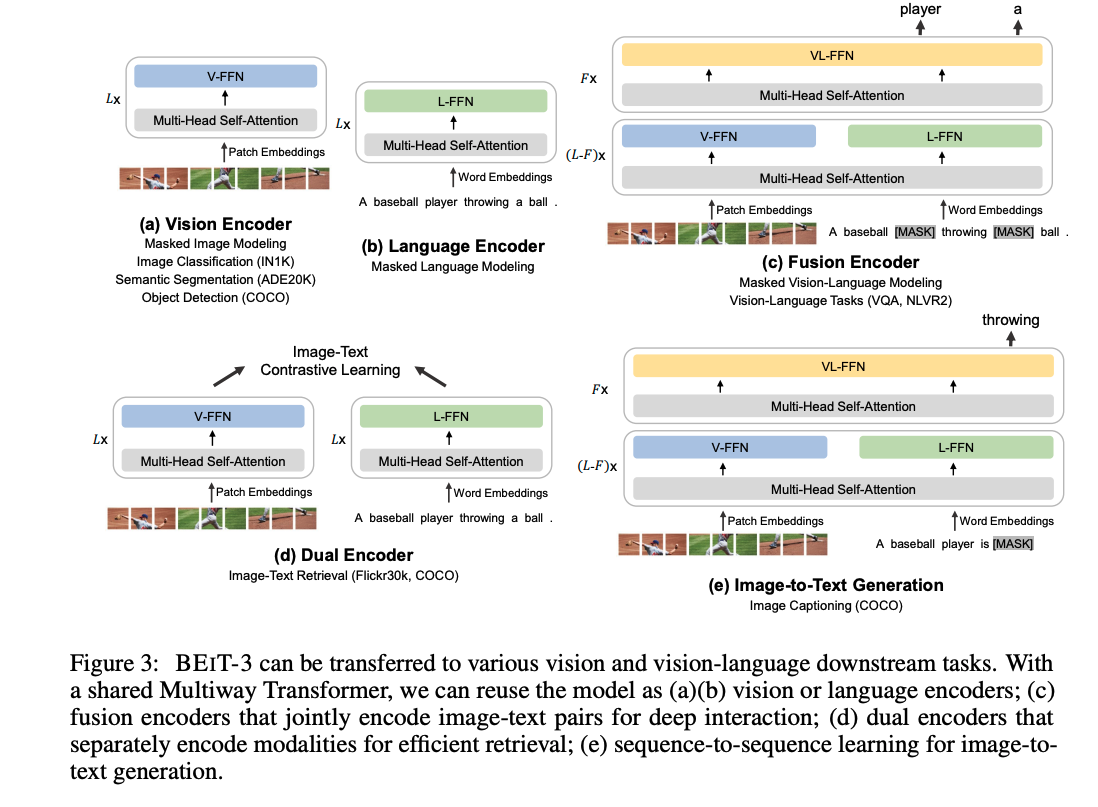
BeiTv3 是一个灵活的结构,推理的时候可以拆成各种各样的部分,可以做单模态的图像任务(分类、分割、检测)也可以做多模态的任务,也可以做语言任务
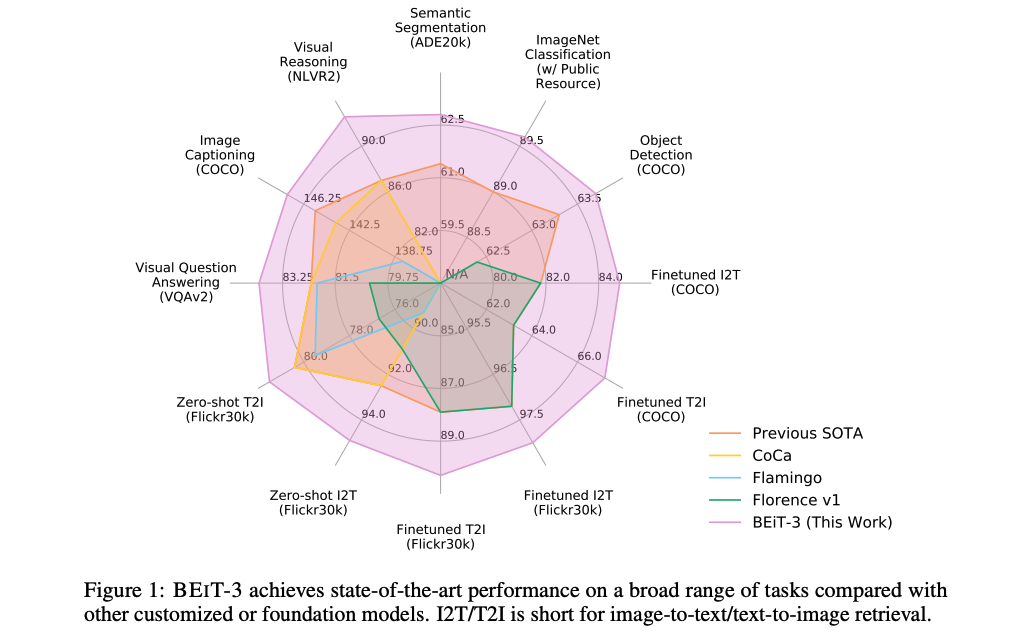
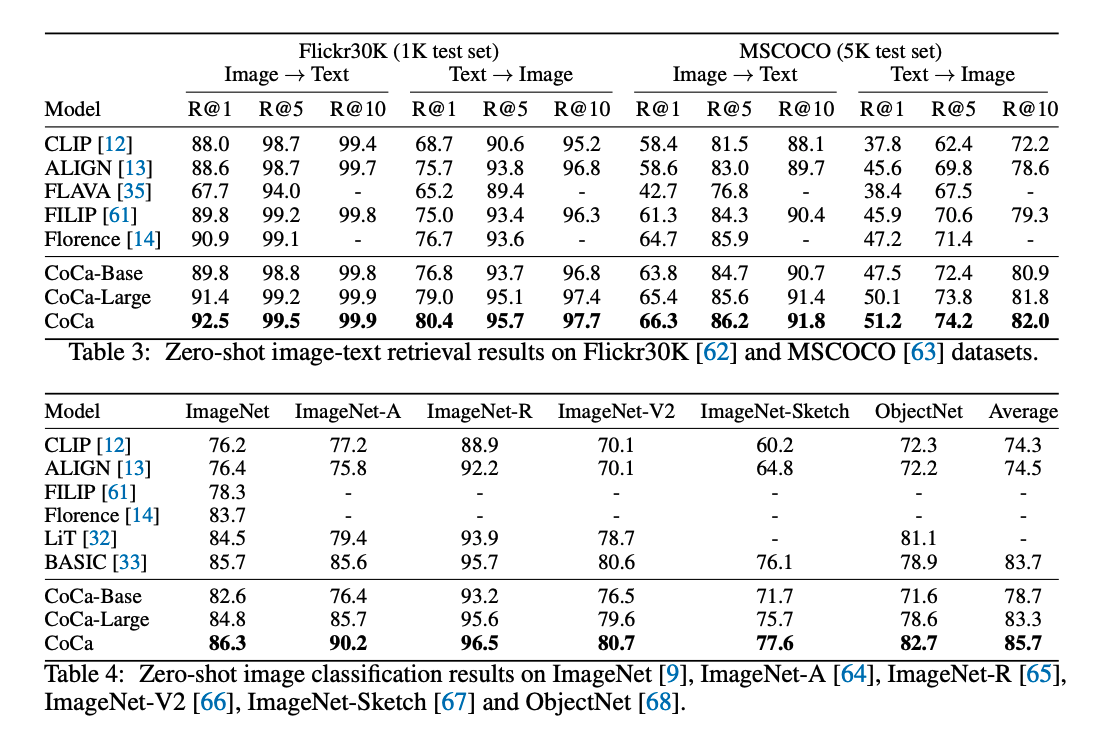
定量的展示了效果:
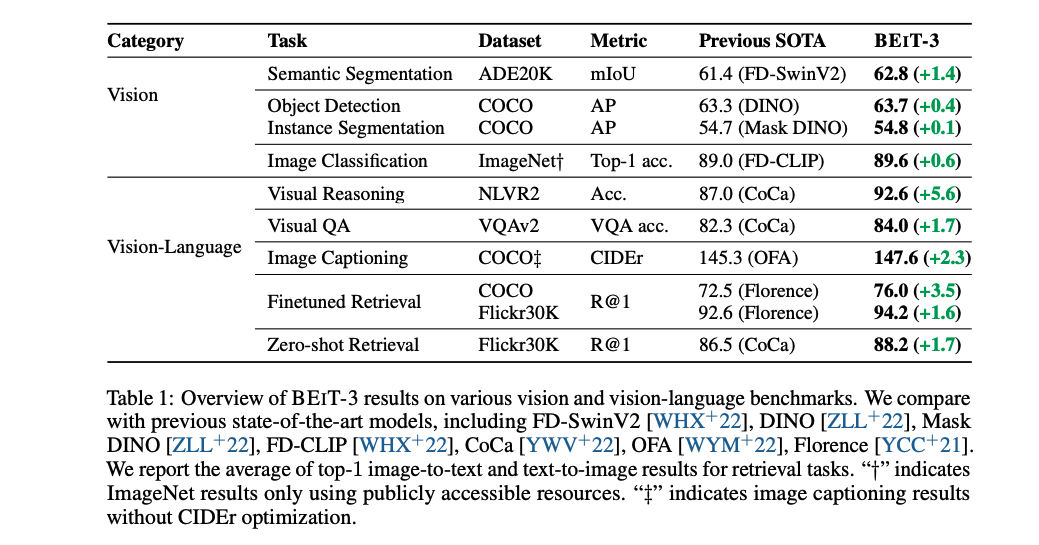
BeiTv3:做大做强统一的模型(unified framework)
出发点:
-
最近在语言、视觉、多模态任务上,大家研究大型预训练模型的热情都很高,一旦模型训练好之后,特征就能提取的非常好了,可以直接 transfer 到下游任务上去,尤其是模型足够大数据足够多的时候,就有可能训练出一个有通用性的 foundation model,性能很强大,但现在已经有了很多号称自己是 foundation model 的大模型,作者就想把这些 vision-language foundation model 进行统一,且是从下面三个方向来做统一
-
第一:模型的大一统。大一统的框架下,transformer 就更适合做多模态任务,当前多模态的模型有几种框架。但这几种不同的框架都是针对特定的任务的,需要根据下游任务来做修改,不够方便也不够泛化。所以本文作者提出了 Multiway transformer 来构建了一个大一统的模型结构
