5.0.偏差与方差
1)题目:
在本练习中,您将实现正则化线性回归,并使用它来研究具有不同偏差-方差属性的模型。在练习的前半部分,您将使用水库水位的变化实现正则化线性回归来预测大坝的出水量。在下半部分中,您将对调试学习算法进行诊断,并检查偏差和方差的影响。
关于数据:本次的数据是以.mat格式储存的,x表示水位的变化,y表示大坝的出水量。数据集共分为三部分:训练集(X, y)、交叉验证集(Xval, yval)和测试集(Xtest, ytest)。
数据集链接: https://pan.baidu.com/s/1cEgQIvehUcLxZ0WVhxcPuQ 提取码: xejn
2)知识点概括:
-
在新的数据集中可能之前训练的模型表现不好,误差很大,这时可以采取的方法有:
1.得到更多的训练样本——对高方差问题有效(可以通过画出学习曲线观察训练误差和验证误差之间的差距)
2.减少特征——对高方差问题有效
3.增加特征——对高偏差问题有效
4.增加多项式——对高偏差问题有效
5.增大惩罚系数——对高方差问题有效
6.减小惩罚系数——对高偏差问题有效 -
训练集、验证集、测试集(6:2:2)
训练数据集:训练模型;(习得模型的参数)
验证数据集:验证模型的效果;如果模型的效果不好,则重新调整参数再次训练新的模型,直到找到了一组参数,使得模型针对验证数据集来说已经达到最优了;(将每个训练集训练好的参数在交叉验证集上计算交叉验证误差,选择误差最小的那个假设作为我们的模型,这里是用来选择lmd)
测试数据集:将此数据集传入由验证数据集得到的最佳模型,得到模型最终的性能;(作为衡量最终模型性能的数据集) -
诊断偏差与方差(欠拟合或过拟合)
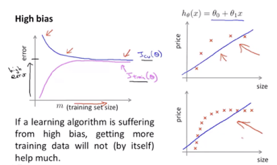
高偏差问题high bias problem(高偏差/欠拟合)对应情况:训练误差和验证误差都较大,验证误差可能约大或者约等于训练误差
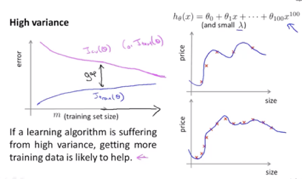
高方差问题high variance problem(高方差/过拟合)对应情况:训练误差小,但验证误差大,验证误差远大于训练误差
误差为平均误差和的一半,即 -
正则化
惩罚系数过大使得欠拟合
惩罚系数过小使得过拟合 -
学习曲线(learning curves)
在高偏差问题中,验证误差随着样本数量的增加而减小,但是减小到一定程度后基本上趋于稳定,因为此时拟合的曲线已经模拟的很好了(也可以从训练误差与验证误差很接近看出),这时的误差基本上是由于模型本身设定导致的,而不是样本数量少的关系,这时意味着增加样本数量对于优化模型没有帮助。
在高方差问题中,因为过拟合所以验证误差不会减少太多、训练误差也不会增加太多,导致训练误差和验证误差之间差距较大,但随着样本数量增加,这个差距会减少,也就是说这时增加样本数量对于改进算法是有帮助的。
-
误差分析:
建议的方法:首先尽快做出一个算法并且实现,计算出验证误差;画出学习曲线来观察如何提升这个模型;误差分析,手动观察被分类错误的样本,启发找出其他特征。
在分析评价模型时需要一个数值的评价(例如错误率、精确度等)
3)大致步骤:
-
首先读取mat数据,然后可视化训练集数据。其次写出正则化的代价函数,当惩罚系数为1、theta初值为[1, 1]时检验代价函数应该为303.993。再写出正则化的梯度函数,同样带入检查值应为[-15.30, 598.250]。然后使用牛顿共轭梯度fmin_ncg求最优解theta,再画出拟合曲线。
-
画出学习曲线,对偏差-方差问题进行诊断。样本数量从1个到12依次递增,然后对每次不同数量的样本集进行训练,产生一个模型(也就是训练好参数)再用这个样本集计算出训练误差,用交叉验证集全体计算出验证误差,画出学习曲线。
-
进行特征映射,产生 等高阶项,再进行标准化,之后再将第一列的常数项加上去(不然先加标准化之后会出现除以0的情况,产生nan)这里需要对训练集和验证集都做处理。(注意这里作业要求展开到8阶项,但是后来画图之后发现8阶的与作业中图不符,应该是6阶才对)然后开始训练模型,利用之前的函数,这里设置lmd=0,即不添加正则项。然后画出拟合的曲线以及学习曲线。(在画拟合曲线时候注意用训练集的均值和标准差进行标准化)
-
调整正则化参数。分别令lmd=1和100,查看拟合曲线以及学习曲线。之后用验证集选择lmd。(注意在计算训练误差和验证误差的时候都应该把代价函数中的lmd设置为0)即变化lmd得到模型的训练误差和验证误差,选择验证误差最小的那个模型。然后使用测试集计算选出的这个模型的测试误差。
4)关于Python:
- np.sum( , axis=0)可以列求和。
- np.c_[ ]可以合并矩阵,但注意是方括号。
- .flatten( )可以返回一个折叠成一维的数组。但是该函数只能适用于numpy对象,即array或者mat,普通的list列表是不行的。也就是说可以将shape为(12, 1)的返回为(12, )。
- np.std(x, axis=0, ddof=1) axis=0计算每一列的标准差,ddof=1表示自由度为N-1,因为无偏的样本方差为 。
5)代码与结果:
import numpy as np
import matplotlib.pyplot as plt
import scipy.optimize as opt
import scipy.io as scio
data = scio.loadmat('ex5data1.mat')
x = data['X']
y = data['y']
xval = data['Xval']
yval = data['yval']
xtest = data['Xtest']
ytest = data['ytest']
'''======================part1 正则化的线性回归========================='''
x = np.c_[np.ones(x.shape), x] #把x增加一列1
xval = np.c_[np.ones(xval.shape), xval]
theta = np.ones(2)
'''可视化训练集'''
def plot_data(x, y):
plt.scatter(x[:, 1], y, c='r', marker='x')
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.show
plot_data(x, y)
'''正则化的代价函数'''
def cost_reg(theta, x, y, lmd):
m = y.size
h = np.mat(x@theta).T
cost = np.sum(np.square(h-y))/(2*m)
reg = lmd/(2*m)*np.sum(np.square(theta[1:]))
return cost+reg
cost_reg(theta, x, y, 1) #303.9931922202643
'''正则化的梯度函数'''
def grad_reg(theta, x, y, lmd):
m = y.size
h = x@theta
p = (h-y.flatten())@x/m
