周末出去耍了一下,回来又玩了两天游戏,耽误了好多时间啊,关键是连输20多局。哎,以后还是少玩游戏,多去做些有趣的事情吧,免得费时费力还不开心。
1、 循环神经网络(RNN:Recurrent Neural Network)
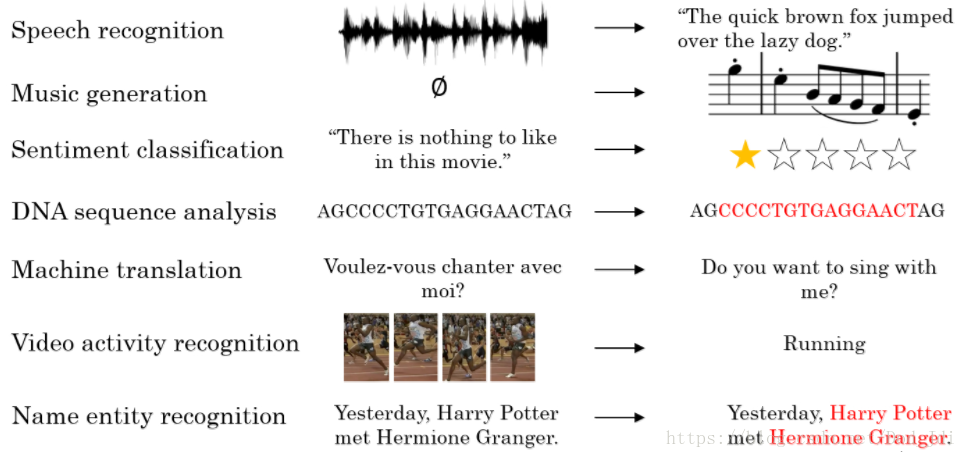
序列模型(sequence model):处理语言和音视频等前后相互关联的数据。和CNN卷积模型处理相对独立的输入和输出不同,序列模型处理的是具有较强相关性的连续序列。序列模型的常用场景如下:
数学符号:
一个序列的第 t 个元素和标签分别用
表示,长度用
表示。
第 i 个序列的第 t 个元素用
表示,对应有
要表示序列中的一个词语,需要根据一个词汇表(Vocabulary)或字典(Dictionary)获取对应的索引,从而得到词语的 ont-hot 向量。
循环神经网络结构:
RNN相比CNN的不同点:1、输入输出可能有不同的长度,因此输入输出层神经元数量无法固定。2、从输入不同位置的同一特征无法共享,不能利用序列的相关性。2、参数量多,计算量太大,时效要求不同。
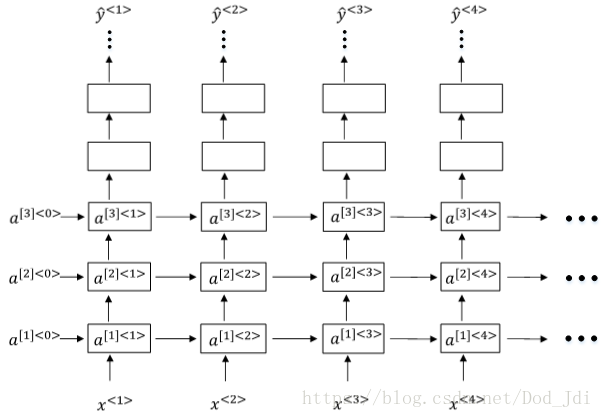
将循环神经网络模型简图(右图)展开如左图:
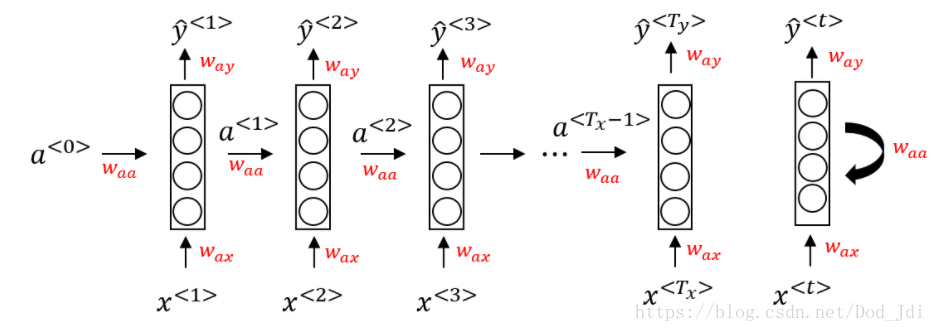
和CNN不同,RNN在根据时间片输入 计算输出的同时,加入上一层的激活之 , 得到预测值 的同时向下一层传播激活值。即前一层的输出作为关联因子参与下一层的运算。
隐藏层内部结构为;
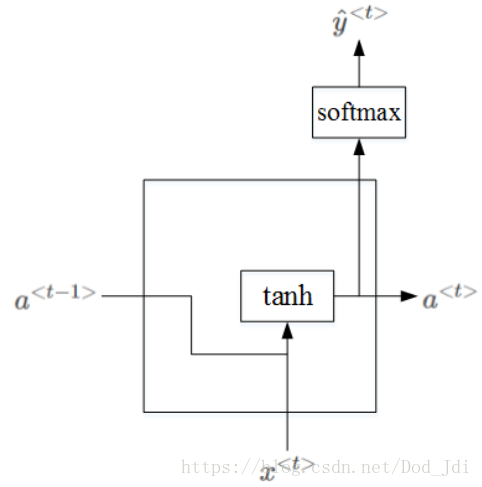
前向传播:
根据上图,可以得到前向传播过程公式如下:
其中,激活函数 一般使用 tanh, 有时也使用 relu, 激活函数 根据输出类型选择 sigmoid 或者 softmax。 对应激活值 a、输入 x、输出 y 的参数。
为方便表示和计算,使用增广矩阵的概念将
合并为
, 简化为:
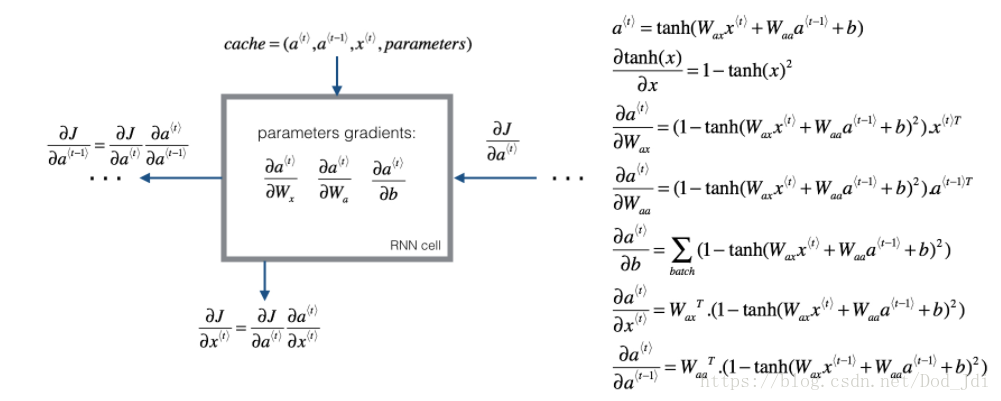
反向传播:
反向传播的基础是确定代价函数。在输出层我们使用sigmoid或者softmax作为激活函数,因此可以某个位置或者时间片上使用交叉熵损失函数:
将所有位置上的损失函数相加,得到整个序列的代价函数为:
