RNN
很难并行化处理
Transformer
1、Input向量x1-x4分别乘上矩阵W得到embedding向量a1-a4。
2、向量a1-a4分别乘上Wq、Wk、Wv得到不同的qi、ki、vi(i={1,2,3,4})。
3、使用q1对每个k(ki)做attention得到a1,i(i={1,2,3,4}),q1、k1,q1、k2,…,还要做一个归一化操作。
4、把计算的a1,i做softmax操作,得到~a1,i,然后把它a1,i和所有的vi值相乘,然后相加得到b1,依次计算后得到bi。
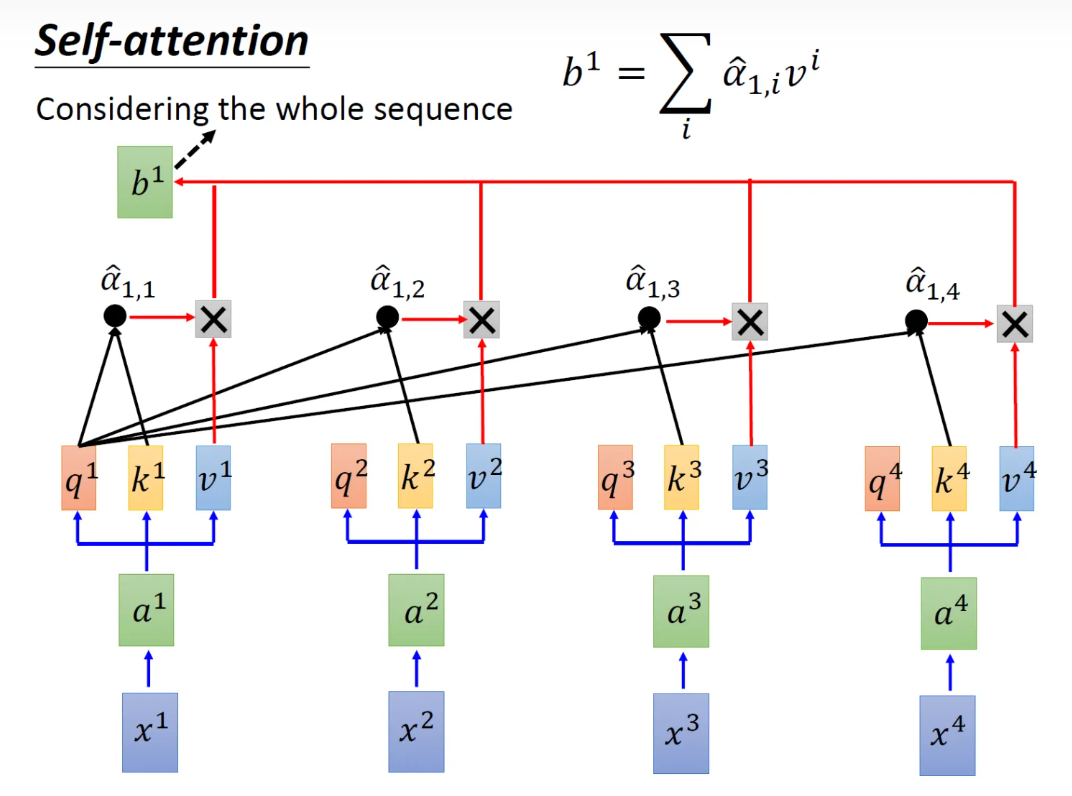

