深度学习_吴恩达_DeepLearning.ai
P10

上下标的语法:H2O、 CO2、爆米TM、C142
Logistic回归的损失函数
L(y^,y)=-[y logy^ + (1-y) log(1-y ^ )],其中y^为预测标签,y为真实标签。
当y=1时,L(y^,y)=- log y^ ,因为y^在0~1之间, logy^为负,但是- logy^ 为正,此时y ^ 越趋于1,L(y^ ,y)=- logy^越小。
同理,y=0时,L(y^,y)=- log(1-y^ ),此时y^ 越趋于0,L(y^,y)=- log(1-y^)越小。
P18
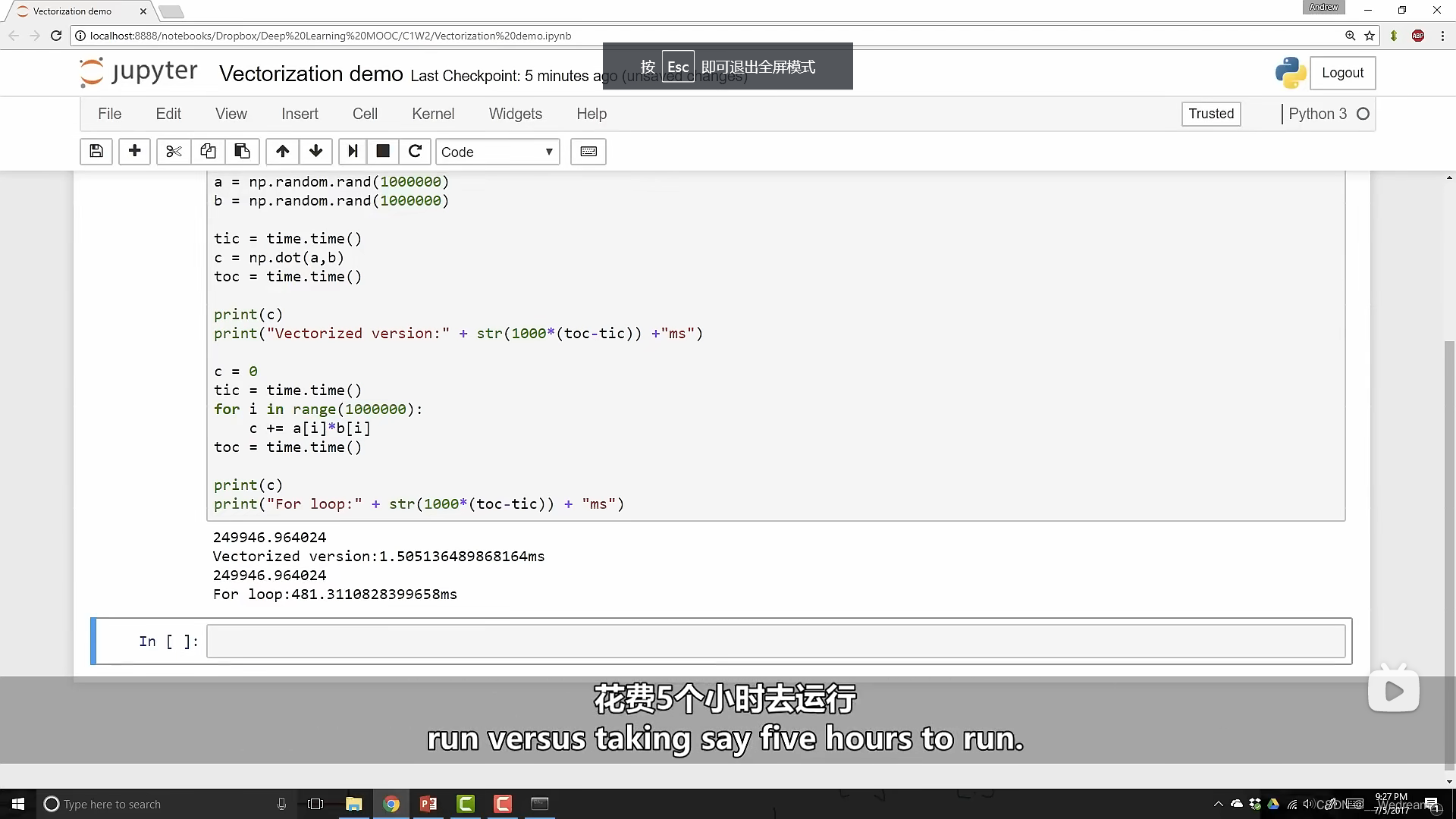
在大数据量计算中,向量化比for循环更快,更节省时间。
import numpy as np
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a,b)
toc = time.time()
print(c)
print("Vectorized version:" + str(1000*(toc-tic)) +"ms")
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print(c)
print("For loop:" + str(1000*(toc-tic)) +"ms")
P23

使用类似于assert(a.shape == (5,1))的断言,能够使你更确定向量的维度,也能及时发现错误。
自由使用断言语句,来复查矩阵和数组的维度。还有,不要怕使用reshape操作来确保矩阵和向量是你所需要的维度。
P29
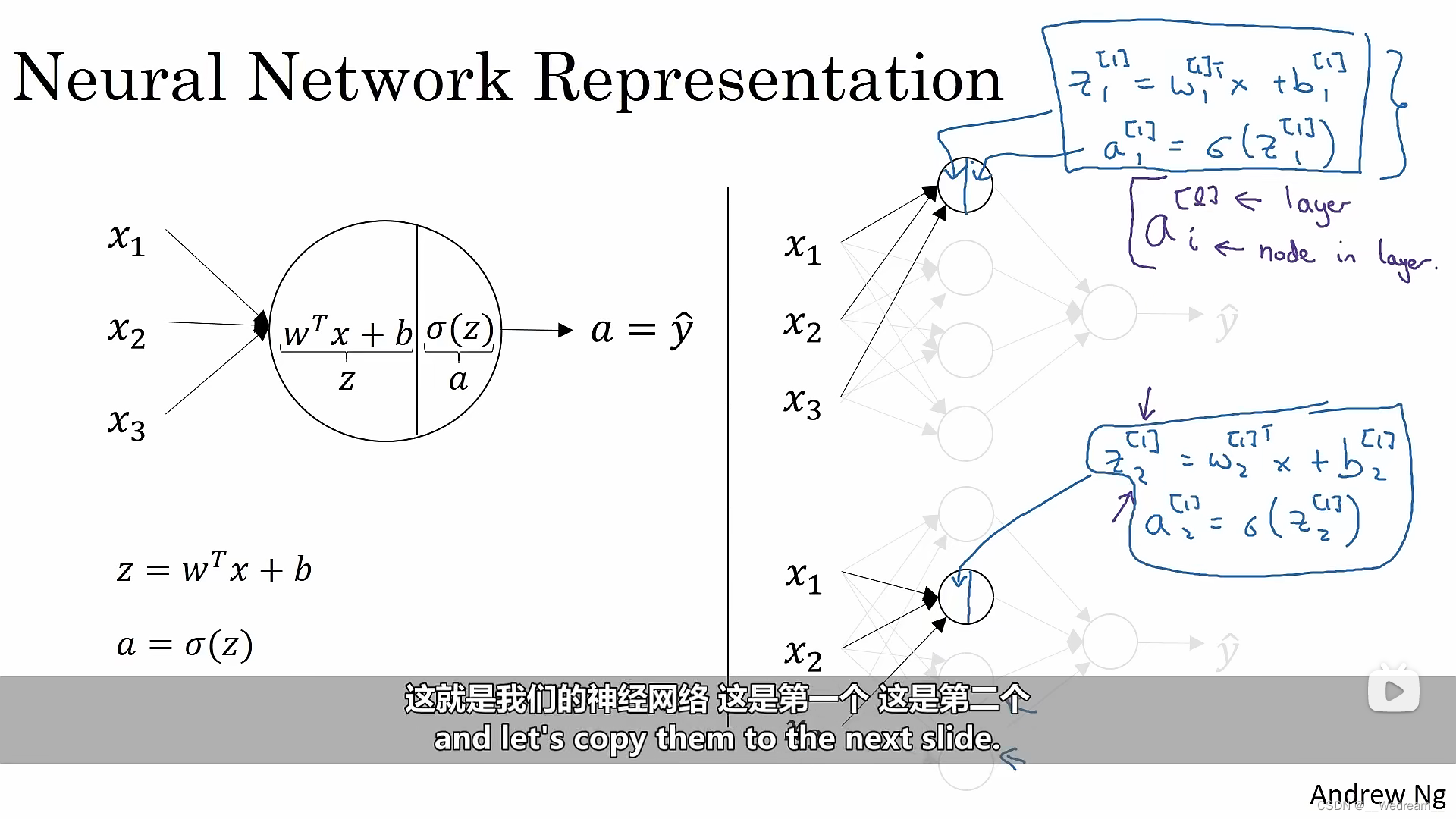
-
在左边的逻辑回归中,一个圆分别代表了两步运算,先按照矩阵乘法计算z,随后使用激活函数得到a。
-
右边的神经网络只是将左边的逻辑回归这个过程做了多次。
-
a[l]i表示第l层的第i个节点。
P33