反向传播的过程也叫 时间反向传播(Backpropagation through time) :
为了便于理解,上述过程的输入和输出长度是一致的,但实际更多是不一致的,如机器翻译等。因此有许多“多对多”,“一对多”和“一对一” 等结构:
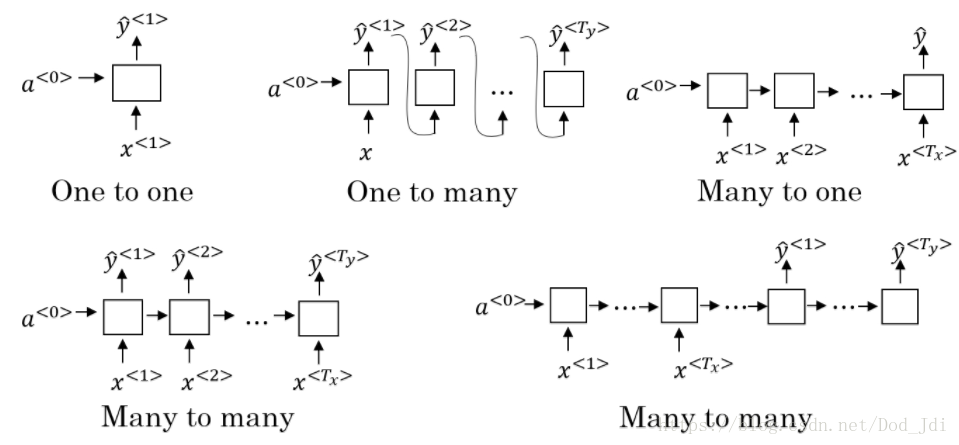
语言模型:
语言模型(Language model)是对实际语言应用建立的抽象数学模型,可以估计一个序列中某个元素出现的概率,是自然语言处理(NLP:Nature Language processing)的重要部分。例如在语音识别中出现:“pair salad” 和 “pear salad” 等相似的词语,就需要根据语言模型来估计其出现的概率。
建立语言模型的训练集需要一个大型的语料库(Corpus), 由数量众多的语句组成。建立的过程需要进行标记化(Tokenize),然后将单词转为 ont-hot 向量。两个重要的标记:EOS(结束标记)和 UNK(未知标记,Unknown)。
训练之后可以根据输入一个单词得到其后每个词的概率,直至EOS。
循环门控单元GRU(Gated Recurrent Unit):
一个语句序列中可能存在跨度较大的依赖关系,如: The cats, which already ate fish, were full. 中的 cats 对 be 动词(were)的影响。然而由于深度神经网络容易存在梯度消失和梯度爆炸的情况,神经网络往往难以将这种依赖关系传递下去。
常用的解决方式是设定一个阀值,通过阀值函数,在将依赖关系传递下去的同时减小梯度值,避免梯度消失(或爆炸),这个方法叫 gradient clipping 。GRU即是将阀值引入隐藏层的计算中:
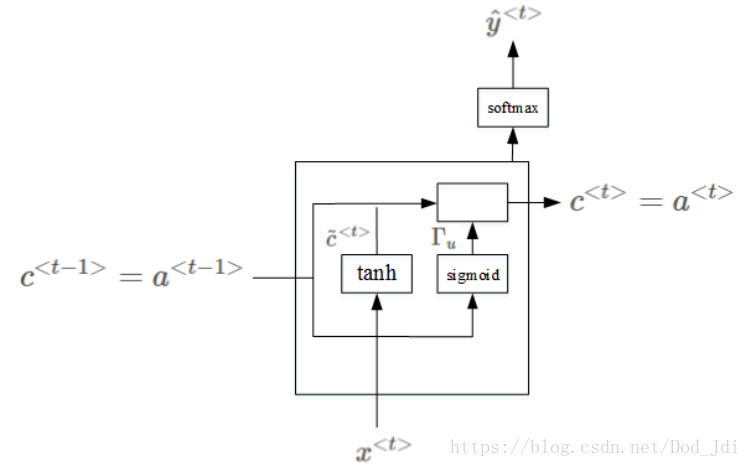
GRU中新增了变量 c (Memory cell,记忆细胞,用于“记忆”单复数等信息)个更新门
(Update Gate, 用于决定是否用
)。在 t 时刻,记忆细胞的值
,
其完整表达式为(门计算出概率,
为值,相乘类似交叉熵 ylogy ):
的下标u、r可理解为 更新(update) 和 保留(reservat)。
LSTM(长短期记忆单元,Long Short Term Memory):