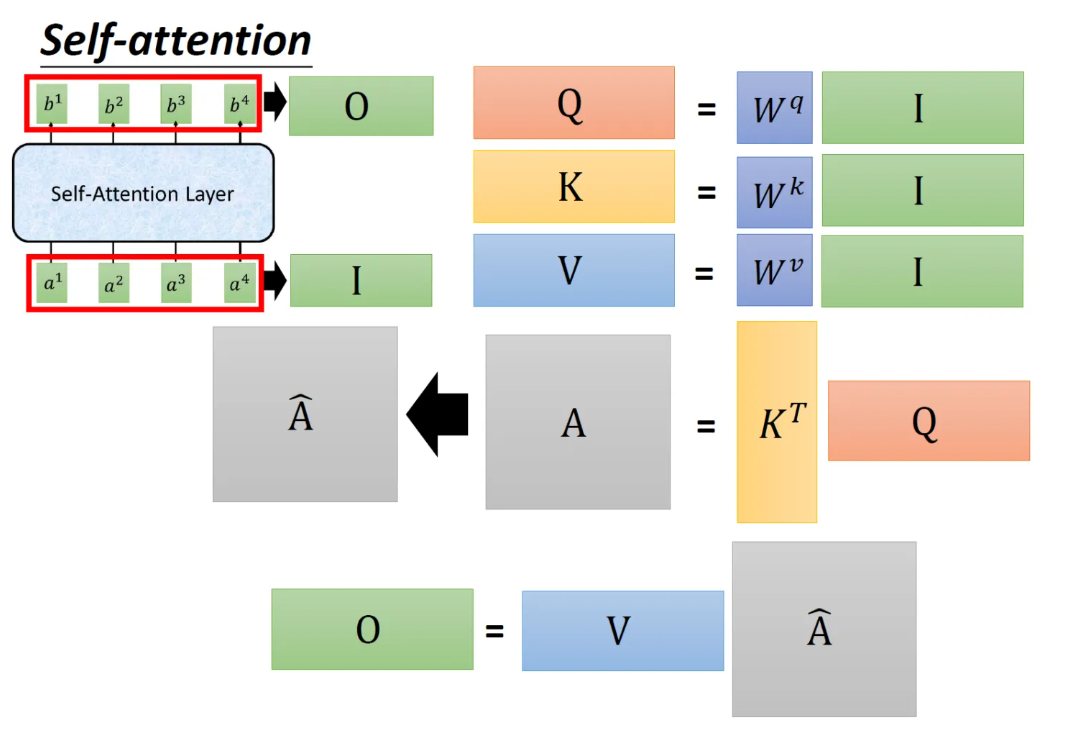
Multi-head self-attention
在self-attention的第二步,分别乘以多个wq、wk、wv矩阵得到qi,j、ki,j、vi,j。
位置编码
position emb
DETR
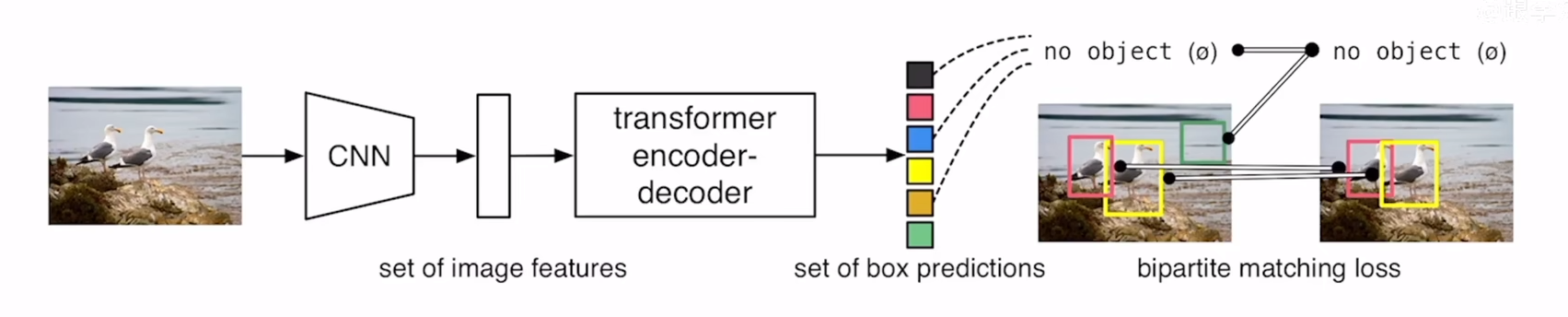
1、用CNN去提取特征
2、用transformer-encoder做编码提取全局泽正
3、用transformer-decoder生成预测框子
4、用框子和GT做二分图的loss