DETR家族又一成员,具有可学习稀疏性的高效端到端目标检测
DETR是第一个使用transformer编码器-解码器架构的端到端对象检测器,在高分辨率特征图上展示了具有竞争力的性能但计算效率低。随后的工作Deformable DETR通过将密集注意力替换为可变形注意力来提高DETR的效率,从而实现了10倍的收敛速度和性能提升。
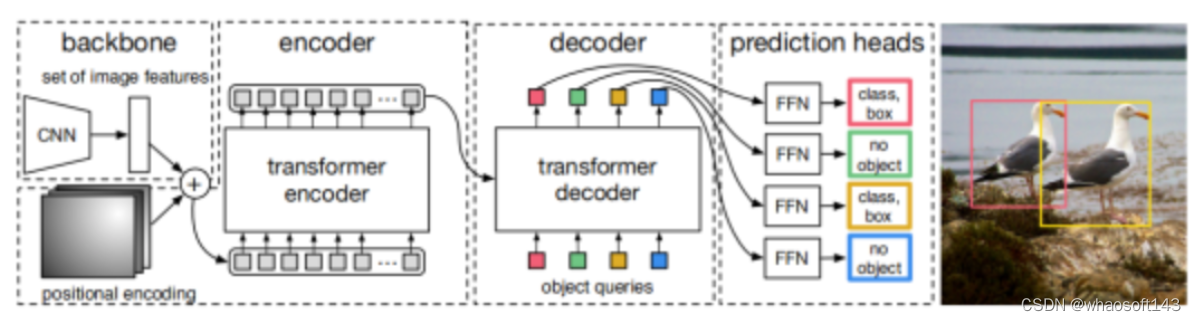 DETR
DETR
Deformable DETR使用多尺度特征来改善性能,然而,与DETR相比,encoder token的数量增加了20倍,并且编码器注意力的计算成本仍然是瓶颈。在我们的初步实验中,我们观察到即使只更新了一部分encoder token,检测性能也几乎不会恶化。受此观察的启发,研究者提出了稀疏DETR,它选择性地仅更新预期被解码器引用的标记,从而帮助模型有效地检测目标。 此外,研究者展示了在编码器中对所选标记应用辅助检测损失可以提高性能,同时最大限度地减少计算开销。我们验证了即使在COCO数据集上只有10%的encoder token,Sparse DETR也比可变形DETR实现了更好的性能。尽管只有encoder token被稀疏化,但与可变形DETR相比,总计算成本降低了38%,每秒帧数 (FPS) 增加了42%。
此外,研究者展示了在编码器中对所选标记应用辅助检测损失可以提高性能,同时最大限度地减少计算开销。我们验证了即使在COCO数据集上只有10%的encoder token,Sparse DETR也比可变形DETR实现了更好的性能。尽管只有encoder token被稀疏化,但与可变形DETR相比,总计算成本降低了38%,每秒帧数 (FPS) 增加了42%。
近年来,我们见证了深度学习中目标检测的巨大进步和成功。已经提出了多种目标检测方法,但现有算法将与GT进行正匹配作为一种启发式方法,需要对近似重复预测进行非极大值抑制 (NMS) 后处理。最近Carion等人通过基于集合的目标消除了对NMS后处理的需要,引入了完全端到端的检测器DETR。训练目标采用匈牙利算法设计,既考虑分类成本,又考虑回归成本,并获得极具竞争力的性能。但是,DETR无法使用多尺度特征,例如特征金字塔网络,这些特征常用于目标检测,以提高对小目标的检测。主要原因是通过添加Transformer 架构增加了内存使用和计算。因此,它对小物体的检测能力比较差。
为了解决这个问题,有人提出了一种受可变形卷积 (deformable convolution) 启发的可变形注意力,并通过注意力模块中的关键稀疏化将二次复杂度降低为线性复杂度。通过使用可变形注意力,可变形DETR解决了DETR收敛速度慢和复杂度高的问题,使编码器能够使用多尺度特征作为输入,显着提高了检测小物体的性能。然而,使用多尺度特征作为编码器输入会使要处理的token量增加约20倍。最终,尽管对相同的token长度进行了有效的计算,但整体复杂性再次增加,使得模型推理甚至比普通的DETR更慢。
