记录下论文《BEIT: BERT Pre-Training of Image Transformers》,这是一篇将Transformer应用于图像领域,并使用自监督方法进行参数初始化的文章。
整体概要
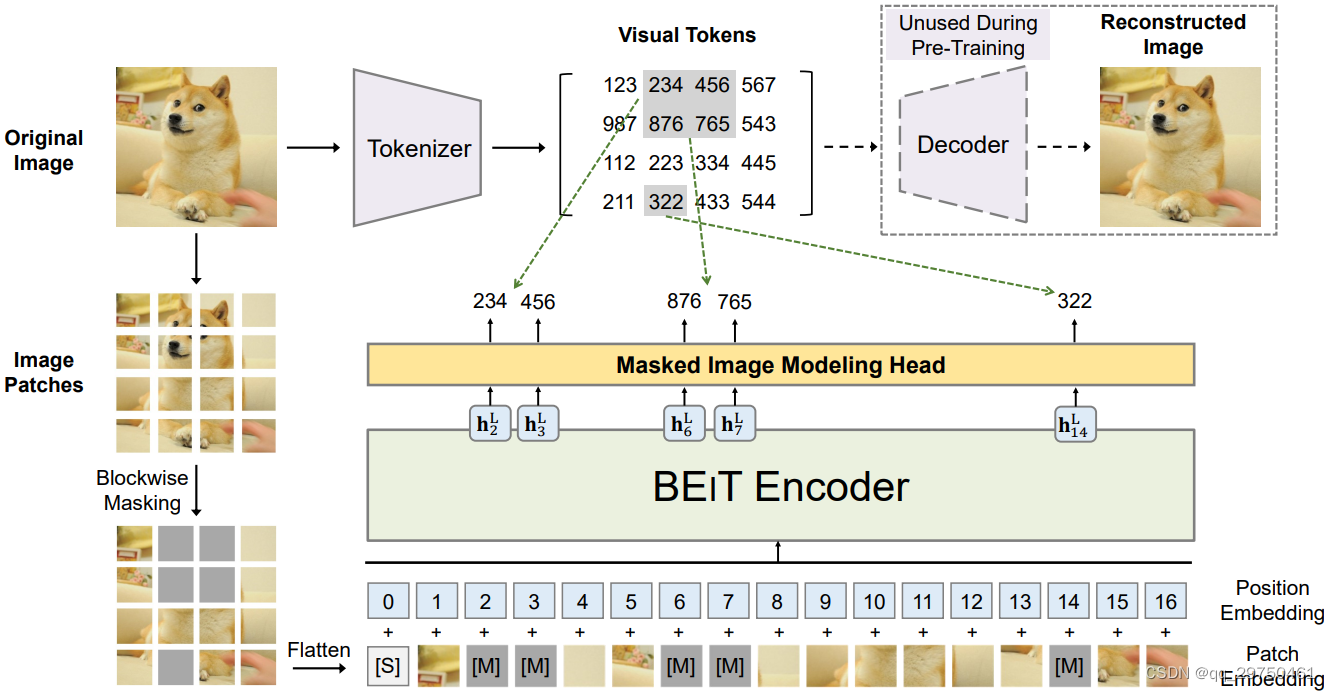
由于网络整体流程图没有标注好模型的运行过程,结合论文的描述:第一阶段为训练一个变分自动编码器,即图中的 Encoder和Decoder部分,然后保留自动编码器的Encoder部分,即图中的Tokenizer,用于生成文中提及的Token;第二个阶段为自监督训练过程,将图像分块,然后进行一定比例的随机mask(文中说遮挡40%的图像内容),然后将经过遮挡处理的图像送入Transformer进行学习,学习的目标就是完整图像送入Tokenizer得到的特征图,即让Transformer拥有一定的特征学习能力(本质上是得到具有一定学习能力的Transformer模型,即相当于对模型参数进行了合理的初始化);第三个阶段会将经过预训练后的Transformer模型进行下游任务的学习(图像分类、图像分割等),在此过程中,仅用添加下游任务相关的网络头部即可,也就是仅微调网络头部参数。
方法产生原因及存在的问题
1 文中没有直接使用Tranformer对masked图像的像素进行重构/恢复,作者认为这将会另Transformer模型更倾向关注短距离相关性(即过度关注局部特征,限制全局特征的学习)或高频去噪能力(因为模型中经过掩码后,与周围的图像形成强烈的反差或明显边缘,类似加了高频信息)。而我们一般使用深度神经网络模型一般是希望模型能够学习到抽象的特征,而不是针对某种特定任务的模型,所以这里使用自动编码器学习到的特征作为目标,训练Transformer,让其在输入有遮挡的情况下,仍然能学习到目标特征,一定程度上可认为经过预训练后的Transformer为更强大的编码器,能够对输入生成抽象的高维特征。
2 个人认为存在的问题在于文中在自监督预训练过程中,使用了随机遮挡的方法,文中提到是大约40%的图像内容被遮挡,作者并未讨论为什么大约40%内容被遮挡?此外作者在预训练模型过程中,输入端使用了一个特殊的Token [S] 并未解释该Token的用途,可能是进一步扩展模型学习的余量?