为什么需要非线性激活函数?
如果你使用线性激活函数(或者叫恒等激活函数),那么神经网络的输出,仅仅是输入函数的线性变化。
在深度网络中,神经网络有许多许多隐藏层,结果发现,如果你使用线性激活函数,无论你的网络有多
少层,它所做的只是计算一个线性激活函数,还不如去除所有隐藏层。
P37

为什么神经网络的权重参数需要随机初始化?
如果神经网络中,将所有权重参数初始化为零,那么所有的神经元将会肩负着相同的计算功能,并且也
将同样的影响作用在输出神经元上。经过一次迭代后,依然会得到相同的结果,这些神经元依然是“对
称”的,因此需要随机初始化成不一样的数值。
P45

参数与超参数的概念
参数:如W、b这些训练时自动更新的参数。
超参数:如学习率、迭代次数、隐藏层数、每层神经元的数目及激活函数的选择,这些都需要人为设定,称为超参数。
参数与超参数的关系:超参数的设定会影响参数的最终值。
P47
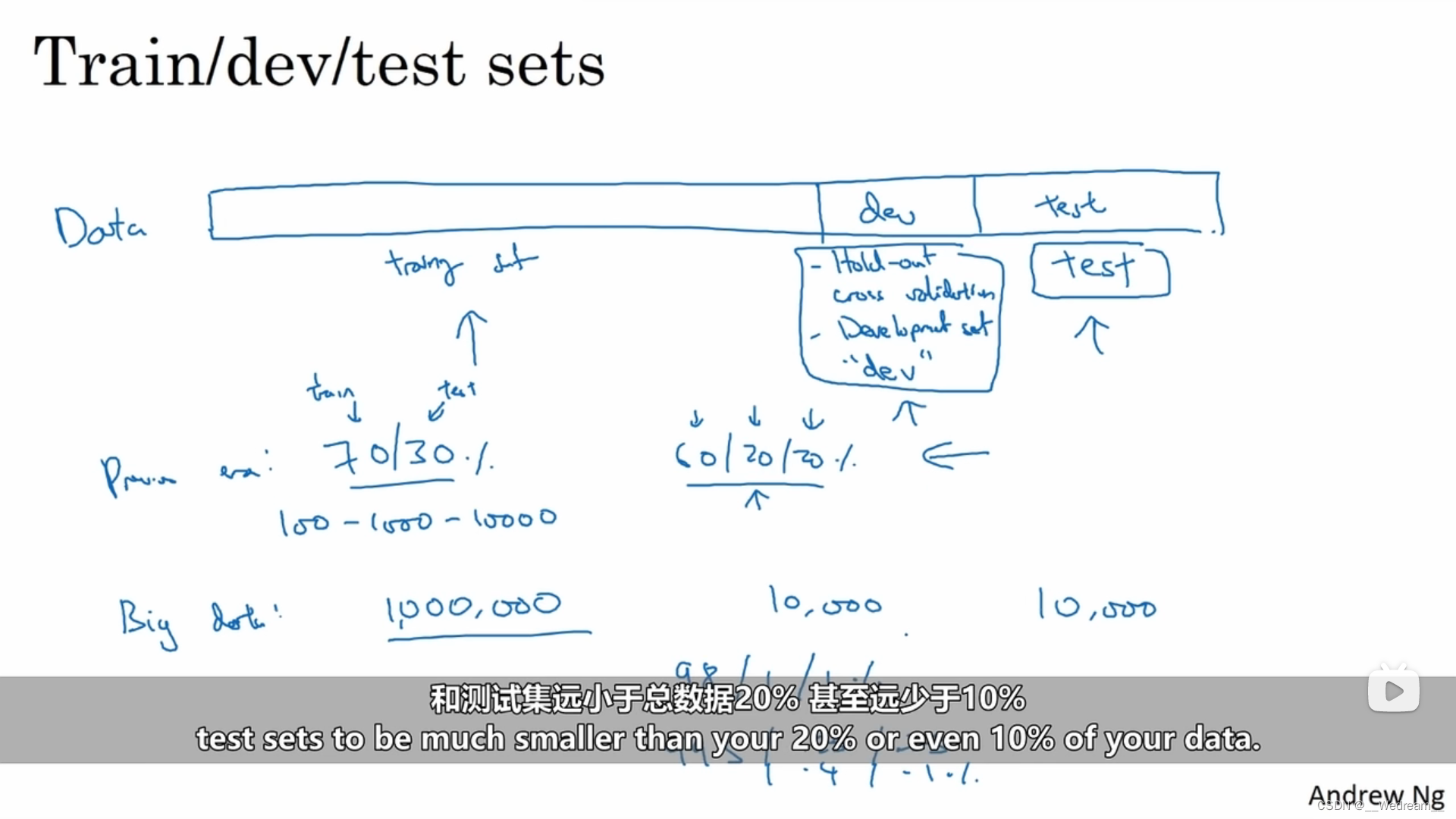
训练集/开发集(验证集)/测试集
传统的做法是在所有数据集中,取出一部分作为训练集,然后再留出一部分作为留出法交叉验证集(有时也称为开发集),再从最后取出一部分作为测试集。
整个工作流程是首先你不停地用训练集来训练你的算法,然后用你的开发集(留出法交叉验证集)来测试,确定许多不同的模型里哪一个在开发集上效果最好。当这个过程进行的时间够长之后,你可能想评估一下你最终的训练结果,你可以用测试集对结果中最好的模型进行评估,这样使得评估算法性能时不引入偏差。
P48

高方差和高偏差
- 当训练集的识别误差为1%,开发集的识别误差为11%时,是高方差的情况。(因为训练集的误差都比较低,但两者误差相差过大)
- 当训练集的识别误差为15%,开发集的识别误差为16%时,是高偏差的情况。(因为训练集和开发集的误差都比较高,且相差不大)
- 当训练集的识别误差为15%,开发集的识别误差为30%时,是高偏差、高方差的情况。(因为训练集和开发集的误差都比较高,且相差过大)
- 当训练集的识别误差为0.5%,开发集的识别误差为1%时,是低偏差、低方差的情况(理想情况)。(因为训练集和开发集的误差都比较低,且相差较小)
注意:以上情况都是基于人工对图像的识别误差为零的情况,如果人眼都识别不好,就不能奢求训练出的模型表现较好,毕竟数据决定了机器学习的上限,好的数据人眼才容易识别,那么机器学习的上限同样也会高。
P49
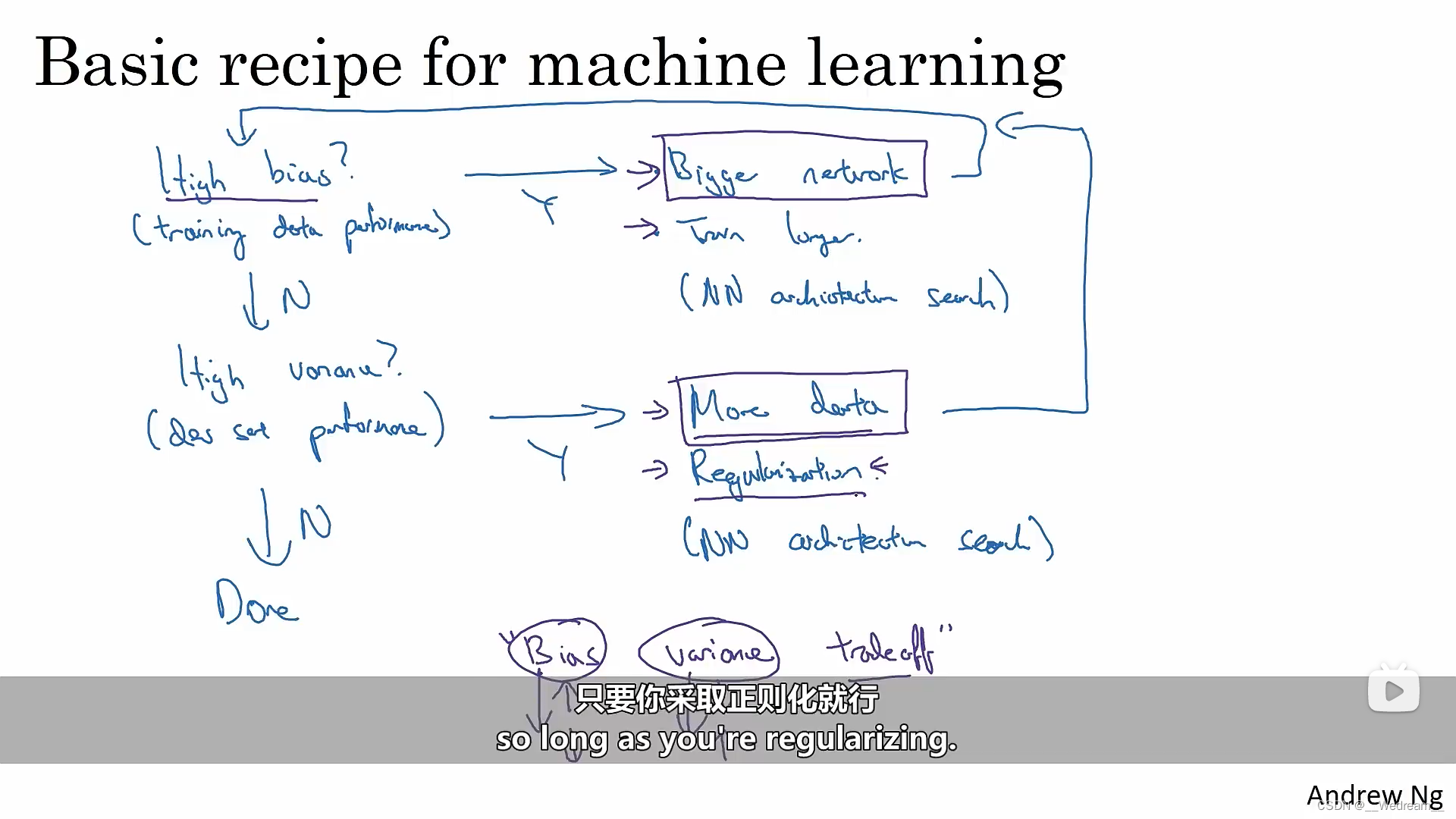
机器学习的基本配方
- 应对模型有高偏差的情况(训练集表现较差),可以采取如下措施:
- 尝试更大的网络(更多的隐藏层,或者更多的隐藏层单元等)
- 延长训练时间
- 选择其他的网络架构
- 应对模型有高方差的情况(训练集、开发集表现差异较大),可以采取如下措施:
- 尝试获取更多的数据
- 正则化
- 选择其他的网络架构
P69

