记忆力是真的差,看过的东西要是一直不用的话就会马上忘记,于是乎有了写博客把学过的东西保存下来,大概就是所谓的集巩固,分享,后期查阅与一身的思想吧,下面开始正题
深度学习概论
什么是神经网络
什么是神经网络呢,我们就以房价预测为例子来描述一个最简单的神经网络模型。
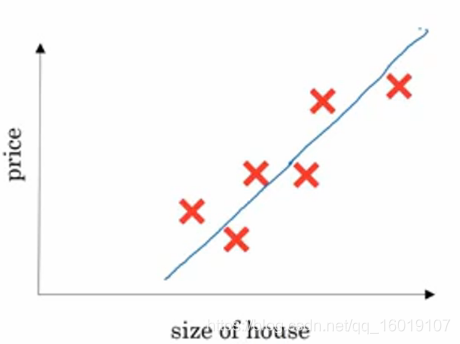
假设有6间房屋的数据,已知房屋的面积,单位是平方英尺或者平方米,已知房屋的价格,想要找到一个函数,通过房屋的面积来预测房屋的价格。
如下图所示

要通过这些点预测房屋价格,最直观的方法就是线性拟合,于是我们得到:
同时我们加入约束,即房价并不为0(或者以非线性的形式最后与0,0点相交)

这就是最简单的神经网络了,我们把房屋的面积作为神经网络的输入,x,通过一个节点,最后得到输出房屋价格y。如下图所示:

在神经网络中,我们把这个节点称为神经元,在上述例子中,这个神经元做的事情就是输入面积,完成线性运算取不小于0的值(或其他约束条件),最后得到输出,预测的价格。

在神经网络中这个函数形式是非常常见的,我们把这种形式的函数称之为ReLU函数ReLU中文解释为“修正线性单元”,其中修正指的就是取不小于0的值,我们将在以后重点介绍ReLU函数。
上述的预测模型就是最简单的单神经元网络,多个单神经元堆叠的组合就形成了复杂的神经网络。
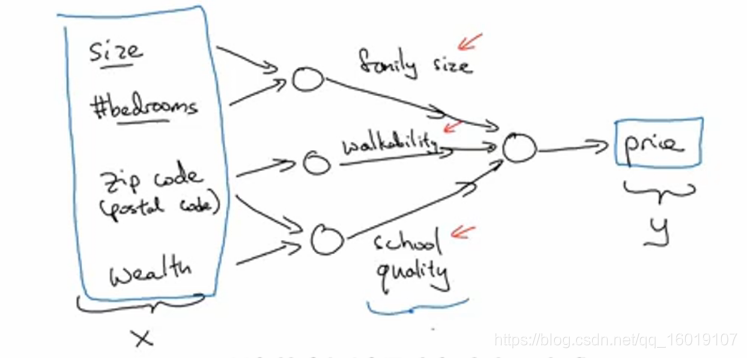
现在我们尝试把上述简单的房价预测模型复杂化,使它更具现实意义。除了单纯的房屋面积,我们还知道了其他信息,如卧室的数量、邮政编码和富裕程度。家庭的人员数量某种程度上决定了这个家庭的房屋面积和卧室数量,是三口之家(2个卧室)、四口之家(3个卧室)等等。此外,邮政编码能够作为特征描述某区域的步行化程度,有些人喜欢高度步行化的区域。同时,邮政编码还可以描述附近的学校质量。而这个区域的富裕程度也会影像附近的学校质量。这样我们就根据房屋大小,卧室数量,邮政编码和富裕程度四个已知条件通过各自对应的ReLU函数得到家庭人数,步行化程度,学校质量三个指标,而这3个指标可以帮助我们预测最后房屋的价格。如下图所示:我们通过这些独立神经元的叠加,就得到了一个相对较大的神经网络。
在这个过程中,我们实际做的事情就是输入若干特征比如房屋大小,卧室数量,邮政编码,富裕程度,最后神经网络会给出房屋的预测价格,下图中箭头所指的圆圈在神经网络中被称为隐藏单元,没个隐藏单元的输入都同时来自前面的四个特征,比如在这个例子中,我们不会说第一个隐藏单元代表的是家庭人口,亦或是它只与X1,和X2有关系,神经网络会自己去决定这个单元是什么,我们只会给它所有的输入,它自己去根据数据的特点得到最后的输出。
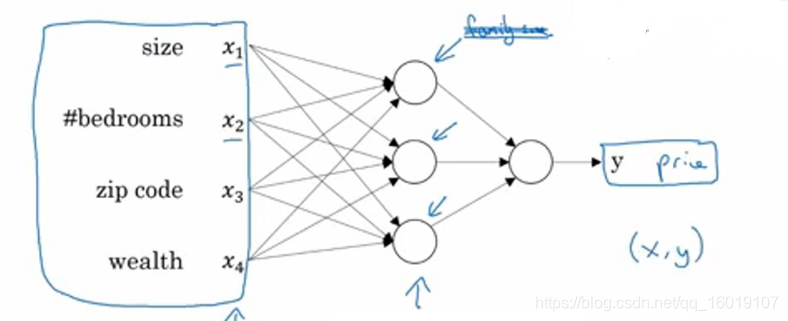
因此,我们给网络喂足够多的数据样本(X,Y),神经网络会自己根据这些训练样本学习出X与y精确的映射函数。从这点上看神经网络就是一种高级的,复杂的,智能的,函数拟合过程。
神经网络的本质:监督学习
现在神经网络被媒体吹的神乎其神,虽然有夸大其词的成分,但是其中有一部分还是实实在在创造了不少经济价值的。神经网络是包含于机器学习这门大学科中的,而它的大部分的实际应用,其实本质都是基于机器学习的其中一种方式:监督学习(Supervised Learning)。
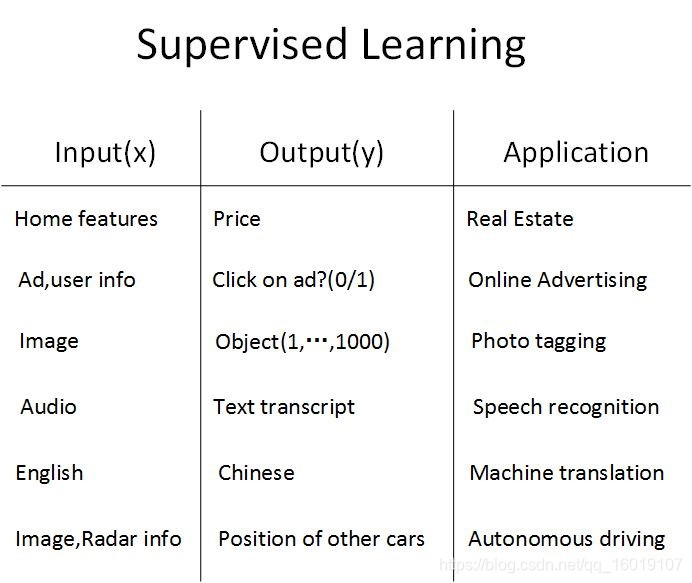
在监督学习中,我们输入一个x,学习得到一个函数,映射得到最后的输出y,在房价预测中,我们输入房屋特征,最后输出房屋的预测价格。 下面是神经网络效果拔群的一些应用。比如在在线广告领域,我们输入广告以及一定的用户信息,比如,历史记录中哪些人会点击哪些广告,最终,网站就会考虑是否给你看这个广告,或者给你推送你最有可能点开的广告。随着深度学习的发展,计算机视觉也有进展,我们可以输入一幅图像,最后输出一个指数(比如0-1000中的某个值),表示这幅图像是区别于其他1000种类型的图像,可以对照片打标签。在语音识别领域,我们输入一段语音,最后输出一个文本。机器翻译领域发展也相当迅速,我们可以输入一段英语,最后输出得到相同意思的中文。最近非常热的自动驾驶领域中,我们输入车头拍摄的实时影像以及相应的车载雷达信息,系统就能告诉你路上其他汽车的位置,以便于无人驾驶。从上面我们可以看到略微不同的神经网络可以应用到不同的领域,且效果很好。比如房价预测和在线广告领域,使用的都是相对标准的神经网络(standard neural network),在图像识别领域,用到的大部分都是卷积神经网络(CNN)。语音识别,机器翻译等领域,使用的数据都是序列数据(语音,句子等等),因此使用的都是循环神经网络(RNN)。对于更加复杂的无人驾驶领域,则需要多种网络同时使用。
下面是三种相对常用的神经网络,适用于各自擅长的领域
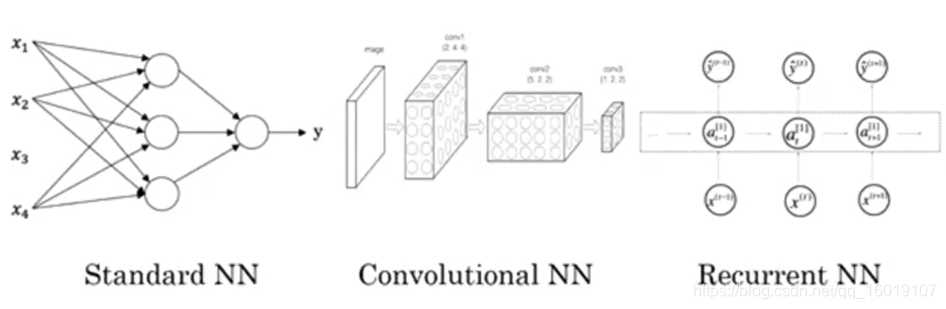
除了算法,我们在监督学习中输入的数据一般被分为结构化数据和非结构化数据,如下图所示:
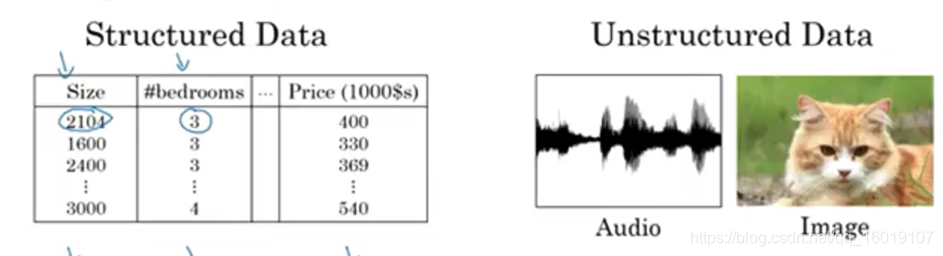
不难看出来,结构化数据就是属性相对明确的,代表的含义非常确定的数据,更像一个数据的数据库,譬如在房价预测当中的输入如房间大小,卧室数量等等。而非结构化数据主要指的就是属性不是相对明确的,比如图像,音频,文字等等,这些数据当中的特征可能是像素,文字等等,在计算机处理的过程中,非结构化数据相比结构化数据更难理解。但是深度学习和神经网络的发展,使得我们处理这类数据能力有了非常大的提高。
深度学习的兴起
其实深度学习的理论已经发展了很久了,为什么深度学习近几年才开始兴起呢?

