〇、前言
关于环视相机到BEV的转换是视觉BEV感知的难点。主流方法有深度估计LSS,以及基于深度学习的方法,比如利用transformer把multi-camera转换成BEV的BEVFormer,这也是今天介绍的对象。
说到BEVFormer就不得不说到Deformable DETR,因为BEVFormer中的deformable attention来自于Deformable DETR,而说到Deformable DETR就不得不说到DETR,因为Deformable DETR中利用transformer完成图像目标检测的思路来自DETR,所以,这篇博客介绍的顺序是DETR→Deformable DETR→BEVFormer。
一、DETR
DETR是利用transformer完成2D图像目标检测的经典之作。
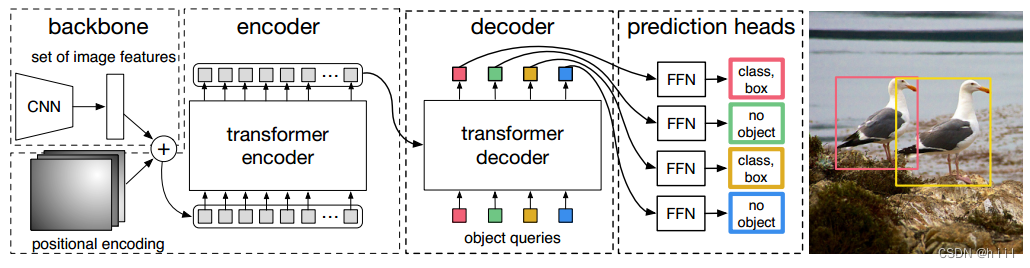
架构如图所示,主要分为三个部分(1)一个CNN主干(2)标准的transformer的encoder和decoder(3)检测头。整体流程如下:
(1).把输入图像(h,w)先经过一个CNN backbone的处理,生成原始的图像降低分辨率后的特征。特征CHW分别为(2048,h/32,w/32)为了方便后面的transformer处理,把特征拉伸成(1×HW)的query。进入encoder之前加上位置编码。
(2).encoder就还是原始的没有改变,encoder中的q和k都是图像的特征图,从encoder中输出的特征就是编码完成的特征了。而decoder依然有两个输入和两个注意力模块,N个目标query从下面平行输入(依然要加位置编码,但不是自回归了),经过自注意力后输出作为交叉注意力的q,而encoder的输出作为交叉注意力的k。注意,这段看不懂的去看一下transformer。
(3).最后是检测头,经过FFN和softmax之后,就可以预测出bounding box(x,y,w,h)了。
虽然这个方法把transformer植入到目标检测中去,省去了很多设计的细节,但是由于多次的全局自注意力和交叉注意力的使用(没有筛选,全都要算注意力),导致了检测性能低,收敛速度慢。于是便有了Deformable DETR。
二、Deformable DETR
Deformable DETR,像名字中展示的那样,使用了deformable attention,一种可以只关注一小部分的关键采样点的注意力机制。获得了更好的检测性能和更快的收敛速度。结构图如下所示

在介绍模型的处理流程之前,我们先了解一下什么模型中多次用到的deformable attention module到底是什么,先上图:
这幅图也是整个方法的核心,它与普通的attention module的区别就在于:普通的attention module会查看全局的特征,而deformable attention module只会关注一小部分关键的有用的采样点,从而提高性能,加快收敛。可以看到,上图展示的有两个值得注意的地方,一个是sampling offset,另一个是attention weight。当我从输入的特征图中确定了要处理的query之后,这个query就作为这次处理的reference point。然后:
(1).以这个点位参考,去找与他相对位置为△Pmlqk的点来做注意力处理(自注意力或交叉注意力)。
(2).做完之后需要分配每个点的权重值,通过权重值来表示每个点的重要程度。这个权重值attention weight也是需要学习的参数。
注意:文章中又提到的multi-scale deformable attention module实际就是多尺度采样。
知道了deformable attention module是什么东西之后,下面就可以看这篇文章的架构了。
我这里把它分成四个部分:(1)CNN backbone(2)encoder(3)decoder(4)head,具体流程如下:
(1)利用ResNet提取多尺度图片特征图。
(2)encoder的输入是上一步backbone的输出,encoder中的注意力模块用multi-scale deformable attention module代替,q和k均为特征图中的点。