学习率衰减
在学习的初始步骤中,你可以采取大得多的步长,但随着学习开始收敛于一点时,较低的学习率可以允许你采取更小的步长,将围绕着离极小值点更近的区域摆动,即使得代价函数最小化。学习率衰减的公式如下:
α = 1 1 + d e c a y _ r a t e ∗ e p o c h _ n u m × α 0 \alpha=\frac{1}{1+decay\_rate*epoch\_num} \times \alpha_0 α=1+decay_rate∗epoch_num1×α0
其中, α \alpha α为当前学习率, d e c a y _ r a t e decay\_rate decay_rate是设定的超参数衰减率, e p o c h _ n u m epoch\_num epoch_num是当前的训练轮数, α 0 \alpha_0 α0是初始学习率。
P71
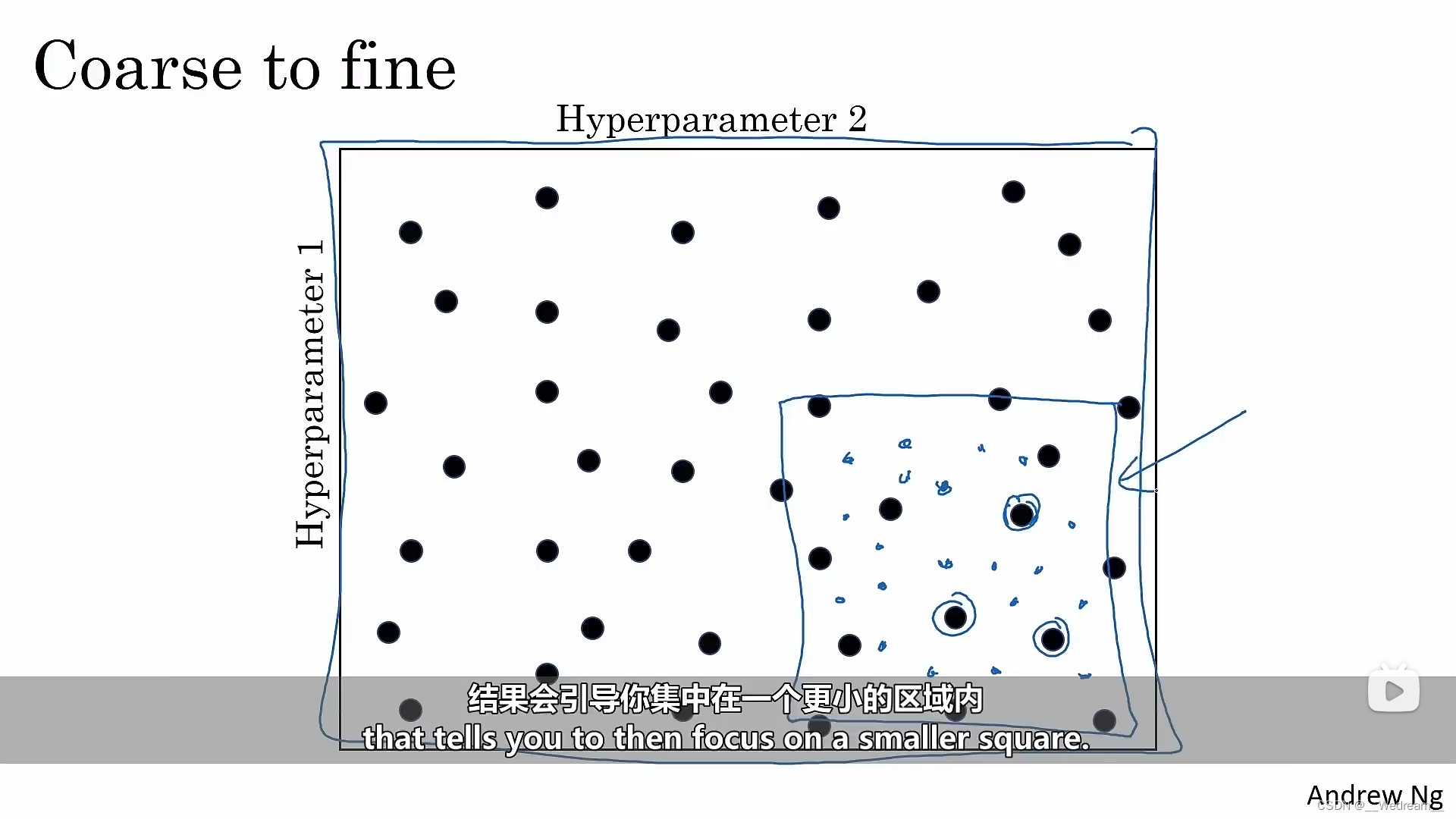
超参数搜索
- 使用随机取样,充分搜索
- 随即实现一个粗到精的搜索过程
P76

为什么选择Batch Norm算法?
- 经过归一化的输入特征(均值为0,方差为1),将大幅加速学习过程。同理,也适用于隐藏层的值。
- Batch Norm算法减少了隐藏单元值的分布不稳定性。
- Batch Norm算法减少输入值变化所产生的问题,使这些值变得稳定,因此神经网络的后层,可以有更加稳固的基础。
- 实际上也是,尽管前几层继续学习,后层适应前层变化的力量被减弱。Batch Norm算法削弱了前层参数和后层参数的耦合,它允许网络的每一层独立学习,有一点独立于其他层的意思,这将有效提升整个网络学习速度。
- Batch Norm算法具有轻微的正则化效果。
P80