上图是传统的机器学习算法在数据量变化时,算法表现(准确率)相对应的变化图,我们可以看到,在数据量相对较小的时候增加数据量可以提高传统机器学习算法的表现,但是当数据量大到一定程度时,传统机器学习算法的性能会进入平台期,即不管你数据量怎么增大,最终性能达到瓶颈,不再提升。因此,在过去数据匮乏的年代,传统机器学习的算法是主流。但是随着科技的发展,我们能获取到的数据越来越多。我们发现神经网络在处理大数据量的过程中表现出来的性能要远远超过传统机器学习。如下图所示

我们可以看到,当数据量不断增大时,越复杂的神经网络的性能越晚进入平台期,且都远远超过了传统机器学习算法。除此之外,我们可以看到当数据量较小时,神经网络面对传统机器学习算法并没有特别的优势,甚至通过算法的优化,传统机器学习算法的性能还会超越神经网络。虽然神经网络不是万能的,但是它的流行是不可避免的,因为它更符合当下数据爆炸的时代。
除了数据之外,越复杂的神经网络意味着更加多的计算量,庞大的计算量和计算能力需要硬件的支持,近几年如GPU,CPU等硬件的发展,也为深度学习的流行奠定了基础。同时深度学习本身算法的创新更是极大加快了在利用海量数据拟合最后的模型过程所耗的时间(将sigmod函数替换为ReLU单元),使得深度学习工作者可以加快自己的创新性研究,从而推动整个领域的发展。
学无止境,共勉。