DETR是将transformer机制应用到目标检测领域的算法模型。其主要思想是利用transformer的encoder-decoder架构,利用注意力机制来实现端到端获得目标检测的结果。
DETR

如图所示为DETR模型的结构,其主要由backbone,transformer block,prediction heads三部分组成。
backbone
backbone作为输入图像的初步特征提取,主要由卷积神经网络如(resnet50)完成,对于输入图像(B×3×H×W),其中B为batch_size,H,W为图像的宽高。进攻CNN提取后的特征再通过一个全连接层得到的特征图(B×HW×D,D为超参数,表示隐藏层的维度)。
transformer block
DETR使用了transformer的encoder与decoder某块,encoder部分,backbone提取得到的特征加上pos_embedding(B×HW×D)作为encoder的query,values,keys,这里与transformer中encoder的自注意力机制一样。decoder模块包括自注意力机制与交叉注意力机制两部分,这里,DETR提出了一个object query的概念(N*D,其中N为一个超参数,论文中取的100),这里的object query一定程度上起到了anchor的作用,它表示N个可能包含带检测目标的box的几何信息。自注意力部分,object query同时作为keys和values,自注意力部分的输出为Cq。decoder的交叉注意力模块,利用encoder的输出Ck加上pos_embedding作为keys和values,Cq加上object query作为query,通过交叉注意力后输出为尺寸为(B×N×D)的向量。
prediction head
我们将transformer的输出作为预测头的输入进行目标检测结果的预测,这里,我们将N个预测框的信息与ground truth看作一个二分图的最大匹配,这里N通常是一个明显大于ground truth数目的一个数,匹配失败的预测框也将其表示为‘no object’,利用匹配后的结果来计算模型的损失函数,其损失函数主要由class loss 和box loss两部分组成,class loss对所有预测框都需要计算,主要是采用交叉熵损失,box loss是对匹配成功的预测框的计算。
DETR的实现过程大致如上所示,但DETR收敛速度慢,训练速度慢,针对这一点的优化,conditional DETR和Deformable DETR推陈而至
conditional DETR
DETR收敛速度慢的一部分主要原因其高度依赖query中表示content embedding的部分。
conditional DETR的模型结构与DETR几乎一样,其主要改进存在于decoder的部分。

conditional DETR将信息解耦为空间信息与内容信息两部分,在自注意力机制模块,图中decoder embedding表示为前一层decoder的输出,将其与object query 的和作为自注意力的keys。该模型的主要改变在交叉注意力部分,首先自注意力decoder的输出作为context query部分。为了获得spatial部分,首先引入一个reference 即图中s表示预测框的中心坐标信息,s即可作为一个可学习的参数,也可以通过object query映射获得。同时上一层decoder的输出中会包含部分预测框的位置信息(本文主要认为能够获得相对于reference的宽高,位置坐标的偏移信息),因此通过一个FFN层FFN(liner+relu+liner)来获得该特征信息,再将其与ps相乘得到最后的spatial query。将context query与spatial query concat作为交叉注意力模块的最终query。encoder的输出Ck作为context keys,pos embedding 作为spatial keys,两者通过concat作为交叉注意力机制的keys与values。其余结构与DETR保持不变。
总而言之,conditional DETR的核心机制是从decoder embedding和object query中学习到一个spatial query,这个query能够帮助模型更好的定位到待检测目标的位置,从而大大提高收敛和训练速度。
Deformable DETR*
DETR训练收敛速度慢另一个可能的原因是再decoder预测检测框的交叉注意力部分,需要与整个特征图上所有元素计算注意力系数,导致计算量增大,运算速度减慢,同时,由于高复杂的的计算伴随分辨率较低的特征图,因此会损失许多图像信息,致使DETR在小目标检测上的表现并不理想,针对这一点,Deformable DETR的提出很大程度上能够解决上述两个问题。

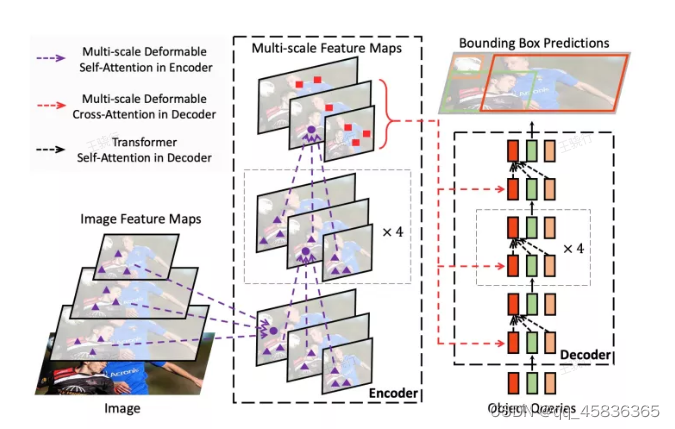
为了减少计算注意力系数时的计算量,该模型引入了一个K,表示只计算当前与K个位置上的信息的注意力系数,上图中K取3。首先是常规多头注意力机制的计算公式

式中,Wm‘为将特征转化为values的映射矩阵,Amqk即注意力系数矩阵,通常由query和keys矩阵点积获得。而该模型中的deformabel多头注意力机制的计算公式如下:

与普通的多头注意力公式相比,deformable detr中的主要变化有两点,首先不会对所有位置的像素计算注意力系数,而是只与reference point即其相关k个偏移位置(该偏移位置向量由query features映射得到)的像素特征。第二,该模型的Amqk并非是通过query与keys计算得到,而是直接由一个query features映射得到。
实际操作步骤为将query features送到输出通道为3MK的linear层,M为heads_numbers,其中前两个通道2MK即偏移向量offset的坐标信息,剩下MK通道即为Amqk。
除此之外,Deformable DETR还加入了多尺度特征的操作,l表示特征图的尺度level。
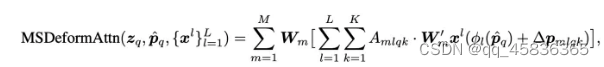
Deformable DETR的完整过程图如下所示。