LSTM 虽然比 GRU 发表更早,但其功能更加复杂,除了更新门其还引入了遗忘门 和输出门 。因此GRU可视为LSTM的精简版本。 其结构如下:
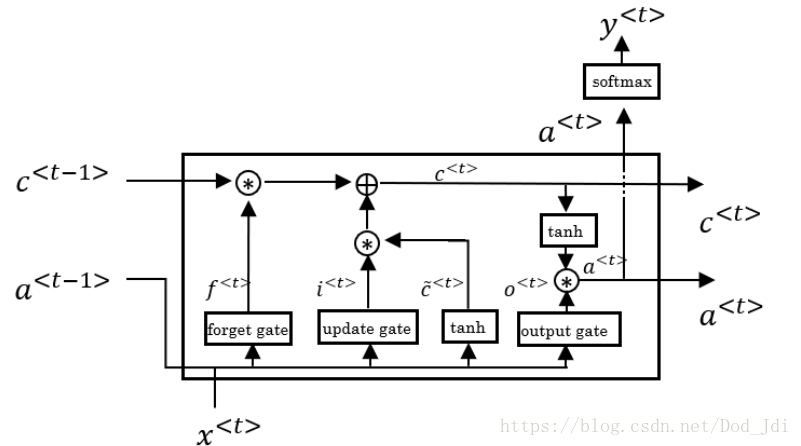
如果参数适当,各个门和输出可以沿着 的路径窥视上一层的记忆细胞,称为窥视孔连接(Peephole Connection)。
LSTM公式如下(门计算出概率, 为值,相乘类似交叉熵 ylogy 都是概率和值相乘):
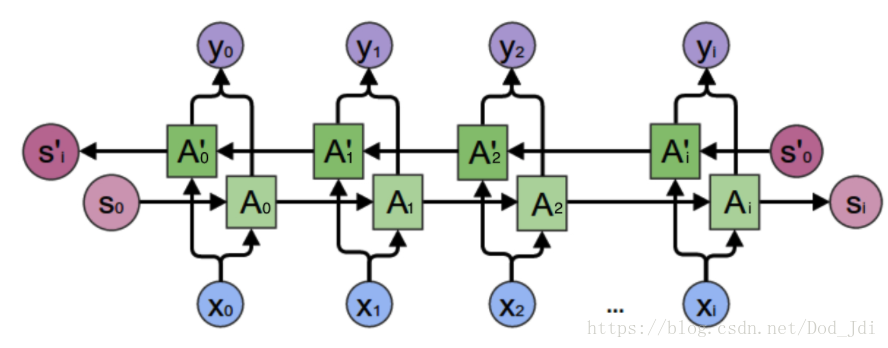
双向循环神经网络(BRNN):
前面所说的都是单向循环神经网络,其只用前面的序列因子作用于后面,而双向循环神经网络(Bidirectional RNN,BRNN)同时使用了序列间前后元素的互相影响:
深度循环神经网络(DRNN):
与 DNN(深度神经网络一样)使用
表示层数(但一般3层作用不会有100层这样):
2、自然语言处理与词嵌入
词汇表征和词嵌入:
自然语言中国的词汇具有许多特征(表征),如近似(King 和 queen)和种类(orange 和 apple)等。前面利用字典形成的 ont-hot 编码,各个词语间的编码是独立、正交的,不能够体现词语间的这种特征联系。
将词语的这些表征嵌入到一个向量之中形成具有一定关联的向量编码叫做词嵌入(Word Embedding),嵌入过程所使用的矩阵叫做嵌入矩阵(Embedding Matrix),用 E 表示,得到的结果叫做嵌入向量(Embedding Vector)或者词向量,用小 e 表示。为了避免混淆,在下文中用(单)词向量(word vector)和 e 表示,而不用嵌入向量。
假设字典中有10000个词语,统计其中的300类表征,将词语的特征表征量化为 [-1,1] 之间,嵌入矩阵 E 就类似于下面这个表:
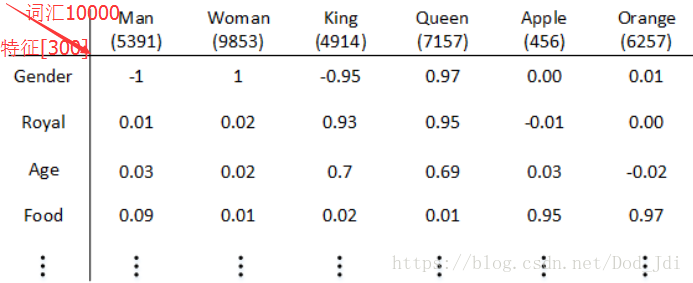
利用 ont-hot 编码和上表(嵌入矩阵 E)相乘得到词向量 e,类似掩码操作,即 :
实际过程并不一定会有这样的特征表格,一般可以使用神经网络来进行训练得到类似的效果,在别人海量词汇训练基础上进行迁移学习可以得到不错的效果,而 e[1,300] 实际上类似于神经网络利用了其词汇表征经过训练得到的编码结果,和人脸识别中的全连接层的编码类似,都可以通过比较不同对象的编码来得到相似值。