- 一种是 CLIP 这种 dual-encoder 的方式,就是有两个 encoder 进行两种模态特征的提取,然后使用简单的点乘来计算不同模态之间的相似性,适合做快速的检索任务
- 还有一种是 encoder-decoder 的架构,例如 BLIP、CoCa 等,用于做生成任务
- 第三种是 fusion-encoder 的架构,只用 encoder,如 ALBEF 和 VLMO,适合于做 image-text encoding
-
第二:目标函数的大一统。当前,基于 masked data modeling 的方法已经被用于很多模态,比如 BERT、BeiT,作者就想着能不能只用一个目标函数来把模型训练好。
- 把图像看成 language,叫做 Imglish,因为图像经过 transformer 后也是得到了 token,就能用同样的方法来处理文本和图像,在多模态中就可以把 image-text pairs 看做两个句子 “parallel sentences”,一切都变成 NLP 了。
-
第三:把模型和数据集增大(scale up)。只有用了很多的数据集和很大的模型,才有可能用一个模型解决所有的事情。在 BeiTv3 中,把模型扩展到了 billion 尺度,也最大尺度的收集了可获得的开放数据集来得到更多数据
BeiTv3 的预训练:
- 和 VLMO 的结构一样
- 使用了 multiway transformer,就是 MOME 层,前面的 self-attention 是共享参数的,不同任务的通路是不同的,参数也不共享
- 不同的输入模态决定了后面走哪一个分支
- 所有任务的目标函数都是 masked modeling,遮住图像或文本,恢复它就可以了
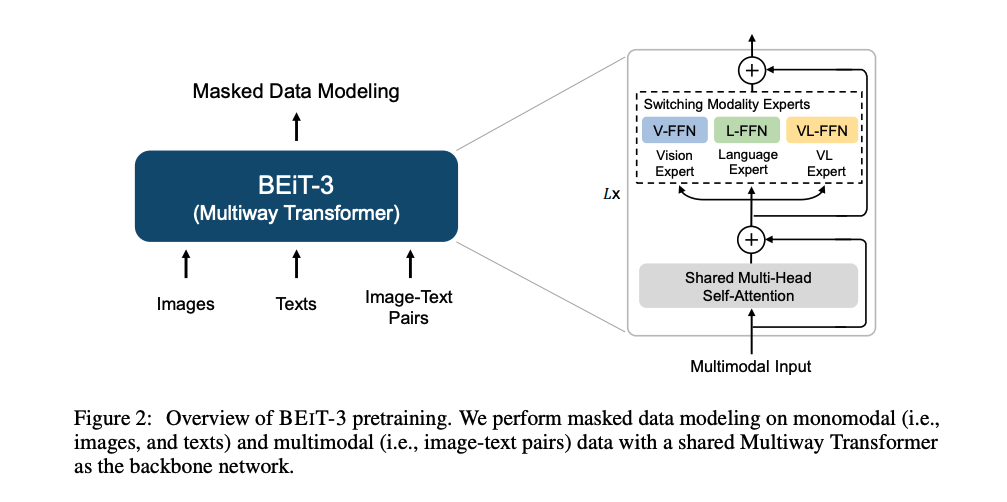
预训练完后做下游任务的 transfer:
- 只用 vision encoder(masked image modeling),就可以做图像任务,包括图像分类、图像分割、目标检测
- 只用 language encoder(masked language modeling),就可以做文本任务,BERT 能做的 BEIT 都能做
- 使用 fusion encoder,就可以做视觉理解任务,VQA、NLVR2 等
- 使用 dual encoder(类似 CLIP),就可以做高效的图文检索
- 使用 image grounded text encoder 来预测被 mask 掉的文本,就可以做文本生成任务(类似 BLIP 和 CoCa),image caption