好的深度学习框架的标准
- 编程的难易程度(开发过程及部署过程中)
- 运行速度
- 是否真正开源(并且有良好的管理)
P82

机器学习策略
假设系统的准确率达到90%,但并没有达到你的预期,可能会有以下提升准确率的思路:
- 收集更多的训练数据
- 收集更多样的数据,或者更多样化的反例
- 使用梯度下降法训练更长的时间
- 使用Adam优化器代替其他优化器
- 尝试更大的网络
- 尝试更小的网络
- 尝试dropout
- 增加 L 2 L_2 L2正则化
- 新的网络架构
- 激活函数
- 隐藏层神经元数目
P87
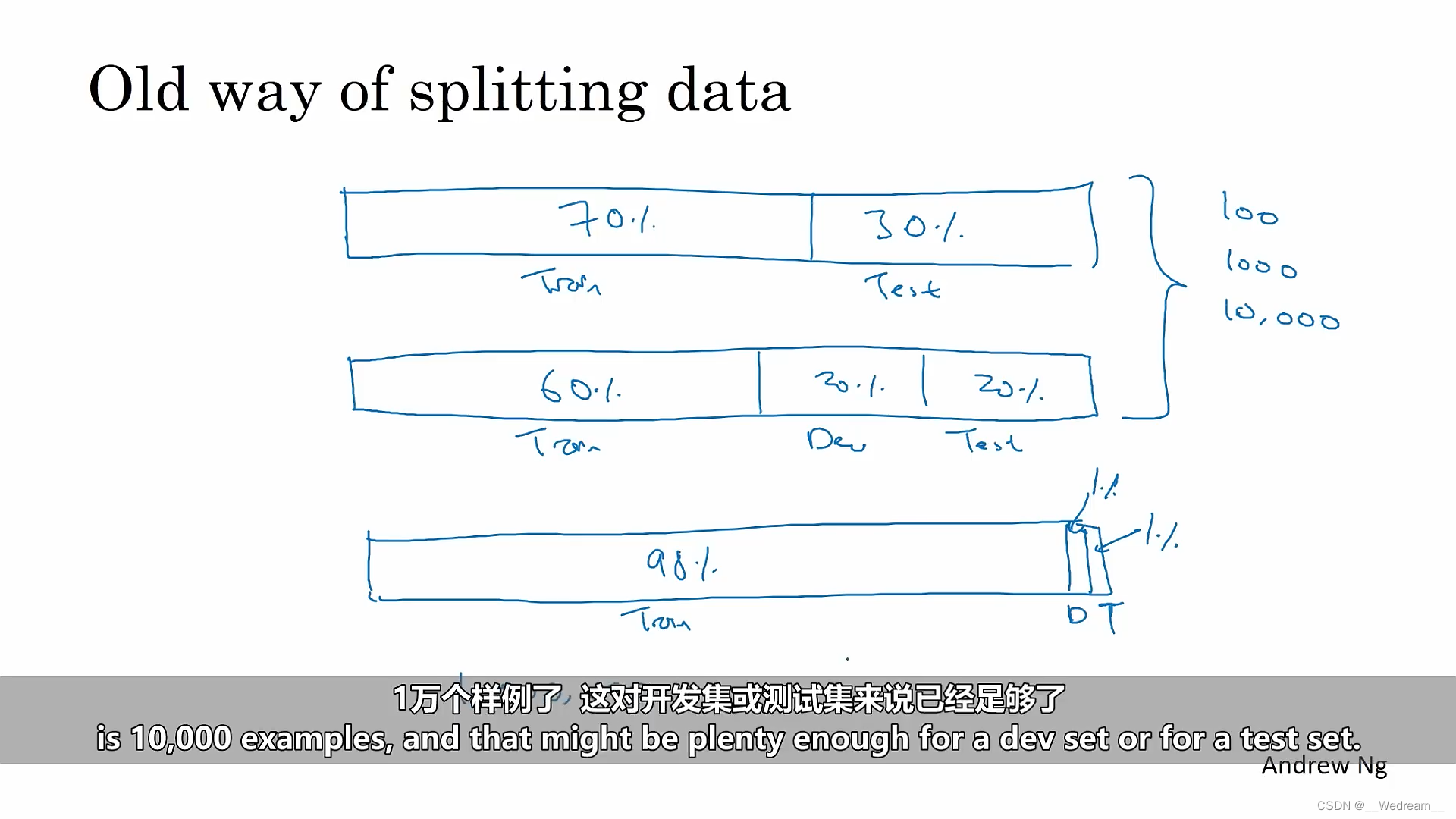
训练集、开发集(验证集)和测试集的大小
- 如果数据量较小(比如100张、1000张、10000张图片),可按以下比例划分:
- 训练集:测试集=70%:30%;
- 训练集:开发集:测试集=60%:20%:20%;
- 如果拥有大量数据集(比如1000000张图片)
- 10000个样例,对于开发集或测试集已经足够了,因此训练集:开发集:测试集=98%:1%:1%;
P93

提高模型性能
如果一个有监督学习能够发挥作用,基本上意味着你可以做到两件事:
- 可以很好地拟合训练集(即较低的可避免偏差);
- 训练集的结果能够很好地推广到开发集或者测试集(即较低的可避免方差)。
如果想要改善你的机器学习系统,建议看看训练误差和贝叶斯误差估计值的差距,这能让你估计可避免偏差;然后再看看开发集误差和训练误差间的差距,来估计你的方差多大。
降低可避免偏差的策略
- 训练一个更大的模型
- 训练更长的时间
- 用更好的优化算法
- 更好的神经网络架构
- 更精准的超参数值(超参数搜索)
降低方差的策略
- 用更多的数据来训练
- 正则化(L2正则化或随机失活法等)
- 更好的神经网络架构
- 更精准的超参数值(超参数搜索)
P99

从训练集误差转移到开发集误差时,有两件事变了:
- 算法看到的数据只有训练集没有开发集。
- 开发集和训练集数据分布不同。
训练集和开发集数据分布不同时的处理
假设开发集和测试集属于同分布,训练集属于不同分布,我们要做的是将训练集随机混淆,取出一小块数据作为训练-开发集,如同开发集与测试集分布相同,训练集与训练-开发集也遵循相同分布。区别在于,现在你只需要用着一部分训练集训练你的网络,不用让神经网络对训练-开发集负责。
误差分析
做误差分析时,你需要对比分类器的误差,即训练集误差、训练-开发集误差和开发集误差。
-
情况一
假设训练集误差为1%,训练-开发集的误差为9%,开发集的误差为10%。我们可以从中看出,此时存在方差问题,因为训练集和训练-开发集是来自同一分布,但是训练-开发集的误差远大于训练集误差。
-
情况二
假设训练集误差为1%,训练-开发集的误差为1.5%,开发集的误差为10%。由于从训练-开发集的误差和训练集误差相近,而开发集的误差远大于训练-开发集的误差,因此出现了数据不匹配问题,即训练集和开发集不同分布。
-
情况三
假设人类水平的贝叶斯误差为0%,训练集误差为10%,训练-开发集的误差为11%,开发集的误差为12%。此时出现了可避免偏差问题(高偏差),因为性能比人类水平差远了。
-
情况四
假设人类水平的贝叶斯误差为0%,训练集误差为10%,训练-开发集的误差为11%,开发集的误差为20%。那么它存在两个问题,第一,可避免偏差相当高,因为训练集误差远大于类水平的贝叶斯误差;第二,数据失配程度相当大,因为开发集的误差远大于训练-开发集的误差,即训练集和开发集不同分布。
P101

何时可以使用迁移学习(以从A任务迁移到B任务为例)
- 任务A与任务B必须有相同的输入(比如输入都为图片或者音频)
- 任务A的数据量应该远远大于任务B
- 从任务A中学习到的低层次特征(如边界检测、曲线检测或明暗对象检测等)会帮助任务B达成目标
P116
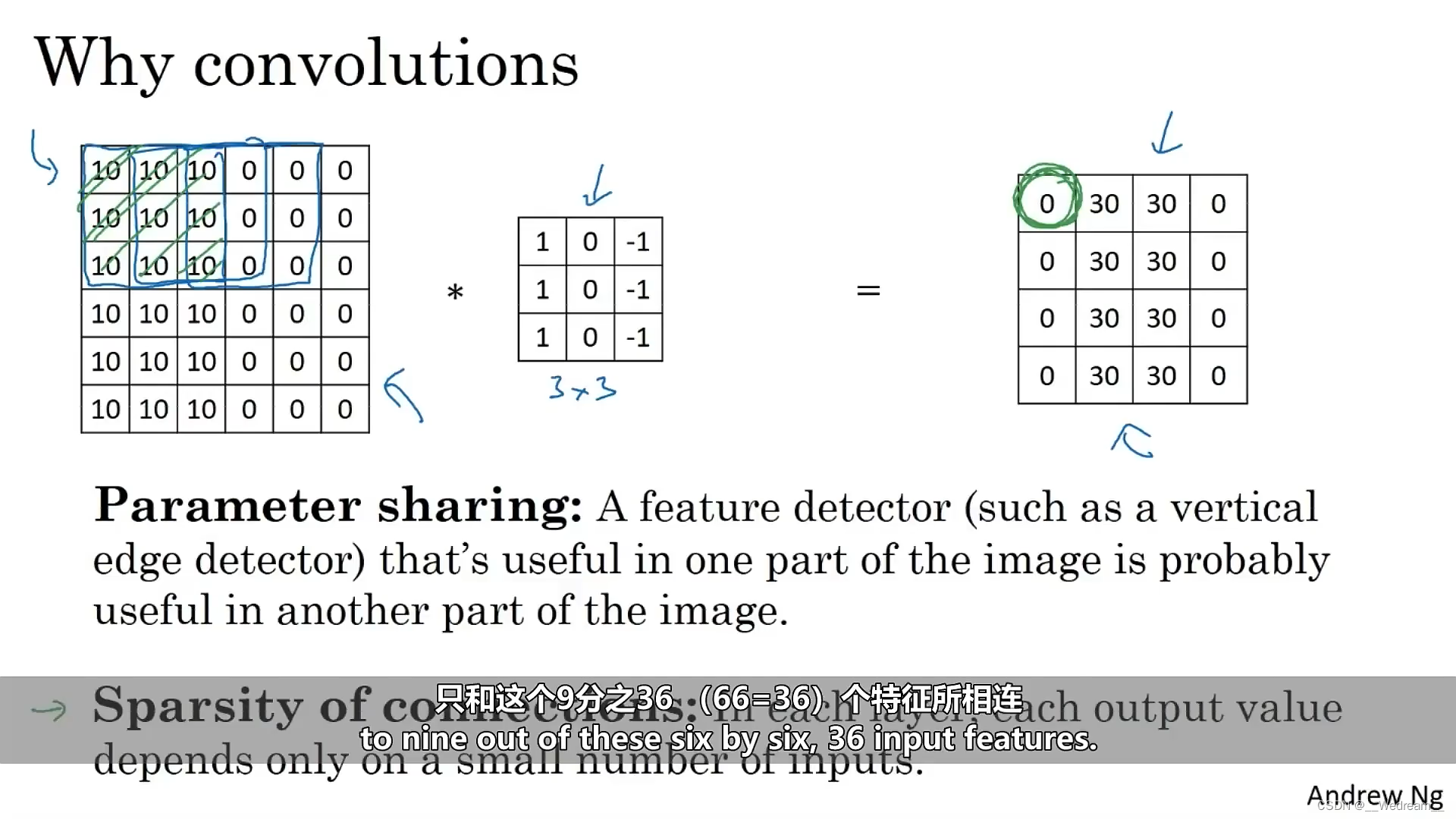
为什么要使用卷积
- 可以实现参数共享,减少参数量。全连接层的参数量一般巨大,而卷积层的参数量相对较小。一个特征检测器(比如垂直边缘检测器)在图像的一个部份有用,一般也在图像的另一个部份有用。
- 可以建立稀疏的连接。每一层的输出的值,只依赖于少部分的输入的值。
P121