官方关键代码
官方代码链接,可以使用 git 或 svn 进行下载,比较快。
这个代码里其实看起来有些乱,但是文件命名整体上还相对较规范,可以说明一些问题。下面将结合和整体的模型相关的关键代码来说一下。
1 modeling_pretrain.py
这个文件中基本包含了模型相关的代码,整体上可以辅助我们理解模型的整体运行流程。整体上包含:PatchEmbed -> Relative position encoding -> Transformer Block
import math
import torch
import torch.nn as nn
from functools import partial
from modeling_finetune import Block, _cfg, PatchEmbed, RelativePositionBias
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_ as __call_trunc_normal_
def trunc_normal_(tensor, mean=0., std=1.):
__call_trunc_normal_(tensor, mean=mean, std=std, a=-std, b=std)
__all__ = [
'beit_base_patch16_224_8k_vocab',
'beit_large_patch16_224_8k_vocab',
]
class VisionTransformerForMaskedImageModeling(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, vocab_size=8192, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=None, init_values=None, attn_head_dim=None,
use_abs_pos_emb=True, use_rel_pos_bias=False, use_shared_rel_pos_bias=False, init_std=0.02, **kwargs):
super().__init__()
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_abs_pos_emb:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
else:
self.pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
if use_shared_rel_pos_bias:
self.rel_pos_bias = RelativePositionBias(window_size=self.patch_embed.patch_shape, num_heads=num_heads)
else:
self.rel_pos_bias = None
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
init_values=init_values, window_size=self.patch_embed.patch_shape if use_rel_pos_bias else None,
attn_head_dim=attn_head_dim,
)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.init_std = init_std
self.lm_head = nn.Linear(embed_dim, vocab_size)
if self.pos_embed is not None:
trunc_normal_(self.pos_embed, std=self.init_std)
trunc_normal_(self.cls_token, std=self.init_std)
trunc_normal_(self.mask_token, std=self.init_std)
trunc_normal_(self.lm_head.weight, std=self.init_std)
self.apply(self._init_weights)
self.fix_init_weight()
def fix_init_weight(self):
def rescale(param, layer_id):
param.div_(math.sqrt(2.0 * layer_id))
for layer_id, layer in enumerate(self.blocks):
rescale(layer.attn.proj.weight.data, layer_id + 1)
rescale(layer.mlp.fc2.weight.data, layer_id + 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=self.init_std)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=self.init_std)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
return {
'pos_embed', 'cls_token'}
def get_num_layers(self):
return len(self.blocks)
def forward_features(self, x, bool_masked_pos):
x = self.patch_embed(x, bool_masked_pos=bool_masked_pos)
batch_size, seq_len, _ = x.size()
cls_tokens = self.cls_token.expand(batch_size, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
mask_token = self.mask_token.expand(batch_size, seq_len, -1)
# replace the masked visual tokens by mask_token
w = bool_masked_pos.unsqueeze(-1).type_as(mask_token)
x = x * (1 - w) + mask_token * w
x = torch.cat((cls_tokens, x), dim=1)
if self.pos_embed is not None:
x = x + self.pos_embed
x = self.pos_drop(x)
rel_pos_bias = self.rel_pos_bias() if self.rel_pos_bias is not None else None
for blk in self.blocks:
x = blk(x, rel_pos_bias=rel_pos_bias)
return self.norm(x)
def forward(self, x, bool_masked_pos, return_all_tokens=False):
x = self.forward_features(x, bool_masked_pos=bool_masked_pos)
x = x[:, 1:]
if return_all_tokens:
return self.lm_head(x)
else:
# return the masked tokens
return self.lm_head(x[bool_masked_pos])
@register_model
def beit_base_patch16_224_8k_vocab(pretrained=False, **kwargs):
model = VisionTransformerForMaskedImageModeling(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), vocab_size=8192, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(
kwargs["init_ckpt"], map_location="cpu"
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def beit_large_patch16_224_8k_vocab(pretrained=False, **kwargs):
model = VisionTransformerForMaskedImageModeling(