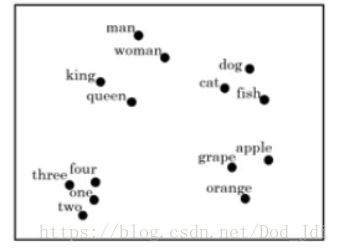
上述嵌入向量在一个300维的空间上标识了一个词汇及其特征,可以使用 t-SNE 的算法将其降维至2 维平面上进行观察:
学习词嵌入:
学习词嵌入就是如何通过神经网络得到词汇的嵌入矩阵的过程,通过嵌入矩阵我们可以很容易的得到嵌入向量从而进行后续的计算。
在获取词汇的嵌入矩阵时我们不可能对10000个甚至更多得多的词汇进行特征量化,而且和卷积网络的特征提取过程一样,这些“特征”很可能是没有具体意义的也没办法直接量化的。因此需要进行类似人脸识别的过程,输入词汇 的 ont-hot 编码经过神经网络得到嵌入矩阵,视频中介绍的算法有 Word2Vec 和 Glove。
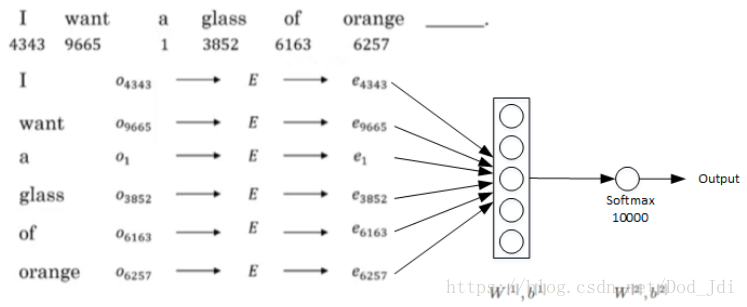
既然词嵌入矩阵的获取并不简单,为什么还要想办法去得到词汇的嵌入矩阵呢,举个栗子,通过输入上下文Context,利用嵌入矩阵 E 得到嵌入向量 e 作为神经网络的输入,即可以预测目标target 输出(juice),这对于文字识别和机器翻译等有积极的意义:
Word2Vec :
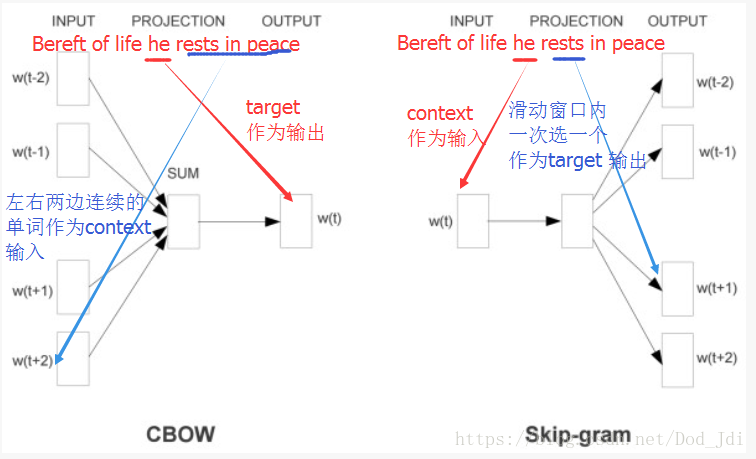
Word2Vec 是通过训练获取词汇嵌入矩阵的一种算法,有 Skip-Gram 和 CBOW(Continuous Bag of Words)两种模型。主要计算 Context 和 Target 共同出现的可能性从而得到其共有的表征。
Skip-Gram 通过指定词获取(伪预测)上下文特征,其指定一个单词作为上下文(c:Context),设置一个自定义宽度(一般5~10)的滑动窗口, 每次在滑动窗口内选择一个单词作为目标(t:Target),通过输入 X:Context 和 Y:target 进行监督训练,训练完成后的参数 即是表征参数(c 和 t 的关联参数,即前的Word Vector),全连接层为嵌入向量 e 。这类通过建立模型实际为了获取输入特征的神经网络可称为“Fake Task”。
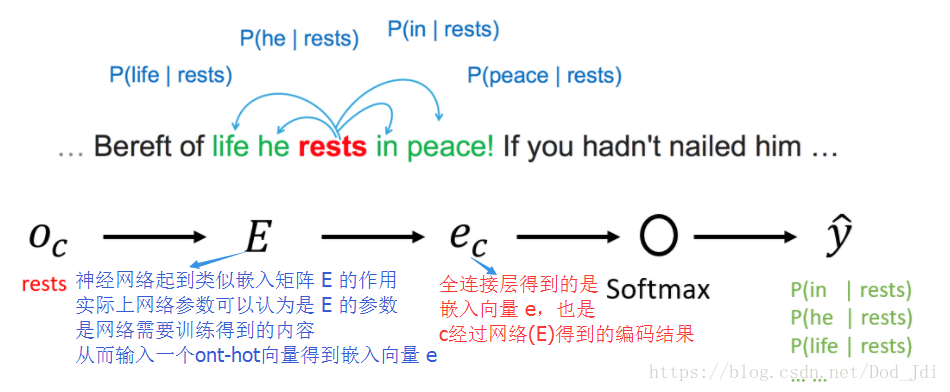
模型输出为,有下标的 e 表示全连接层的嵌入向量,没有的是指数运算:
损失函数为:
CBOW 则是根据连续的上下文预测目标词。和 Skip-Gram 相反,CBOW 通过输入连续的上下文然后通过神经网络预测目标词,这里的预测是“真的预测”,其全连接层是和输出直接相关的,训练完成的全连接层其实就是输出单词的词向量 e。相较而言, Skip-Gram 的全连接层是输入层的编码结果(词向量 e),其设定的输出也只是为了完成参数的训练,因此为“假的预测”。
CBOW 和 Skip-Gram 模型对比如下:
负采样:
在 Skip-Gram 的softmax层分类时如果计算10000个类计算量太大,一个解决方法是采用分级的softmax分类器,类似于二叉树。在实践中常采用霍夫曼树而非平衡二叉树,将常用词放在顶部提高效率。另一种方法就是负采样。
负采样的思想和人脸识别有些类似,其将context旁边的词作为正例,又另外取一些反例(即负采样)作为训练样本,减少了输出的类别。
正如人脸识别中不会随机取反例一样(人脸识别取的是相近的反例),为了提高模型的有效性,一些科学家采用类似于随机的方式选取,每个字典中单词被选取为负样本的概率为(好像是说通过经验来的,不然 the,of等词概率太大),wi 表示该词在字典中出现的频率:
GloVe :Global vectors for word representation
Word2Vec 是一次通过一句话来训练嵌入矩阵,从而得到全连接层的编码结果嵌入向量。而GloVe 直接统计语料库中所有(Global)语句中两个单词同时出现的次数 ,称为共现矩阵。
在不考虑先后顺序时,存在对称关系:
, 也就是说当输入j 时,其通过模型计算得到的出现 i 概率应该和实际 i 的概率相等(输入 j 的词向量,经过模型计算(即和嵌入矩阵相乘)得到 i 的词向量),即计算得到的 one-hot 编码(维度[10000,1])和 softmax层输出(维度[10000,1])应该尽可能一致:
,和上面 Word2Vec 的模型类似, 因此损失函数为:
上面损失函数有2个缺点,一是可能出现 log0, 二是过于平均,引入一个相关权重因子 ,我们希望当两个词汇共同出现次数高时(相关性大)其权重因子大,而出现次数为 0 时其为0就可以避免计算 log0 ,即是递增的,但又不希望权重过于大影响模型,论文作者取值为:
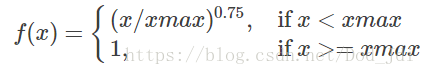