1 × \times × 1卷积的作用
假如我们有一个28 × \times × 28 × \times × 192的特征图,如何将它缩小到28 × \times × 28 × \times × 32呢? 答案是使用32个1 × \times × 1 × \times × 192的过滤器进行卷积,这样通道数就能从192降到32了,并且宽高不变。
那么如何缩小特征图的宽和高呢?假如我们有一个28 × \times × 28 × \times × 192的特征图,如何将它缩小到14 × \times × 14 × \times × 192呢?答案是使用大小为2,步长为2的池化进行操作,此时宽和高会减半,通道数不变。
P124
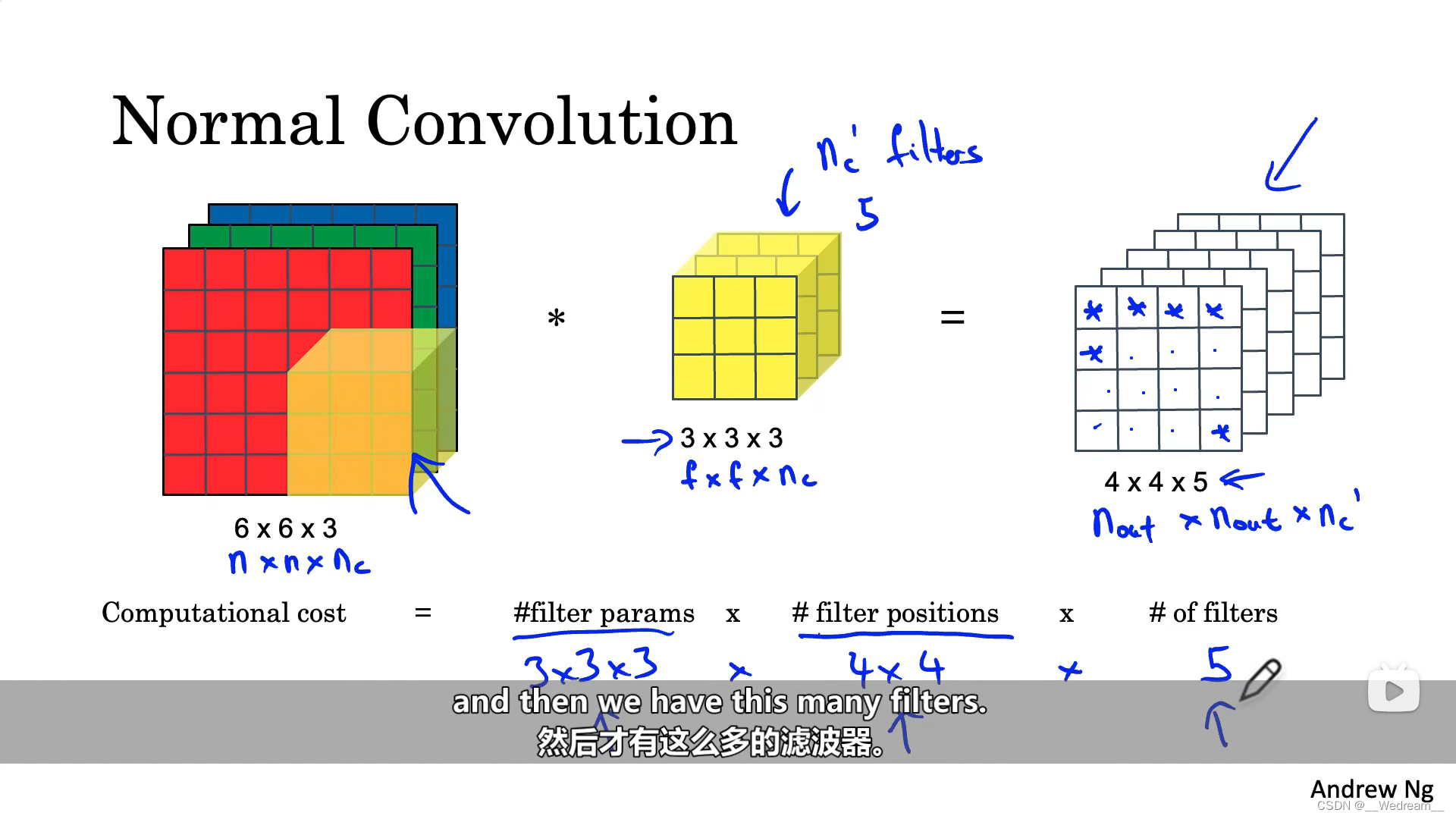
普通卷积的计算成本
C o m p u t a t i o n l c o s t = # f i l t e r p a r a m s × # f i l t e r p o s i t i o n s × # o f f i l t e r s Computationl \ cost = \#filter \ params \times \#filter \ positions \times \#of \ filters Computationl cost=#filter params×#filter positions×#of filters
其中, C o m p u t a t i o n l c o s t Computationl \ cost Computationl cost表示的是计算成本; # f i l t e r p a r a m s \#filter \ params #filter params表示的是滤波器的大小,即 3 × 3 × 3 3 \times 3 \times 3 3×3×3; # f i l t e r p o s i t i o n s \#filter \ positions #filter positions可以认为是滤波器在特征图中移动的次数,即 4 × 4 4 \times 4 4×4 ; # o f f i l t e r s \#of \ filters #of filters表示的是滤波器的数量,由图右的 4 × 4 × 5 4 \times 4 \times 5 4×4×5可知,滤波器的数量为5。
P130
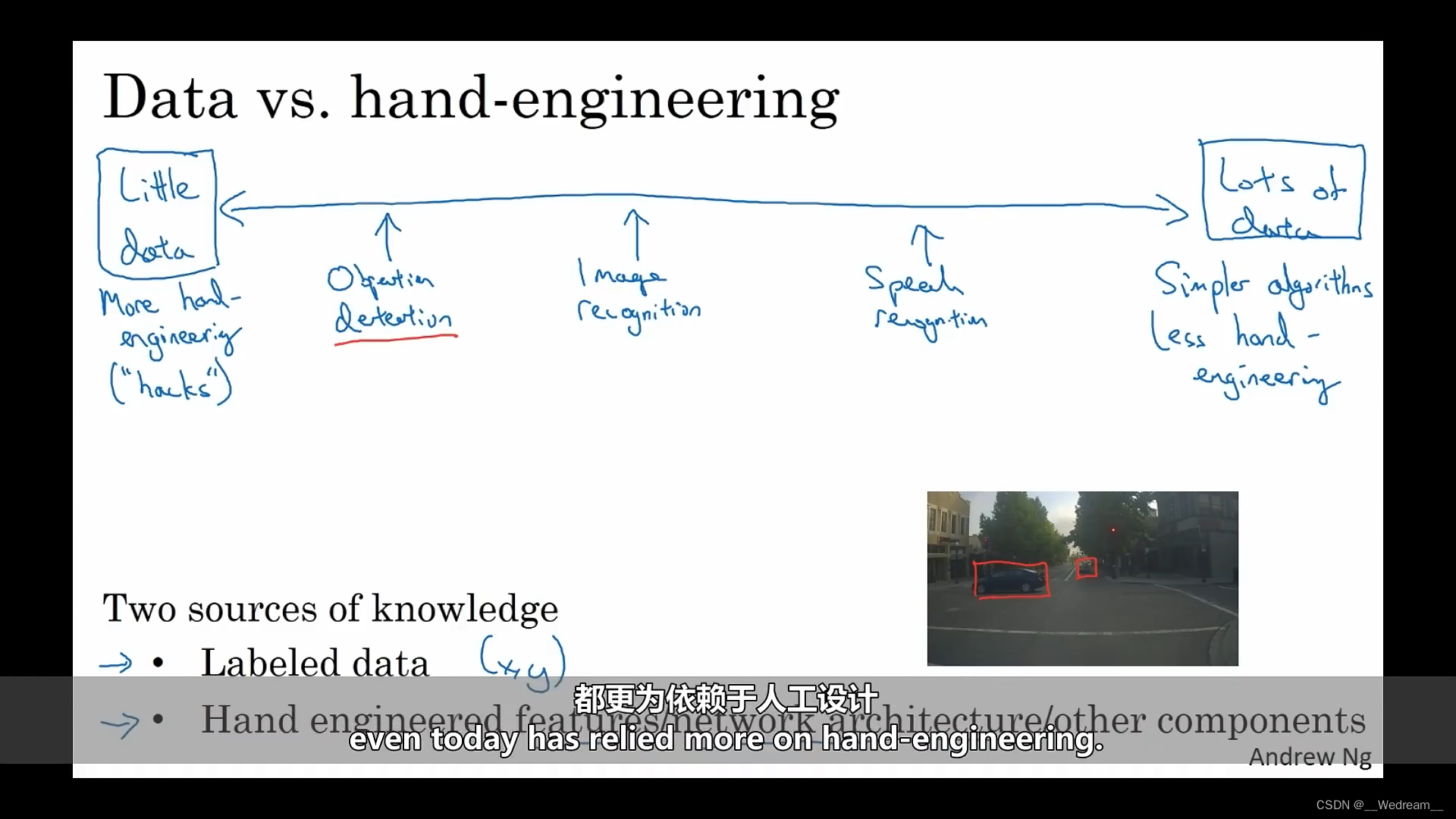
数据 vs. 人工设计
纵观机器学习的历史,若拥有很多数据时,人们往往使用比较简单的算法,以及更少的人工设计就可以实现目标,所以不太需要针对问题来仔细地设计特征。当你有大量的数据时,你可以用一个巨大的神经网络,甚至更为简单的结构,就能让神经网络学习我们想要学习的。
