第四周 深层神经网络
4.1 & 4.2 深层神经网络
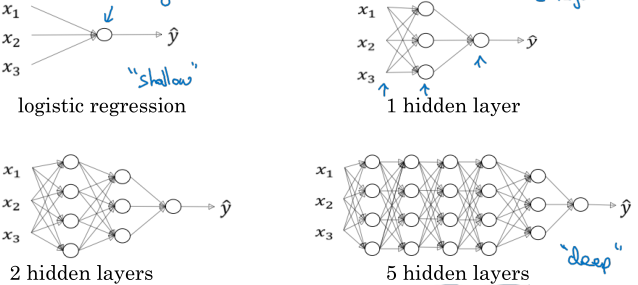
logistic回归模型可以看作一层网络,通过增加隐藏层的层数,就可以得到深层网络了。
4.3 检查矩阵的维数
确保神经网络计算正确的有效方法之一就是检查矩阵的维数,包括数据矩阵、参数矩阵等。注意深度学习或者说编程时所说的矩阵维数往往指的是矩阵的形状,并不是严格的数学概念。
数据矩阵的维数:行数等于特征数,列数等于样本数;
参数矩阵的维数:行数等于下一层神经元的个数,列数等于当前神经元的个数。
\( Z^{[l]} = W^{[l]}A^{[l-1]} + b^{[l]} \)
\( W^{[l]}:(n^{[l]}, n^{[l-1]}), \qquad Z^{[l]},A^{[l]}:(n^{[l]}, m) \)
反向传播时,注意梯度矩阵应与对应的参数矩阵维数相同。
4.4 为什么使用深层表示
为什么用这么多层,一种理由是在解决视觉或者语音问题过程中,分层意味着不同层次特征信息的提取;另一种理由来自电路理论,有一些问题使用浅层网络的复杂度要远超过深层网络。
其实我觉得最重要的理由还是:实际效果好。炼丹嘛!
4.5 & 4.6 搭建深层网络块、前向和反向传播
完整的深层网络由一层层神经元叠加组成,搞清楚了每一层的前向和反向传播计算原理就搞清楚了整个神经网络的基本原理。每一层的示意图如下:
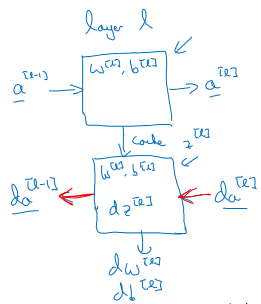
划重点!
前向传播:
- 输入:\( a^{[l-1]} \)
- 中间计算:\( z^{[l]} = W^{[l]}a^{[l-1]}+b^{[l]},\quad a^{[l]} = g^{[l]}(z^{[l]}) \)
- 输出:\( a^{[l]} \),缓存 \( z^{[l]} \)
反向传播:
- 输入:\( da^{[l]} \),加上缓存的 \( z^{[l]} \)
- 中间计算:
- \( dz^{[l]} = da^{[l]} * g^{[l]'}(z^{[l]}) \)
- \( da^{[l-1]} = W^{[l]^T} dz^{[l]} \)
- \( dW^{[l]} = dz^{[l]} a^{[l-1]^T} \)
- \( db^{[l]} = dz^{[l]} \)
- 输出:\( da^{[l-1]} \)
下面是多样本的向量化实现:
前向传播:
- 输入:\( A^{[l-1]} \)
- 中间计算:\( Z^{[l]} = W^{[l]}A^{[l-1]}+b^{[l]},\quad A^{[l]} = g^{[l]}(Z^{[l]}) \)
- 输出:\( A^{[l]} \),缓存 \( Z^{[l]} \)
反向传播:
- 输入:\( dA^{[l]} \),加上缓存的 \( Z^{[l]} \)
- 中间计算:
- \( dZ^{[l]} = dA^{[l]}*g^{[l]'}(Z^{[l]}) \)
- \( dA^{[l-1]} = W^{[l]^T}dZ^{[l]} \)
- \( dW^{[l]} = \frac{1}{m}dZ^{[l]}A^{[l-1]^T} \)
- \( db^{[l]} = \frac{1}{m}np.sum(dZ^{[l]}, axis=1, keepdims=True) \)
- 输出:\( dA^{[l-1]} \)
多层神经网络叠加起来的示意图如下:
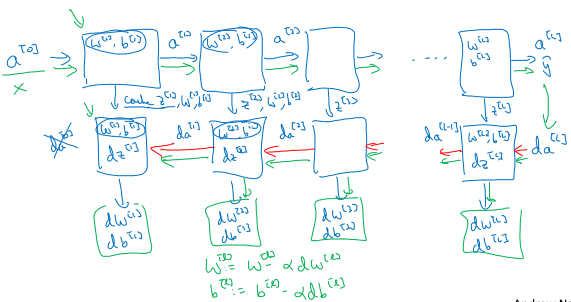
看起来很麻烦是吧?吴恩达老师说:你所实现算法的复杂性和有效性都来自于数据,而不是你写的代码...
4.7 参数 VS 超参数
我觉得这才是深度学习最重要的一部分吧...
神经网络的超参数包括:学习率、迭代次数、隐藏层的层数、隐藏层神经元数、激活函数
后面还会有:动量、mini-batch size、正则化项等等
Applied deep learning is a very empirical process.
这句话的意思就是:不要怂,就是试!找对了会所嫩模,找错了下海干活...
炼金术士的图腾!
4.8 神经网络和大脑有什么关系
没多少关系。
人类还没有搞清楚神经元的工作原理,这么叫只是为了方便宣传,忽悠你们来学习哈哈哈哈哈哈哈哈哈