最后将相关权重因子和偏置项添加,损失函数为:
情感分类:
这里指通过一句话分析其情感:

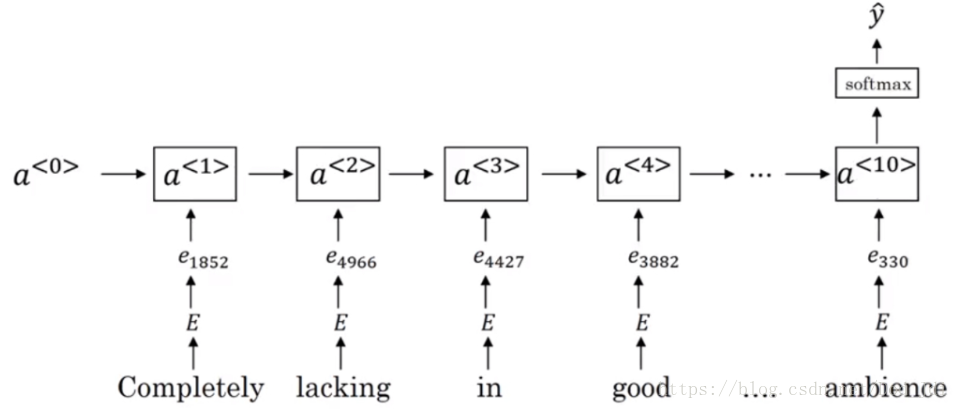
我们可以使用嵌入矩阵来进行训练,将句子中的词汇的嵌入向量(词向量)Embedding Vector输入取均值,评分作为输出进行监督训练:
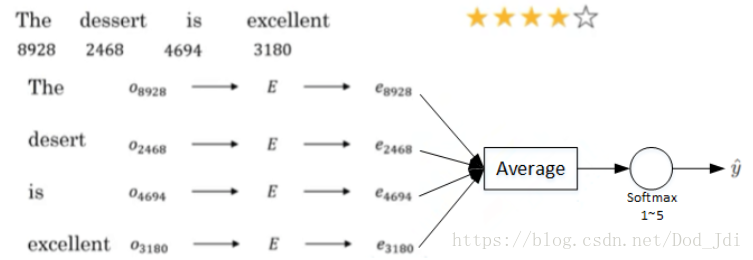
但是这样有时候容易导致混乱,例如最后一句:Completely lacking in good taste, good service, and good ambience. 出现了三个good,如果使用均值其应该偏向于高评价,但由于前面存在 lacking 结果正好相反。因此可以使用 RNN 中的记忆单元进行改进。
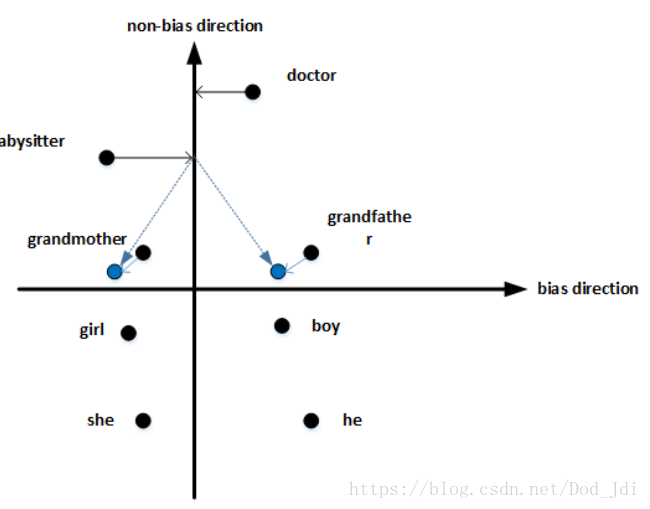
词嵌入除偏(中性化):
在词汇的嵌入矩阵中可能在某个维度上存在某种偏向,例如职业性别歧视:Father: Doctor as Mother: Nurse。我们应该利用有利的偏向,去除这些不好的偏向。
知道哪些词汇需要进行中立化操作是比较重要的事情(视频说职业、身份等词),对这些词计算的得到偏差方向,然后投影到其正交方向,以消除在偏差方向上的偏差(距离)。
3、序列模型和注意力机制
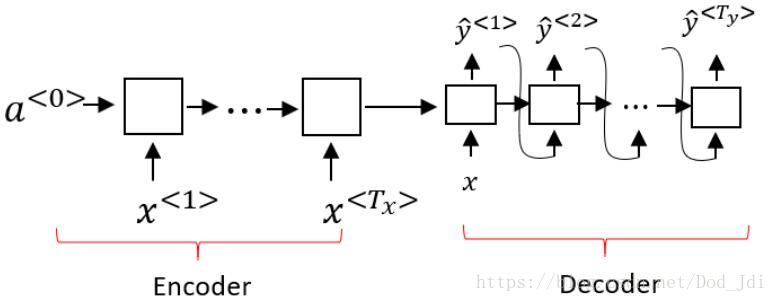
Seq2Seq模型:
Seq2Seq(Sequence to Sequence)模型就是将一个一个输入序列通过中间件转化为一个新的输出序列。其模型是一个编码器(Encoder)和一个解码器(Decoder)的组合。该模型是机器翻译和语音识别应用的重要模型之一。
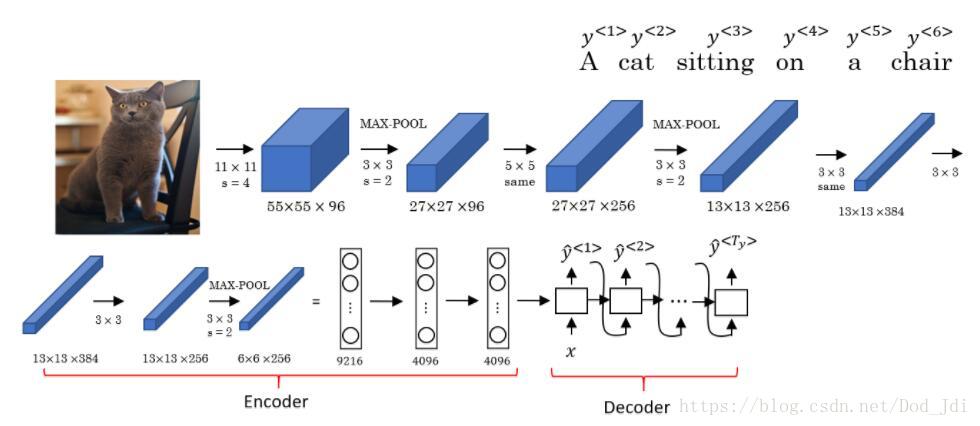
和CNN卷积网络以及上面的词嵌入类似,seq2seq模型的编码器就是提取输入序列的特征,然后由解码器形成新的序列。当然,这种特征应该是与输入序列和输出序列相关的,例如中英翻译,其编码过程可以是有这两种语言共同参与训练出来的词嵌入过程(获得词向量的编码过程),而解码部分相反。
集束搜索:
假设seq2seq的输出是一个词汇序列,那么如何将这个序列组合成一个正确的句子(不同语言的词汇前后顺序可能不一样,如状语前置等)?