(3)decoder既有自注意力模块,也有交叉注意力模块,其中自注意力模块不变,处理下面输入的目标query,输出作为交叉注意力的q,而encoder 的输出作为交叉注意力的k,交叉注意力模块用multi-scale deformable attention module代替。
(4)head预测bounding box
三、BEVFormer
至于为什么这么详细地介绍Deformable DETR,是因为BEVFormer跟它的结构十分相似,只做了不大的修改,我们一起来看一下。

我们先把一样的地方剔除,只看不一样的地方,这样既能融汇理解,又能减少工作量。首先backbone基本是一样的,只是这里要处理6个环视相机,把他们变成推向特征图。其次decoder和head基本是一样的,这里取消了多尺度,用了单一尺度特征输入到decoder中,并且把head中的2D bounding box变成了3D预测。这样一来,不一样的地方就只剩encoder了。至于不一样的原因,主要是因为不但涉及到编码,还涉及到视角转换,在Deformable DETR中,只是把一幅图进行encoding,不涉及视角转换,而BEVFormer中要把n个环视图编码的同时转换成BEV图。
BEVFormer 的 Encoder
按照论文所说的,编码器的创新点在于在原始transformer的注意力上改进产生了BEV query,空间交叉注意力( spatial crossattention)和时间自注意力(temporal self-attention)。
(1).BEVquery:任务是要建立平面中的点与BEV空间下点的关系,设BEV空间是一个HWC的序列。BEV中每个处理的点称为BEV query,维度为1×C,位置为Pxy。每个BEV中的点在现实中都有对应。
(2).空间交叉注意力:如果计算一个BEV query与所有feature的注意力,那就是DETR做的事情,改进方法Deformable DETR中已经说了,因此这里利用Deformable attention改进的spatial cross-attention来计算注意力,即计算BEV query与其中若干个feature map中的投影点周围若干个采样点做注意力,即被选中的每一幅feature map中才用一次Deformable attention,被选中的feature map 称为Vhit。还有两个注意点:a.选Vhit是根据BEVquery的位置和n个相机的位置来对应的。由BEVquery到特征图的投影点利投影公式Ppij计算。b.因为Deformable attention是针对2D,这里面对3D时,先把BEV变为柱,然后进行多次查询,可以理解为多头,每个BEV query进行4次。
(3).时间自注意力:移动主体目标检测中,历史信息异常重要,上一时刻的信息对这一时刻有重要的参考意义。因此这里有了时间自注意力。当有了t时刻的BEV序列和保存的t-1时刻的bev特征之后,就可以利用自注意力构建从t-1到t时刻的关联。利用上一时刻的编码结果来增强这一时刻的输入的表示。当然,这里的自注意力依然用的是Deformable attention。这样一来就把连续时间的变化利用起来了。做法是先把t-1时刻与query对齐,然后融时间自注意建立当前BEV query与上一时刻BEV特征的关系。
(4).注意,这两者的先后顺序,是先根据上一时刻的BEV特征利用时间自注意力来增强初始化这一时刻的输入,然后把这一时刻的输入作为BEV 待查询特征query的合集,然后进行空间交叉注意力用feature来表示BEV query。这样做,与普通的堆叠相比,降低了计算成本,减少了干扰信息
(5).得到的特征就是encoder的输出了,接下来就是用decoder解码并做预测了,挪用Deformable DETR 的后半部分,把2D预测改为3D预测即可。
总结一下,DETR是把transformer用于目标检测的经典文章,Deformable DETR利用筛选性的注意力计算方法降低了计算量。BEVformer在encoder中把多视角相机编码的同时转换为BEV视角,并做3D预测。