相比之下,若没有足够的数据,通常会看到人们做更多的人工设计,即做更多的手工处理。我认为,数据量少时,人工设计实际上是获得良好效果的最好方法。
因此,通常学习算法有两个知识来源:一是标注的数据,二是人工设计。有很多方法可以用来手工设计一个系统,可以是精心设计特征,也可以是精心设计网络结构,或者系统的其他组件。所以当没有太多标注好的数据时,就需要在人工设计上多下功夫。
P142
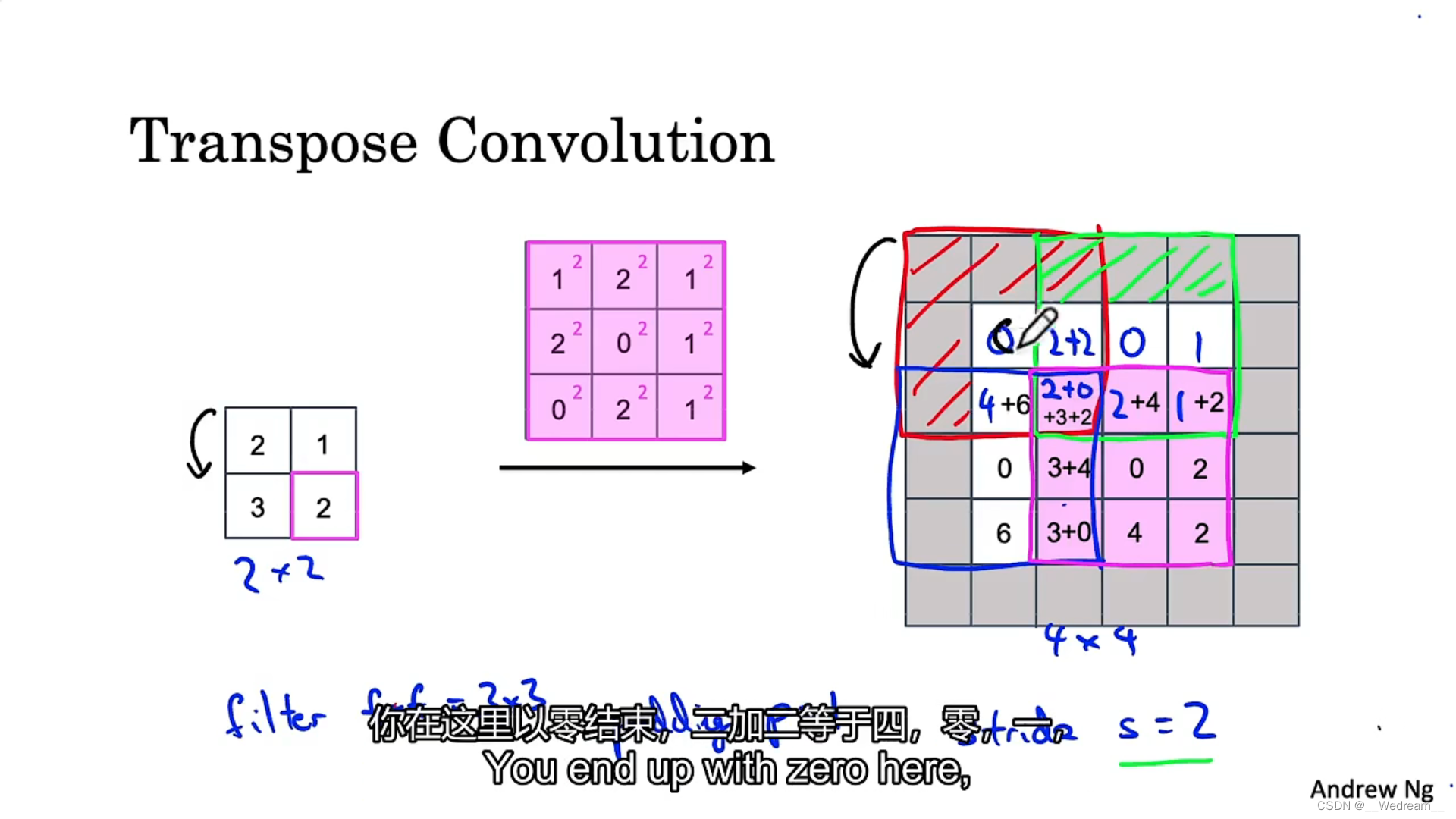
转置卷积
如上图,以 2 × 2 2 \times 2 2×2为输入,我们希望得到 4 × 4 4 \times 4 4×4的输出,因此我们选择 3 × 3 3 \times 3 3×3的滤波器来操作,还将使用 p = 1 p=1 p=1的填充在输出中,最后,在本例中使用 s = 2 s=2 s=2的步幅。
-
首先, 2 × 2 2 \times 2 2×2输入的左上角为 2 2 2,我们使得 3 × 3 3 \times 3 3×3滤波器的每个元素乘以 2 2 2,并写到 p = 1 p=1 p=1填充的输出中,即从左到右,从上到下分别为 2 、 4 、 2 、 4 、 0 、 2 、 0 、 4 、 2 2、4、2、4、0、2、0、4、2 2、4、2、4、0、2、0、4、2。
-
将输出向右边移动 2 2 2格,因为步幅 s = 2 s=2 s=2。 2 × 2 2 \times 2 2×2输入的右上角为 1 1 1,我们使得 3 × 3 3 \times 3 3×3滤波器的每个元素乘以 1 1 1,并写到 p = 1 p=1 p=1填充的输出中,即从左到右,从上到下分别为 1 、 2 、 1 、 2 、 0 、 1 、 0 、 2 、 1 1、2、1、2、0、1、0、2、1 1、2、1、2、0、1、0、2、1。其中重叠的部分相加,有两个格子重叠,即为 2 + 2 、 2 + 0 2+2、2+0 2+2、2+0。
-
重复以上步骤。
P158
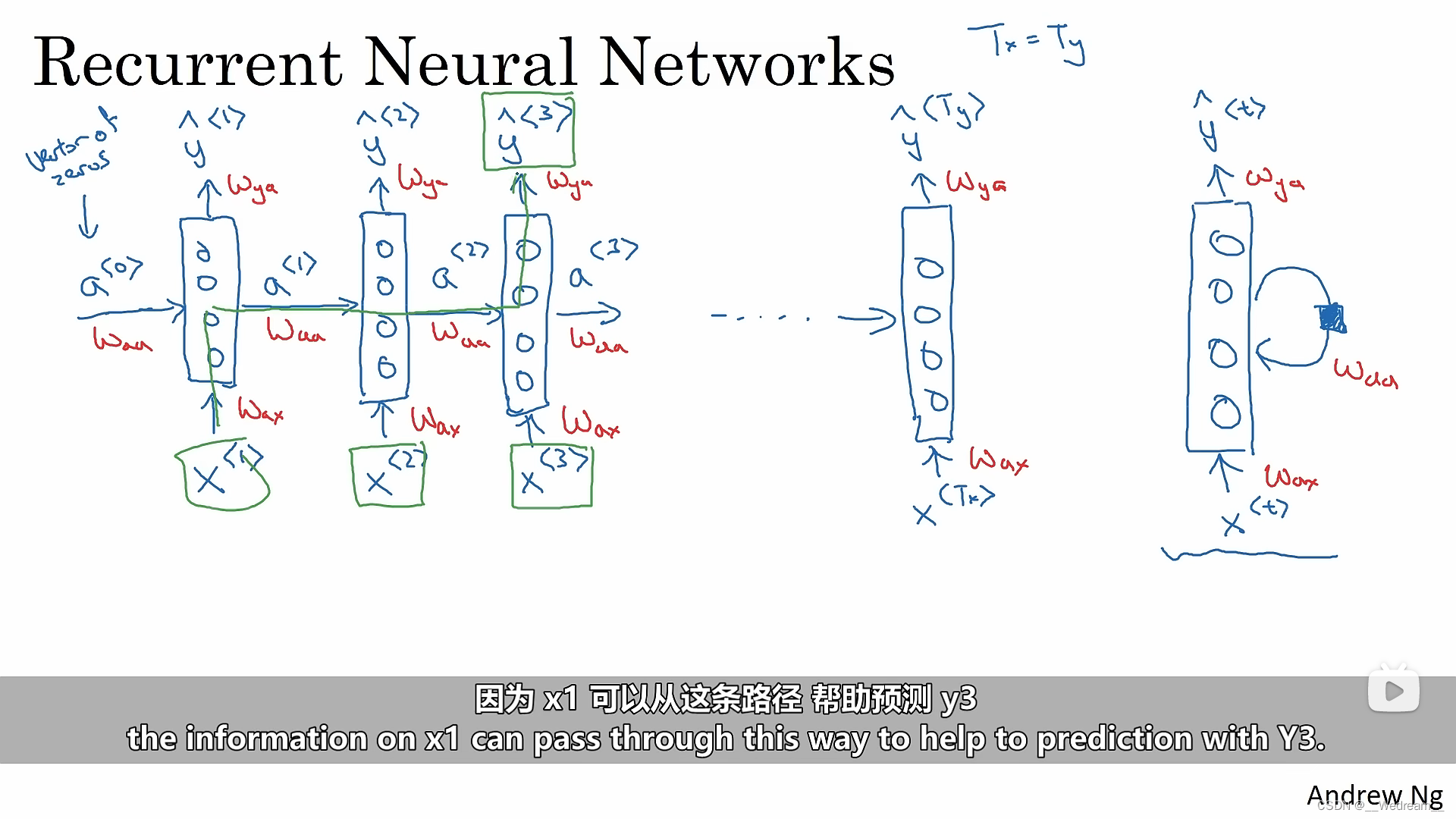
循环神经网络
循环神经网络所做的是,当其继续读取句子中的第二个词语的时候,比如 x 2 x_2 x2,神经网络不仅仅通过 x 2 x_2 x2去预测 y 2 y_2 y2,它还会把上一步的计算结果作为其输入信息的一部分。在每一次的步骤中,循环神经网络会传递激活值,传递到下一步,供其使用。
P160
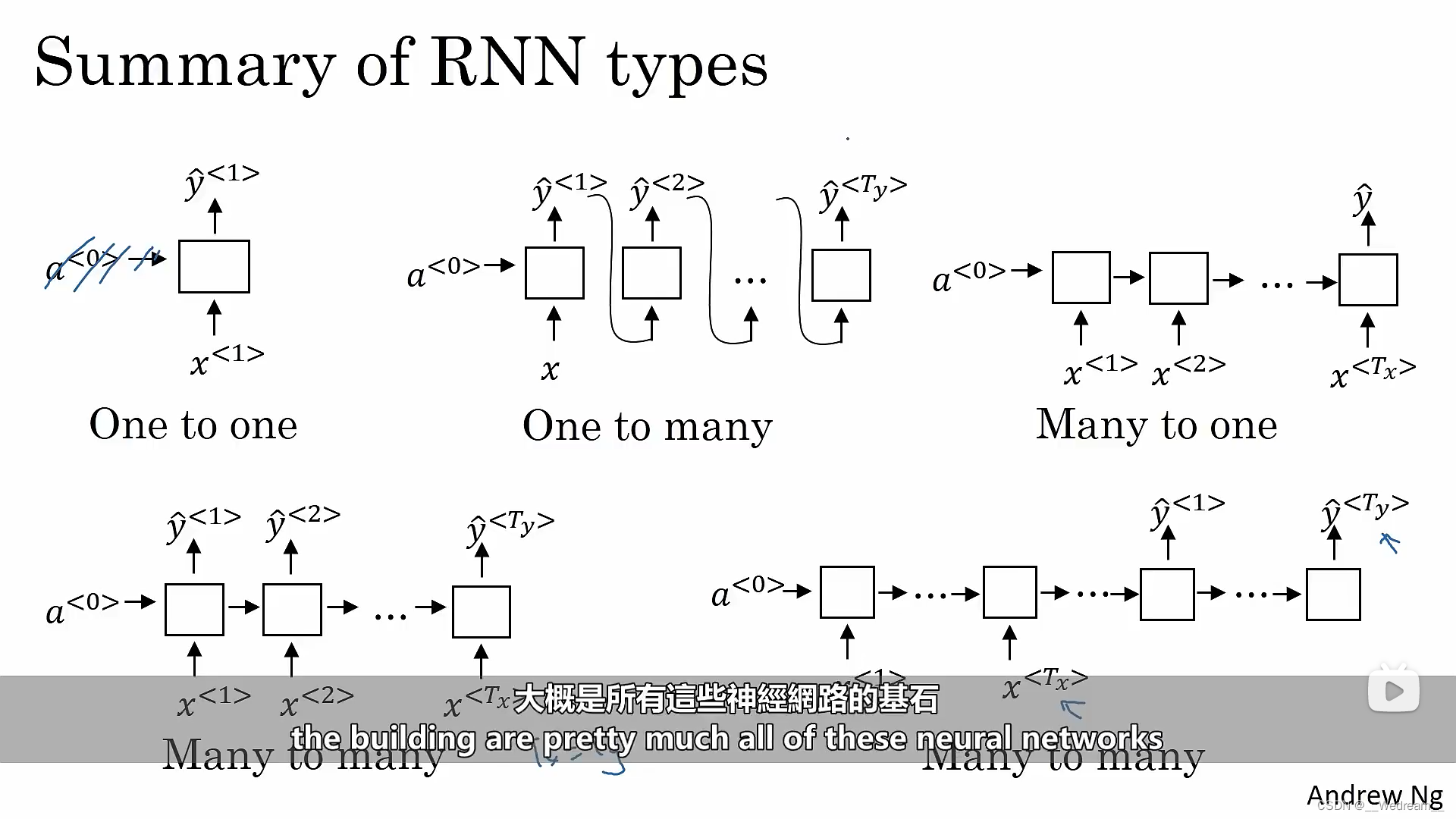
循环神经网络的类型
- 一对一(标准原始的神经网络,循环神经网络比较少用)
- 一对多 (比如音乐生成)
- 多对一 (比如句子情绪分类)
- 多对多1 (Tx=Ty,比如识别人名)
- 多对多2 (Tx!=Ty,比如机器翻译)
P177

