DETR是facebook发表于ECCV2020的使用Transformers进行端到端的目标检测的框架。

DETR只需要使用CNN提取图像特征,再单独使用Transformer就可以预测出目标边界框和分类。它不需要非极大值抑制,也不需要Anchor机制。

上图是DETR的网络架构图,DETR使用CNN提取图像特征,再单独使用Transformer得到预测出目标边界框,边界框和ground truth看作是一个几何预测问题。就是一个二分的匹配(bipartite matching),没有匹配上的物体归位no object这一类。
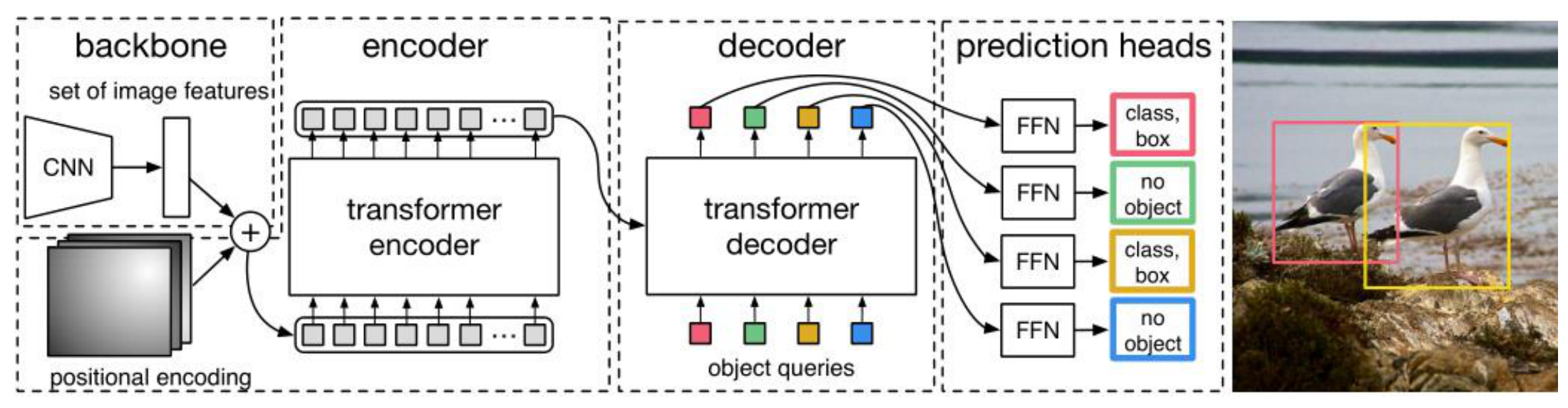
上图是更详细的描述DETR的网络结构,图像经过CNN获取到特征,再加上位置编码(poositioonal encoding),然后再展平送入到transformer encoder,encoder的输出再送入到transformer decoder,在decoder中还有object queries的输入,decoder的输出送入预测头(prediction heads),预测头中有前馈神经网络FFN进行物体类别和边界框的预测。
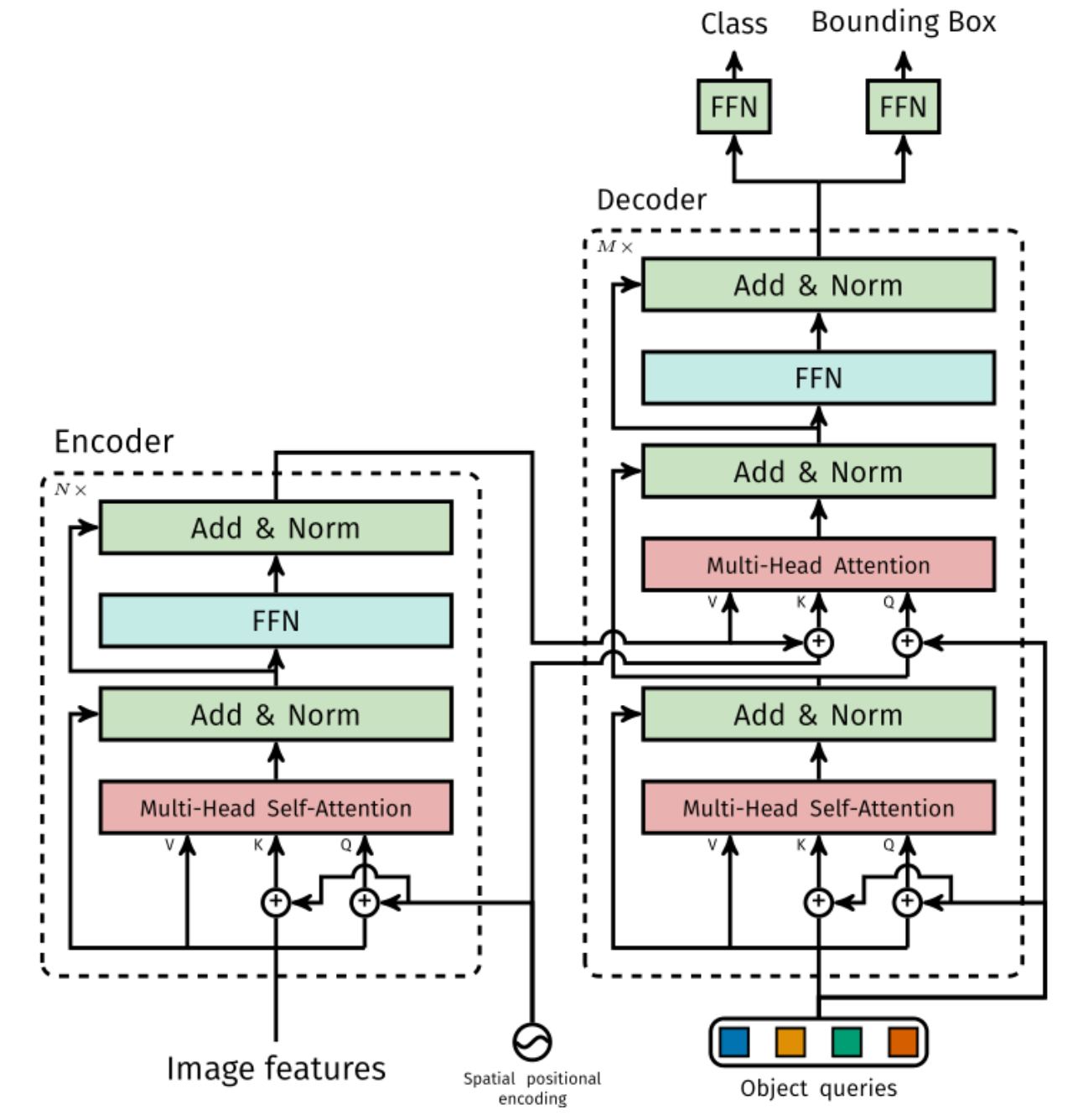
上图是DETR中Transformer具体的架构,它有Encoder和Decoder两部分,Encoder的输入就是CNN提取的图像特征加上位置编码,送入多头自注意力模块,再送入前馈神经网络模块。这样的Encoder层可以有多个,然后再送入Decoder,Decoder有Object queries,是可学习的位置嵌入作为输入,经过多头自注意力模块,再经过Encoder和Decoder之间的多头互注意力模块,再送入前馈神经网络处理。Decoder层也可以堆叠多个,最后送入前馈神经网络FFN进行物体类别预测和边界框的预测。
{{o.name}}
{{m.name}}