第二周 优化算法
2.1 & 2.2 Mini-batch梯度下降法
之前所提到的梯度下降法其实指的都是 batch gradient descent,每一次进行梯度下降都要对整个数据集进行前向传播。当数据集的规模较大时,计算很慢。
Mini-batch gradient descent 则是将整个数据集分成多个小块,每一次梯度下降只利用一小块的数据,这样计算速度更快。每次遍历完整个数据集称为一个epoch(读作“一破壳”),显然每个epoch可以进行多次梯度下降,而根据实际训练的需求可以进行多个epoch.
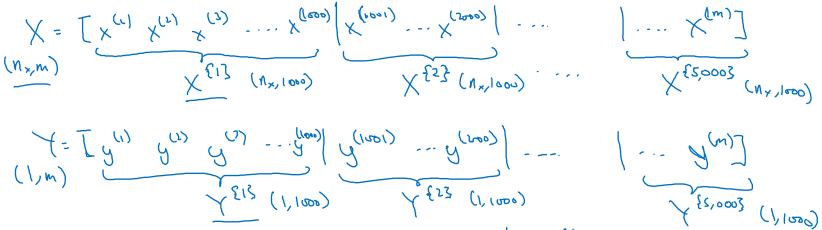
新的符号表示,每个mini-batch记为 \( X^{ \{t\} } \),区别于之前提到的两种表示。
Mini-batch 梯度下降中的 batch size 是一个需要调节的参数:
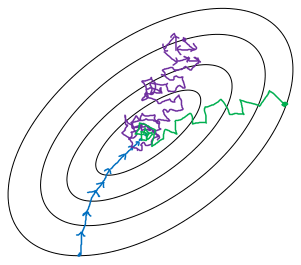
- batch size = m : 等同于batch gradient descent,学习率合适的前提下可以确保代价函数单调下降,缺点说过了,一次梯度下降的计算量大
- batch size = 1 : 等同于stochastic gradient descent(随机梯度下降,SGD),单个样本进行学习,效率低,代价函数的值波动较大
- 1 < batch size < m : 介于上面两者中间
三种情况下的示意图如下图,当 batch size 不等于 m 时,计算得到的梯度不是代价函数真正的梯度,所以中间会出现错误的方向。而随着 batch size 的增大,方向会越来越准确。
关于 batch size 的设置,有以下两个建议:
训练集较小(m < 2000):直接用 batch gradient descent
训练集较大时的常用设置:64, 128, 256, 512(2的n次方),具体要通过试验确定,还要适合CPU/GPU的内存。
2.3 & 2.4 & 2.5 指数加权平均
指数加权平均(exponentially weighted averages)实现时表现为滑动平均,但累积的最终效果是指数加权平均。
先看真正的递推平均值(各时刻等权重)如何计算:
\( \begin{aligned}v_t &= \frac{1}{t} \sum_{k=1}^t \theta_k \\ &= \frac{1}{t} (\sum_{k=1}^{t-1} \theta_k + \theta_t) \\ &= (1 - \frac{1}{t})v_{t-1} + \frac{1}{t}\theta_t \end{aligned} \)
再看指数加权平均的公式:
\( v_t = \beta v_{t-1} + (1 - \beta) \theta_t \)
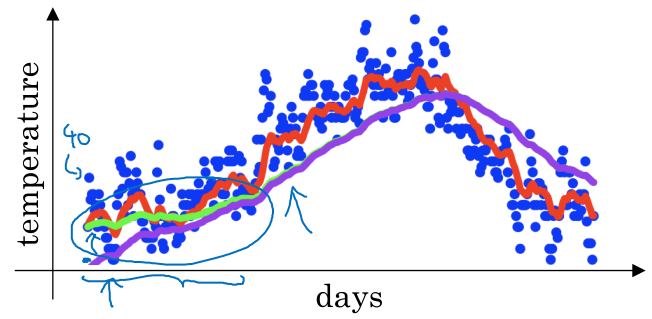
公式的意思是:当前时刻的平均值等于前一时刻的平均值与当前时刻瞬时值的加权平均。由于当前时刻的瞬时值 \( \theta_t \) 所占的比例只有 \( (1-\beta) \),所以最终结果可以近似地看作是 \( \frac{1}{1-\beta} \) 个时刻的平均值。\( \beta \) 越小,平均的天数越少,反之同理。
严格的说,如果按上面的递推公式展开,可以发现前面各时刻的值并不是等权重的平均,而是以指数衰减的权重进行加权平均,这也是“指数加权平均”名字的由来。这样做的道理是:相距越远的时刻对当前时刻的贡献就越小。
实现指数加权平均时,如果直接采用下面的做法:
\( \begin{aligned} v_0 &= 0 \\ v_1 &= \beta v_0 + (1-\beta) \theta_1 \\ & \dots \end{aligned} \)
在递推计算的初期会产生偏差,如下图。如果不在乎初期的结果,那就不用管了,但如果对初期结果也要求尽量准确的话,需要进行额外的偏差修正,即用 \( \frac{v_t}{1-\beta^t} \) 代替 \( v_t \),可以看到当 \( t \) 足够大时,\( 1-\beta^t \approx 1 \)。
2.6 动量梯度下降法
将前面介绍的指数加权平均应用到梯度下降中,就可以得到带动量(momentum)的梯度下降法,具体实现如下:
\( \begin{aligned} v_{dW} &= \beta v_{dW} + (1 - \beta)dW \\ v_{db} &= \beta v_{db} + (1 - \beta)db \\ W &= W - \alpha v_{dW} \\ b &= b - \alpha v_{db} \end{aligned} \)
可以看到我们在更新参数时并不直接利用梯度,而是梯度的指数加权平均,从物理的角度理解,每个时刻的梯度起到加速度的作用,对整体的动量产生一定影响。