patch_size=16, embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), vocab_size=8192, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(
kwargs["init_ckpt"], map_location="cpu"
)
model.load_state_dict(checkpoint["model"])
return model
2 PatchEmbed 方法,该方法在 modeling_finetune.py 中。从代码中可以看出,假设输入为224x224的话,每个patch的尺寸为 16x16,总共包含的 num_patches 为 14x14,最后模型通过一层核大小为 16,步长为16的卷积得到维度为 (768,14,14)的嵌入层,即将每个 16x16的patch映射为了14x14的768维向量。
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x, **kwargs):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({
H}*{
W}) doesn't match model ({
self.img_size[0]}*{
self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
3 RelativePositionBias相对位置编码,这个相对位置编码与SwinTransformer中的不太一样,其实就是比Swin中的相符位置编码在长和宽上增加了一维数据,即文中提及的 特殊Token [S] 的表示。
class RelativePositionBias(nn.Module):
def __init__(self, window_size, num_heads):
super().__init__()
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = \
torch.zeros(size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = self.num_relative_distance - 3
relative_position_index[0:, 0] = self.num_relative_distance - 2
relative_position_index[0, 0] = self.num_relative_distance - 1
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.02)
def forward(self):
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1] + 1,
self.window_size[0] * self.window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
return relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
4 代码中包含有Mask的操作,我们可以看下 masking_generator.py 这段代码,下面这段代码其实就是文中关于Mask部分的描述,文中说的 Blockwise mask 通过下面的算法伪代码,可以发现,该操作有最低的块数限制:16-0.4*N 块。
结合说下Mask的实现逻辑:首先确定 num_patchs 为原图划分patch后的数量,然后设置最小块数min_num_patches和最大块数max_mask_patches;然后从这个区间内随机获取需要mask的块数,当然在变化之前,还对随机选取得块数(target_area)进行了横纵比的变化,得到mask的 h和w,最后在原图中对 h,w的区域进行 mask 。此外代码中还对 mask 操作进行了限制,当目标区域全部mask为1后,就循环结束,代码中进行了10次的循环尝试,只要该过程中有mask则退出 mask的生成。
Mask代码是在数据集处理的部分调用的

import random
import math
import numpy as np
class MaskingGenerator:
def __init__(
self, input_size, num_masking_patches, min_num_patches=4, max_num_patches=None,
min_aspect=0.3, max_aspect=None):
if not isinstance(input_size, tuple):
input_size = (input_size, ) * 2
self.height, self.width = input_size
self.num_patches = self.height * self.width
self.num_masking_patches = num_masking_patches
self.min_num_patches = min_num_patches
self.max_num_patches = num_masking_patches if max_num_patches is None else max_num_patches
max_aspect = max_aspect or 1 / min_aspect
self.log_aspect_ratio = (math.log(min_aspect), math.log(max_aspect))
def __repr__(self):
repr_str = "Generator(%d, %d -> [%d ~ %d], max = %d, %.3f ~ %.3f)" % (
self.height, self.width, self.min_num_patches, self.max_num_patches,
self.num_masking_patches, self.log_aspect_ratio[0], self.log_aspect_ratio[1])
return repr_str
def get_shape(self):
return self.height, self.width
def _mask(self, mask, max_mask_patches):
delta = 0
for attempt in range(10):
target_area = random.uniform(self.min_num_patches, max_mask_patches)
aspect_ratio = math.exp(random.uniform(*self.log_aspect_ratio))
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < self.width and h < self.height:
top = random.randint(0, self.height - h)
left = random.randint(0, self.width - w)
num_masked = mask[top: top + h, left: left + w].sum()
# Overlap
if 0 < h * w - num_masked <= max_mask_patches:
for i in range(top, top + h):
for j in range(left, left + w):
if mask[i, j] == 0:
mask[i, j] = 1
delta += 1
if delta > 0:
break
return delta
def __call__(self):
mask = np.zeros(shape=self.get_shape(), dtype=np.int)
mask_count = 0
while mask_count < self.num_masking_patches:
max_mask_patches = self.num_masking_patches - mask_count
max_mask_patches = min(max_mask_patches, self.max_num_patches)
delta = self._mask(mask, max_mask_patches)
if delta == 0:
break
else:
mask_count += delta
return mask
总结
以上为BEiT论文我的一些感受,并结合关键代码进行了说明,希望可以帮到您!