去除Word Embedding的偏差
- 识别需要消除或减少的特定偏差的方向。
- 中间化,对于每个没有定义的词,通过投影来去除偏差。
- 均匀化。比如使得词girl和boy与词doctor的距离相等。
P185
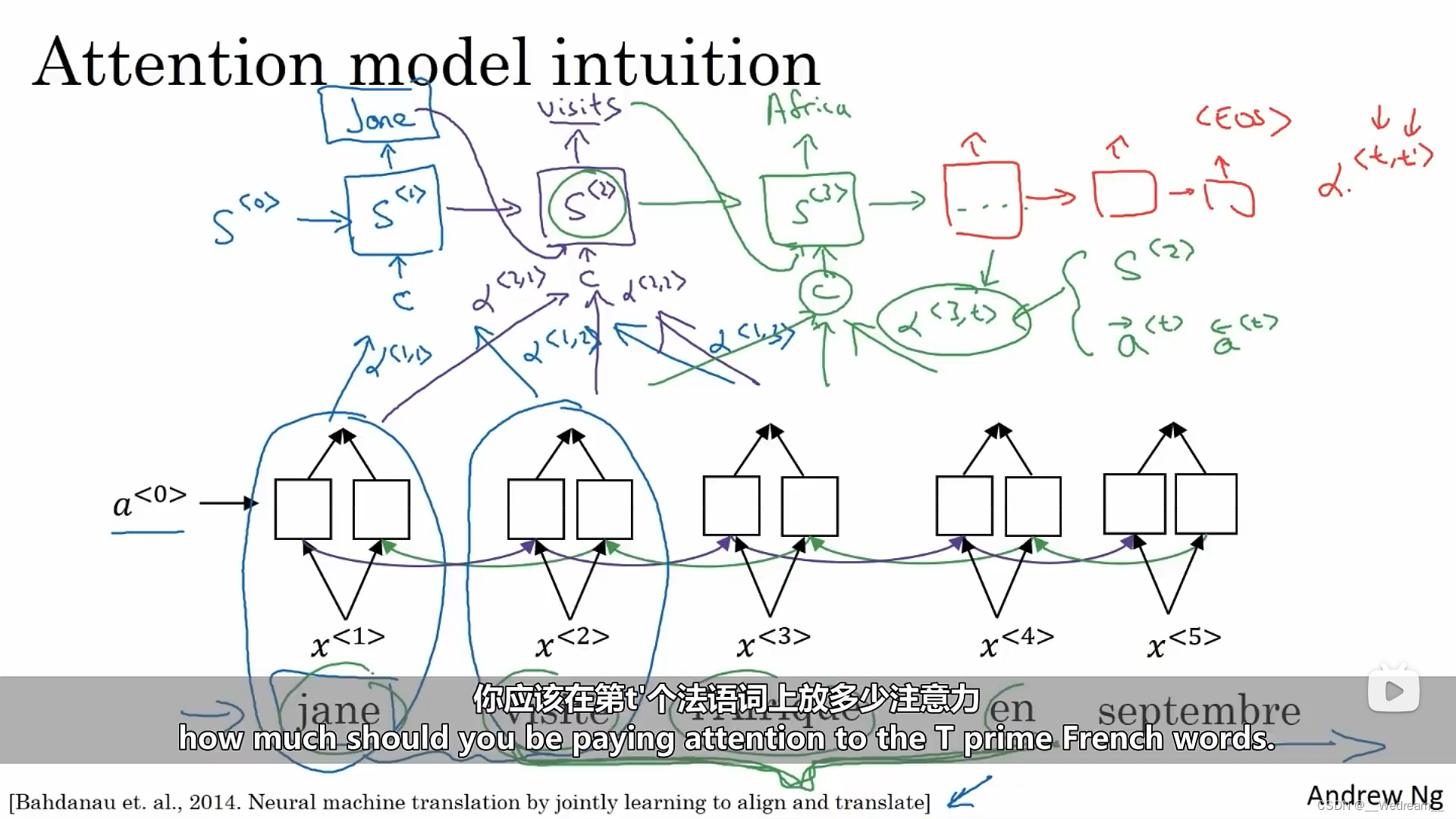
注意力模型
注意力机制实际上是一个求权重的过程。 假设有5个法语词的句子需要我们翻译,我们并不需要逐字翻译。我们针对句子中5个不同的位置,计算出一组丰富的,关于句子中每个词以及它们周围词的特征。那么问题来了,当你想要去生成第一个词时,你应该去看下面这个法语句子中的哪一个部分呢?我们的直觉告诉我们,应该看第一个法语词汇以及它周围的几个词,实际上我们也可能不用去关注句子末尾的那些词(毕竟才开始翻译第一个词)。
注意力模型会计算的是一系列注意力权重(参数),假设我们用 a ( 1 , 1 ) a(1,1) a(1,1)去标记,当你生成第 1 1 1个词时,你需要多少注意力在法语的第 1 1 1个词汇。同理,我们用 a ( 1 , 2 ) a(1,2) a(1,2)去标记,当你生成第 1 1 1个词时,你需要多少注意力在法语的第 2 2 2个词汇。以此类推到第三个词,等等。然后这些一起会准确告诉我们,我们应该放多少注意力在这个位置所对应的句子上下文语境中。
P189
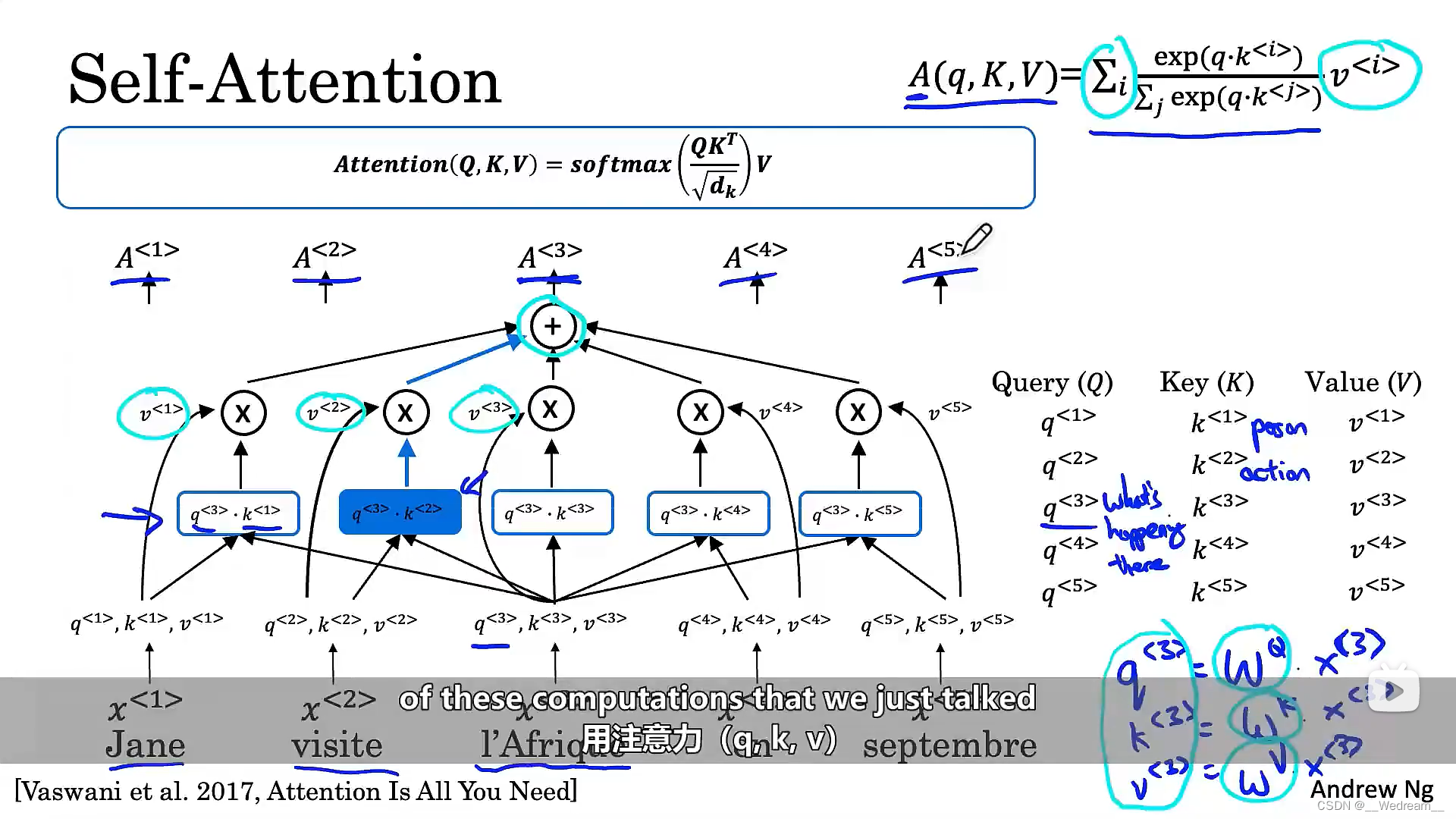
自注意力机制
我的总结:总的来说,注意力机制就是一个求权重的过程。将源域看成是由一系列的 <Key,Value>数据对 组成,给定目标域中的一个元素(Query),计算它与Key之间的相似度和关联度,对应的值就是Value,也就是权重系数。最后对所有求得的Value权重求和,得到注意力的值。所以本质上注意力机制就是一个加权求和的过程。

