Conditional DETR(ICCV 21)
Conditional DETR for Fast Training Convergence
加速detr收敛(50 epoch收敛)
DETR收敛慢的原因
DETR训练收敛速度慢,需要500 epochs
DETR的Cross Attention高度依赖content embedding(decoder的输出,可以是self attention的输出)进行定位和预测增加了对高质量的content embeddings的需求,需要很多轮才能学号content embedding,因此增大了训练的难度
Conditional DETR修改点
主要修改了decoder部分,其他部分和原始DETR保持一致

结构(只画了decoder)
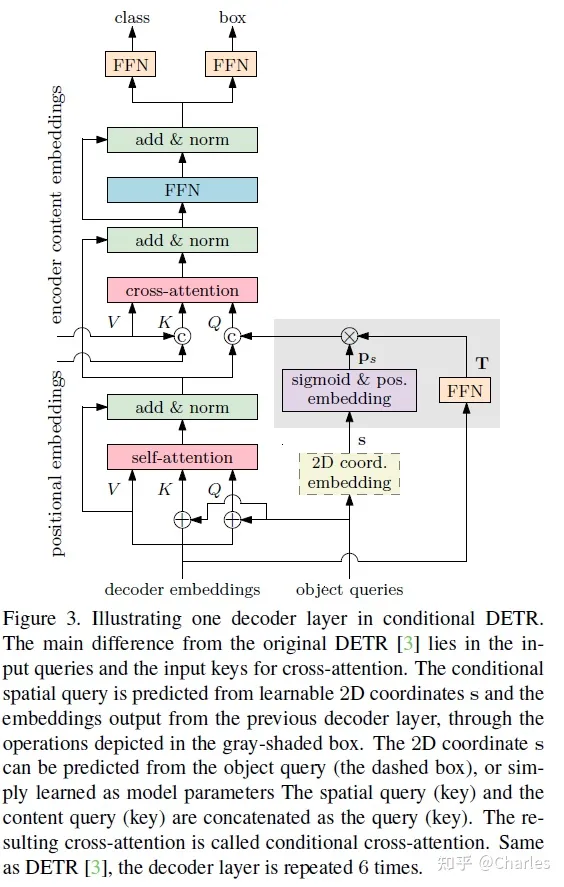
- cross attention两个换成了concat,原始的是相加
- 模块:生成新的参考点
Decoder Cross Attention
Decoder有三种输入: query key value
value是encoder的输出,称其为content embedding
key由encoder的输出t=content embedding +spatial key(空间位置编码,三角函数位置编码或可学习)构成
query由decoder的前一层(self attention)的输出=content query和spatial query(空间位置编码,也就是object query)
conditional:条件空间查询
图右侧加的额外的附加条件是2d坐标embedding
object query-> s(2d coordinates)
原始的DETR,self-attention的输出作为q,这个q需要同时在和k匹配过程中,查询出k表示的物体和识别出bbox的边界,训练时间按长。
qk计算分两个部分:一个是content计算,一个是position计算
(3d tensor相乘的计算是2dtensor对应相乘后concat)
c q ⊤ c k + p q ⊤ p k . {\mathbf{c}_q^\top\mathbf{c}_k+\mathbf{p}_q^\top\mathbf{p}_k}. cq⊤ck+pq⊤pk.
补充的条件空间查询(上面的pq,pk):有意把一份空间信息concat到self attention输出上
(s(补充的网络部分),f(self输出))->pq
p s = sinusoidal(sigmoid( s ) ) \mathbf{p}_s=\text{sinusoidal(sigmoid(}\mathbf{s})) ps=sinusoidal(sigmoid(s))
sigmoid之后空间位置编码(三角函数)
算完ps之后和T做运算,算q:
p q = T p s = λ q ⊙ p s \mathbf{p}_q=\mathbf{T}\mathbf{p}_s=\lambda_q\odot\mathbf{p}_s pq=Tps=λq⊙ps
T的FFN的输入是上一层decoder的输出,λq的值是经过FFN得到的
ablations-projections T:

full就是标准矩阵的意思,最后是只训练对角的参数值
输出和deformable detr相同,都是相对于参考点的修正
参考:
https://www.bilibili.com/video/BV1sj411K7Mj/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d