我们知道,上述模型单元输出不是一个特定的词汇而是一组词汇的概率。假如使用贪心算法,从左往右对每个单元选择概率最大的一个词汇,可能对词组翻译效果尚可,但是对于句子翻译就可能导致前面所说的“不正确”问题。
一个解决办法是使用集束搜索(Beam Search)。集束搜索的关键思想是广度优先和剪枝:
1、它通过设立一个集束宽度(Beam Width,假设3),在这一层(这个时间片)遍历,选取 3 个概率最大的词汇并去掉其他词汇(剪枝),得到 3 个第一步的概率
2、 然后进入下一层(下一个时间片,先本层在下一层,广度优先),同样选择 3 个概率最大的词汇,其概率为:
3、继续这样在广度上选择特定宽度个数概率最大的节点,然后从这些节点出发往更深处遍历。(相关知识广度优先,启发式,n-gramr)
4、这样直至结束会有 3x3x3x…x3 (即
)个待选项 , 选择其中概率最大的一个:
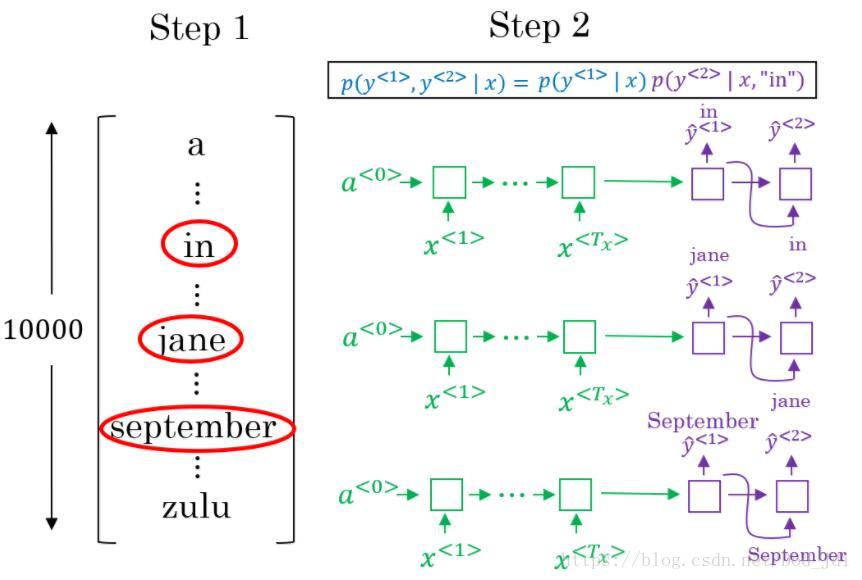
Bleu Score:评价多个翻译结果的方法。选修,这里也不详将,大概就是连续词语出现太多次可能没那么好(吃法不吃饭? VS 吃饭不?)
注意力机制:
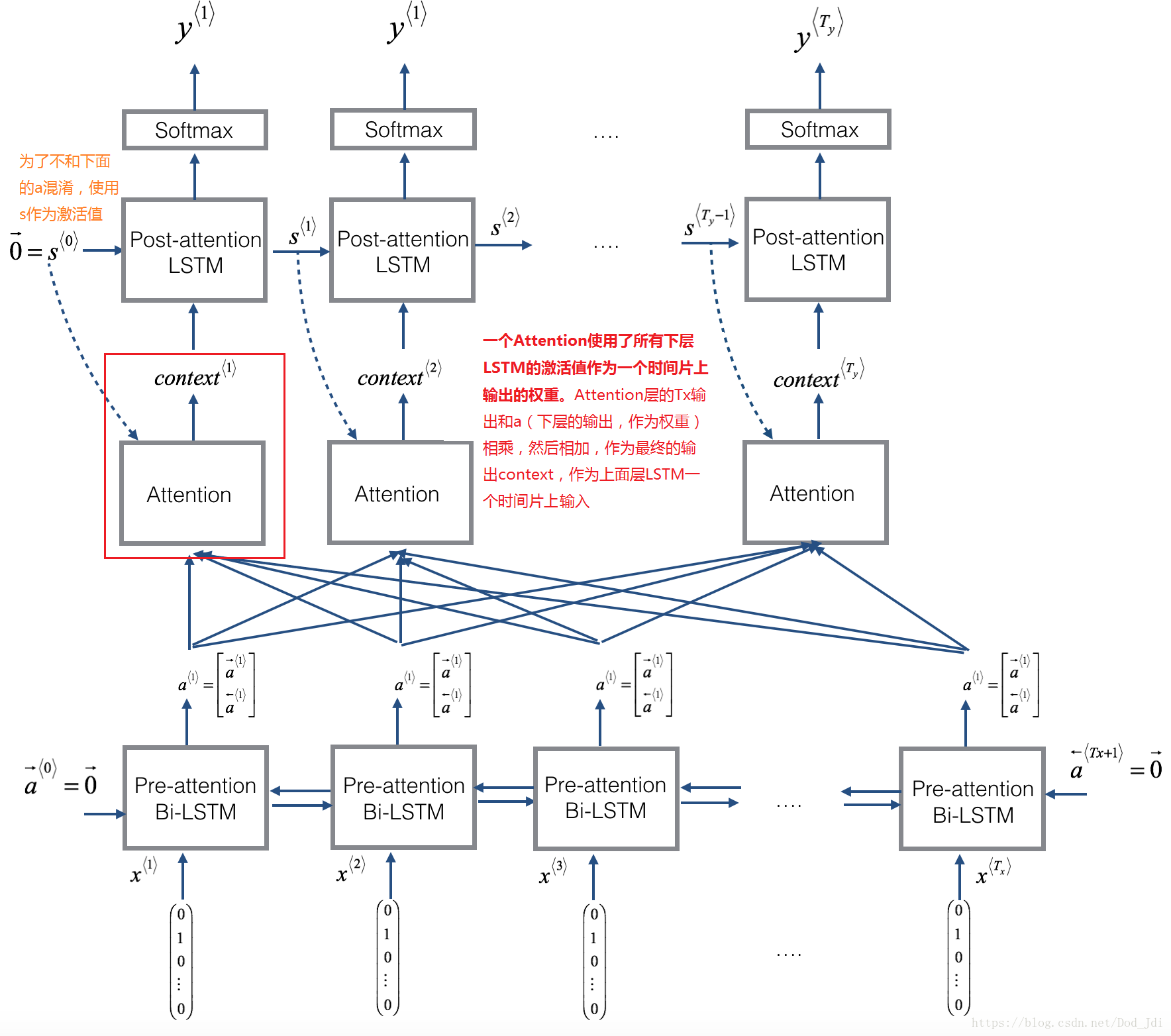
模型: 分为 Encoder层,Attention层 和 Decoder层。