在机器翻译中,首先需要将每一个词,与Query、Key和Value三个值关联起来。如下图,我们假设 x < 3 > x^{<3>} x<3>是I’Afrique的词嵌入(word embedding),那么 q < 3 > q^{<3>} q<3>、 k < 3 > k^{<3>} k<3>、 v < 3 > v^{<3>} v<3>分别由权重矩阵 w Q w^Q wQ、 w K w^K wK、 w V w^V wV乘以 x < 3 > x^{<3>} x<3>得到,其中矩阵 w w w是可学习的参数。通过这些参数,可以得到每一个单词的Query、Key和Value。那么Query、Key和Value这些向量的作用是什么呢? q < 3 > q^{<3>} q<3>是一个关于I’Afrique的问题, q < 3 > q^{<3>} q<3>表示一个疑问:在I’Afrique发生了什么?我们知道I’Afrique(翻译成英文为Africa)是一个目的地,那么当我们计算 A < 3 > A^{<3>} A<3>时,发生了什么?首先我们计算 q < 3 > q^{<3>} q<3>和 k < 1 > k^{<1>} k<1>的内积(算出来的值与相似度有关),它将告诉我们答案是Jane(一个人),即在Africa发生了什么。然后,计算 q < 3 > q^{<3>} q<3>和 k < 2 > k^{<2>} k<2>的内积,它将告诉我们答案是visite,即在Africa发生了什么。以此类推,可以算出这句话中其他词的答案。此操作的目的,在于获得所需要的最多信息,以帮助我们算出这里有关 A < 3 > A^{<3>} A<3>的最有用的表达。
同样,为了建立直观感觉,倘若 k < 1 > k^{<1>} k<1>代表一个人(Jane),而 k < 2 > k^{<2>} k<2>代表第二个词,即visite,是一个动作,那你会发现 q < 3 > q^{<3>} q<3>和 k < 2 > k^{<2>} k<2>相乘的值最大,这意味着,visite提供了与Africa发生的事,是最有关联的背景。换言之,就是visite的目的地。
P192
完结撒花
最后感谢小伙伴们的学习噢~