 (a) DETR中的密集注意力需要二次复杂度。(b) Deformable DETR使用密钥稀疏化,因此具有线性复杂度。(c) Sparse DETR进一步使用查询稀疏化。Sparse DETR中的Attention也采用线性复杂度,但比Deformable DETR轻得多。
(a) DETR中的密集注意力需要二次复杂度。(b) Deformable DETR使用密钥稀疏化,因此具有线性复杂度。(c) Sparse DETR进一步使用查询稀疏化。Sparse DETR中的Attention也采用线性复杂度,但比Deformable DETR轻得多。  上图说明了如何通过预测二值化解码器交叉注意力图(DAM)来学习评分网络,其中橙色虚线箭头表示反向传播路径。左边部分展示了编码器中的前向/反向传播,右边部分展示了如何构建DAM来学习评分网络。
上图说明了如何通过预测二值化解码器交叉注意力图(DAM)来学习评分网络,其中橙色虚线箭头表示反向传播路径。左边部分展示了编码器中的前向/反向传播,右边部分展示了如何构建DAM来学习评分网络。
 稀疏DETR引入了三个附加组件:(a)评分网络,(b)编码器中的辅助头,以及(c)为解码器选择前k个token的辅助头。稀疏DETR使用评分网络测量编码器token的显着性,并选择top-ρ%的token,在上图中称为(1)。在仅精炼编码器块中选定的token后,辅助头从编码器输出中选择前k个token,用作解码器对象查询。这个过程在上图中被称为(2)。此外,我们注意到每个编码器块中的附加辅助磁头在提高性能方面发挥着关键作用。仅将稀疏编码器token传递给编码器辅助头以提高效率。编码器和解码器中的所有辅助头都经过Hungarian损失训练,如Deformable DETR中所述。
稀疏DETR引入了三个附加组件:(a)评分网络,(b)编码器中的辅助头,以及(c)为解码器选择前k个token的辅助头。稀疏DETR使用评分网络测量编码器token的显着性,并选择top-ρ%的token,在上图中称为(1)。在仅精炼编码器块中选定的token后,辅助头从编码器输出中选择前k个token,用作解码器对象查询。这个过程在上图中被称为(2)。此外,我们注意到每个编码器块中的附加辅助磁头在提高性能方面发挥着关键作用。仅将稀疏编码器token传递给编码器辅助头以提高效率。编码器和解码器中的所有辅助头都经过Hungarian损失训练,如Deformable DETR中所述。
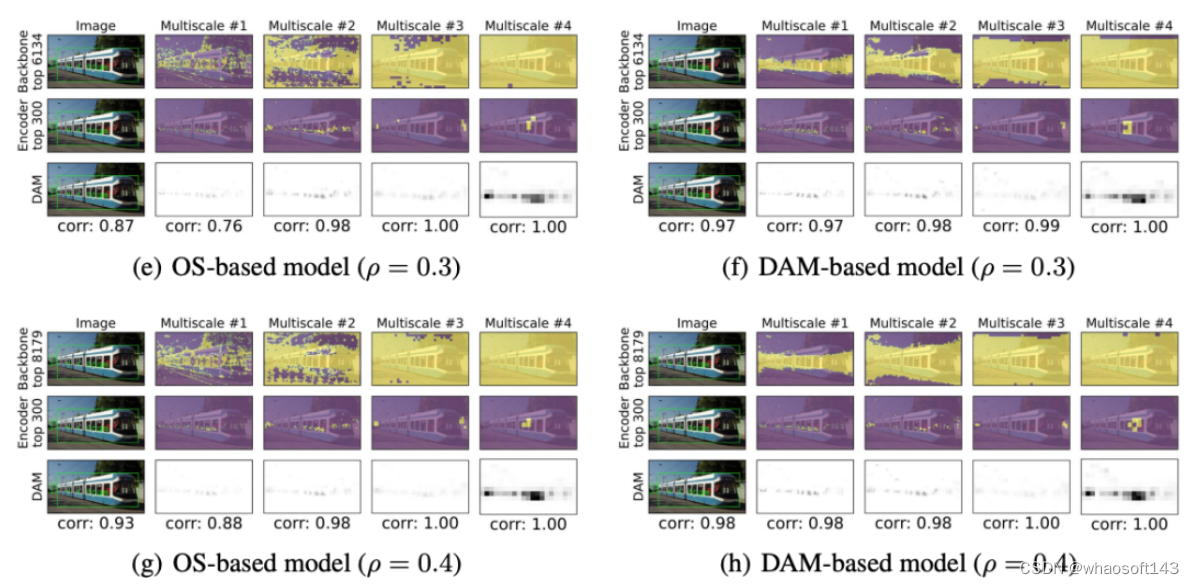
实验及可视化


whaosoft aiot http://143ai.com