将 Encoder层 的每个时间片的激活值 拷贝 Tx 次然后和全部激活值 a (Tx个时间片) 串联作为Attention 层的输入,经过Attention层的计算输出 个阿尔法 ,使用不同激活值 a 作为不同阿尔法 对每个单词的注意力权重,相乘,即 ,然后将 个这样的相乘作为attention层的输出,即作为 decoder层 一个时间片上输入参与后续运算。
主要思想是将一个时间片的激活值分别和不同的单词注意力权重(使用不同时间片的激活值作为权重)相乘。
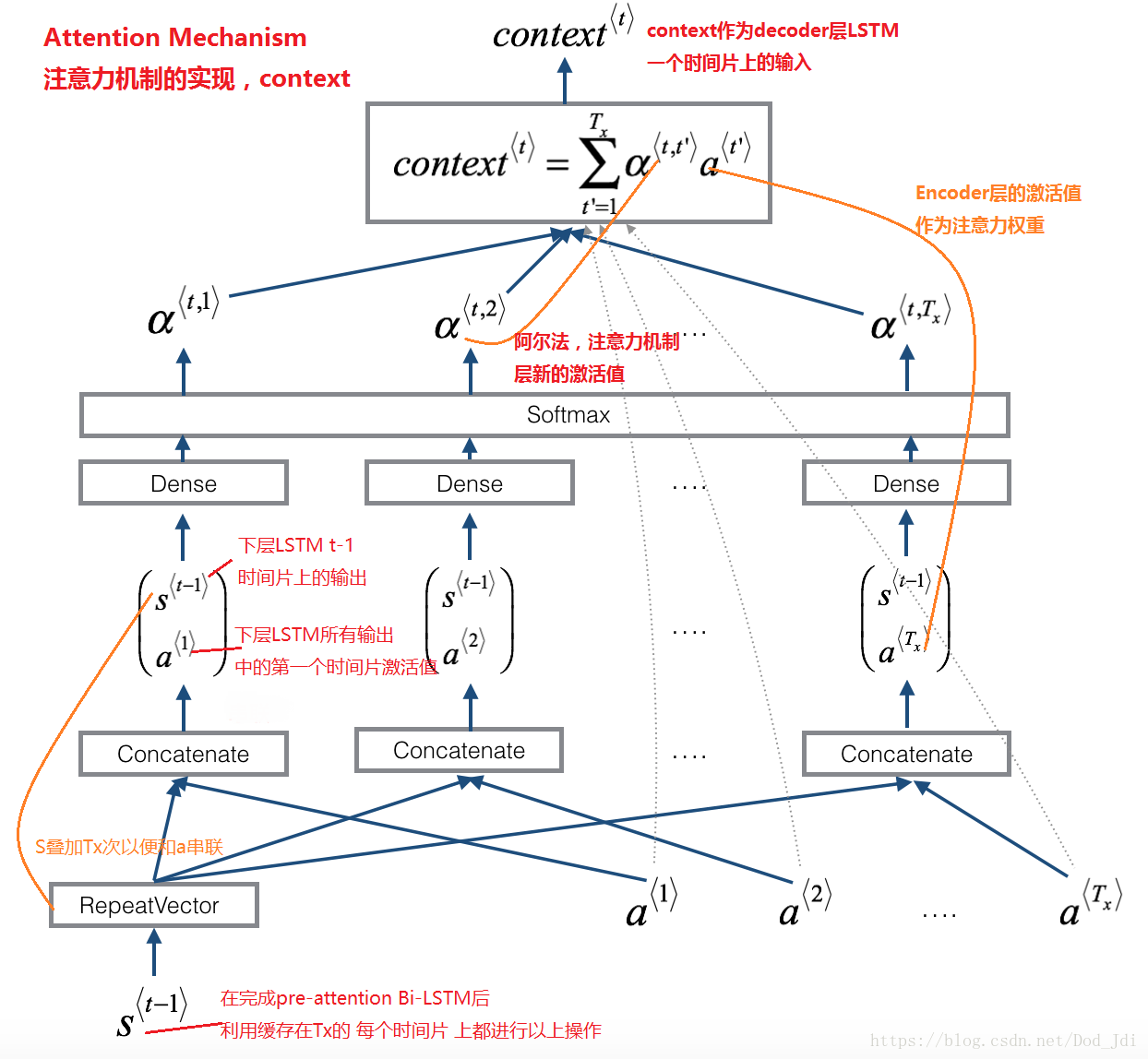
下图是上图的 一个 Attention 到 context 部分,也是Attention mechanism(注意力机制)的实现:
4、结语
老吴还是讲得好啊,虽然没听懂多少,有点急于求成吧,作业没不是自己想的,不过感觉还是挺有收获,值得推荐。
我在听课的时候没做多少笔记,关于这个课程笔记主要是从参考下面两位大佬的文章以及回看视频写的,当然还有一些别的参考文章,不过写的时候没注意地址,表示抱歉:
github bighuang624/Andrew-Ng-Deep-Learning-notes: http://kyonhuang.top/Andrew-Ng-Deep-Learning-notes/#/
csdn 红色石头的专栏:https://blog.csdn.net/red_stone1
挖个坑,下一步的主要内容计划是把深度学习这么课程的编程作业做个总结,主要包括一些模型的思想、主要步骤和主要代码。