在动量梯度下降中一般不考虑偏差修正,当然考虑了也没问题。
采用这种动量梯度下降将引入两个超参数 \( \alpha, \beta \),通常取 \( \beta=0.9 \),实践证明这是一个非常稳健的值。
还有可能会遇到一种不同表示的动量计算方法:\( v_{dW} = \beta v_{dW} + dW \). 本质是一样的,只是采取这种表示会影响学习率大小的选择。
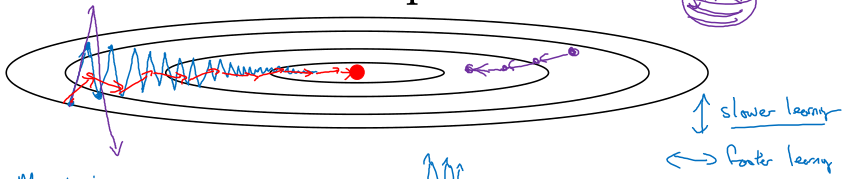
采取动量梯度下降可以一定程度上解决原来梯度下降法存在的抖动问题,还可以采用更大的学习率,是一定优于原来梯度下降法的优化方法,用起来~
2.7 RMSprop
RMSprop同样是为了解决不同方向学习速率不同的问题,可以直观的想到在抖动较大的方向更新的小一些,在抖动较小的方向更新的大一些。
\( \begin{aligned} S_{dW} &= \beta_2 S_{dW} + (1-\beta_2) (dW)^2 \\ S_{db} &= \beta_2 S_{db} + (1-\beta_2)(db)^2 \\ W &= W - \alpha \frac{dW}{\sqrt{S_{dW} + \epsilon}} \\ b &= b - \alpha \frac{db}{\sqrt{S_{db} + \epsilon}} \end{aligned} \)
可见,在抖动较大的方向,\( S_{dW} \) 累积的更大,因此参数更新的也就更小,达到了和动量梯度下降同样的目的。其中为了数值稳定(防止除0),一般取 \( \epsilon = 10^{-8} \)
2.8 Adam
Adam优化算法就是Momentum算法和RMSprop的结合,真的是结合,不信请看:
\( \begin{gathered} v_{dW} &= \beta_1 v_{dW} + (1 - \beta_1) dW, \quad v_{db} &= \beta_1 v_{db} + (1 - \beta_1)db \end{gathered} \)
\( \begin{gathered} S_{dW} &= \beta_2 S_{dW} + (1 - \beta_2) (dW)^2, \quad S_{db} &= \beta_2 S_{db} + (1 - \beta_2) (db)^2 \end{gathered} \)
\( \begin{gathered} v_{dW}^{c} &= \frac{v_{dW}}{1-\beta_1^t}, \quad v_{db}^c &= \frac{v_{db}}{1 - \beta_1^t} \end{gathered} \)
\( \begin{gathered} S_{dW}^c &= \frac{S_{dW}}{1-\beta_2^t}, \quad S_{db}^c &= \frac{S_{db}}{1 - \beta_2^t} \end{gathered} \)
\( \begin{gathered} W &= W - \alpha \frac{v_{dW}^c}{\sqrt{S_{dW}^c + \epsilon}}, \quad b &= b - \alpha \frac{v_{db}^c}{\sqrt{S_{db}^c + \epsilon}} \end{gathered} \)
注意Adam算法要求进行偏差修正。
这里面看起来有很多超参数,但其实也简单。学习率 \( \alpha \) 还是要自己进行调节,\( \beta_1 = 0.9, \beta_2 = 0.999 \) 是比较合适的选择(一般人不用调节),\( \epsilon = 10^{-8} \) 这个不影响学习结果。
2.9 学习率衰减
学习率设置的准则一般是随着训练的 epoch 增加要逐渐减小,因此诞生了诸多学习率衰减策略:
- \( \alpha = \frac{1}{1 + \text{decay_rate} * \text{epoch_num}} \alpha_0 \)
- \( \alpha = 0.95^{\text{epoch_num}} * \alpha_0 \)
- \( \alpha = \frac{k}{\sqrt{\text{epoch_num}}} * \alpha_0 \)
- 离散衰减(每隔一定 epoch 减半学习率)
- 手动衰减
2.10 局部最优问题
以前人们总是担心机器学习中各种各样的优化问题会陷入局部最优,而现在深度学习中的认识不太一样:
- 在一个很高维的参数空间中很难陷入一个非常差的局部最优点(要在各个方向都是凹形,概率小);
- 更多的问题是鞍点,由于鞍点在较大的范围内梯度平缓,优化过程会变的很慢,前面提到的改进优化算法一定程度上可以加速优化过程