TensorRT加速Deformable Detr实践
自TensorRT 8.4.1.5发布以来,惊喜的发现TensorRT官方实现了可变形transformer的插件。
这让TensorRT便捷实现加速Deformable Detr乃至今年(2022年)最新的DETR类sota模型DINO、Mask DINO成为了可能。查了一下当前网络上并没有关于Deformable Detr 的TensorRT加速的实现方法,可能大佬们都觉的太简单没有必要吧,于是就自己写了一版方便大家使用。源码地址放在了github上: https://github.com/talebolano/Tensorrt-Deformable-Detr。
我使用的Deformable-Detr pytorch模型来自于mmdetection库,没有使用官方的原版。自己代码主要贡献了MultiScaleDeformableAttention层的onnx导出,通过实现一个伪MultiScaleDeformableAttention层进行symbolic的注册:
class Etmpy_MultiScaleDeformableAttnFunction(torch.autograd.Function):
@staticmethod
def symbolic(g,value, value_spatial_shapes, value_level_start_index,
sampling_locations, attention_weights, im2col_step):
return g.op('com.microsoft::MultiscaleDeformableAttnPlugin_TRT',value, value_spatial_shapes, value_level_start_index,
sampling_locations, attention_weights)
@staticmethod
def forward(ctx, value, value_spatial_shapes, value_level_start_index,
sampling_locations, attention_weights, im2col_step):
'''
no real mean,just for inference
'''
bs, _, mum_heads, embed_dims_num_heads = value.shape
bs ,num_queries, _, _, _, _ = sampling_locations.shape
return value.new_zeros(bs, num_queries, mum_heads, embed_dims_num_heads)
@staticmethod
def backward(ctx, grad_output):
pass
注册后的MultiScaleDeformableAttention层可实现onnx导出,如下图所示:
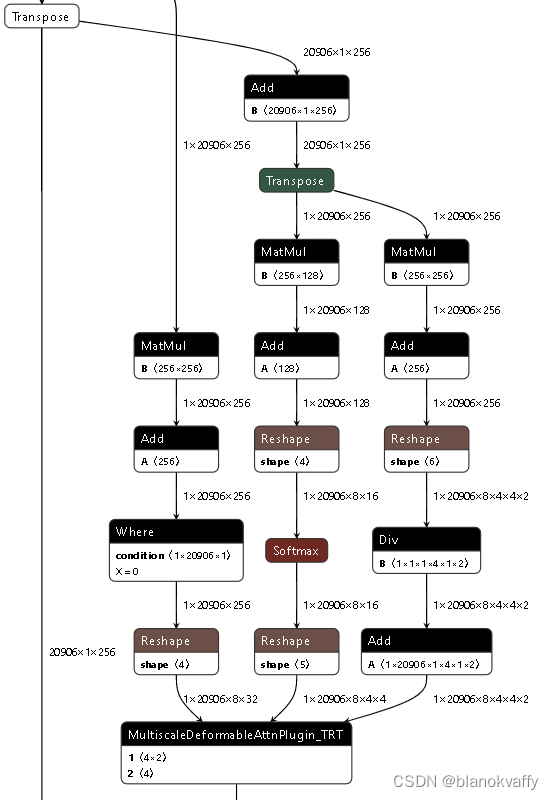
之后的转TensorRT就直接利用官方插件即可,没有任何困难。对于低于8.4.1.5的TensorRT版本,也可以选择把官方的插件自己编译到旧版本上。TensorRT加速后的Deformable-Detr模型的速度和效果如下图和下表所示:
| GPU | Model | Mode | Inference time |
|---|---|---|---|
| 3090 | deformable_detr_twostage_refine_r50_16x2_50e_coco | fp32 | 35ms |
| 3090 | deformable_detr_twostage_refine_r50_16x2_50e_coco | fp16 | 17ms |

如果感兴趣就帮我加一颗星吧。