p[1:] = p[1:] + lmd/m*theta[1:]
return p
grad_reg(theta, x, y, 1) #[-15.30301567, 598.25074417]
'''训练参数并可视化拟合曲线'''
theta = opt.fmin_ncg(f=cost_reg, x0=theta, fprime=grad_reg, args=(x, y, 0), maxiter=400)
def plot_fit(theta):
x = np.arange(-50, 40, step=1)
y = theta[0]+theta[1]*x
plt.plot(x, y)
plt.show
plt.figure(0)
plot_data(x, y)
plot_fit(theta)
plt.show
'''======================part2 偏差-方差========================='''
def learning_curve(x, y, xval, yval, lmd, power=1):
error_train = np.zeros(12)
error_val = np.zeros(12)
for i in range(1, 13): #(1,12)
x_ = x[0:i, :]
y_ = y[0:i]
theta = np.ones(power+1)
t = opt.fmin_ncg(f=cost_reg, x0=theta, fprime=grad_reg, args=(x_, y_, lmd), maxiter=400)
error_train[i-1] = cost_reg(t, x_, y_, 0) #lmd=0表示误差
error_val[i-1] = cost_reg(t, xval, yval, 0) #lmd=0表示误差
'''学习曲线'''
plt.figure()
m = np.array(range(1, 13))
plt.plot(m, error_train, c='b', label='Train')
plt.plot(m, error_val, c='g', label='Cross Validation')
plt.title('Learning curve for linear regression')
plt.legend(loc=1)
plt.xlim(0, 12)
plt.ylim(0)
plt.xlabel('Number of training examples')
plt.ylabel('Error')
plt.show
learning_curve(x, y, xval, yval, 0)
'''======================part3 多项式回归========================='''
'''特征映射'''
#输入m×1的矩阵,返回m×p的矩阵,第一列是x
def feature_mapping(x, p):
mapping = x
for i in range(2, p+1):
mapping = np.c_[mapping, np.power(x, i)]
return mapping
'''标准化'''
def norm(x):
sigma = np.std(x, axis=0, ddof=1) #axis=0计算每一列的标准差,ddof=1表示自由度为N-1
mu = np.mean(x, axis=0)
x = (x-mu)/sigma
return x, mu, sigma
'''数据处理与训练模型'''
power = 6
x1, mu, sigma = norm(feature_mapping(data['X'], power))
x1 = np.c_[np.ones(y.shape), x1]
xval1, mu1, sigma1 = norm(feature_mapping(data['Xval'], power))
xval1 = np.c_[np.ones(yval.shape), xval1]
xtest1, mu2, sigma2 = norm(feature_mapping(data['Xtest'], power))
xtest1 = np.c_[np.ones(ytest.shape), xtest1]
theta1 = opt.fmin_ncg(f=cost_reg, x0=np.ones(power+1), fprime=grad_reg, args=(x1, y, 1), maxiter=400)
'''画出拟合曲线'''
def plot_fit1(theta):
x = np.arange(-70, 50, step=1)
x_ = np.c_[np.ones(x.shape), (feature_mapping(x, power)-mu)/sigma] #这里的x要同样进行特征映射和标准化
y = x_@theta
plt.plot(x, y, linestyle='dashed')
plt.show
plt.figure(1)
plot_data(x, y)
plot_fit1(theta1)
plt.show
'''学习曲线'''
plt.figure(2)
learning_curve(x1, y, xval1, yval, 1, power)
plt.title('Polynomial Regression Learning Curve')
plt.show
'''用交叉验证集选择lmd'''
lmd_vec = np.array([0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10])
error_train = np.zeros(10)
error_val = np.zeros(10)
for i in range(10):
theta = opt.fmin_ncg(f=cost_reg, x0=np.ones(power+1), fprime=grad_reg, args=(x1, y, lmd_vec[i]), maxiter=400)
error_train[i] = cost_reg(theta, x1, y, 0) #lmd=0表示误差
error_val[i] = cost_reg(theta, xval1, yval, 0) #同样lmd设置为0
plt.figure(3)
plt.plot(lmd_vec, error_train, c='b', label='Train')
plt.plot(lmd_vec, error_val, c='g', label='Cross Validation')
plt.legend(loc=1)
plt.xlabel('Lambda')
plt.ylabel('Error')
plt.show
'''计算测试误差'''
t = opt.fmin_ncg(f=cost_reg, x0=np.ones(power+1), fprime=grad_reg, args=(x1, y, 1), maxiter=400)
cost_reg(t, xtest1, ytest, 0) #7.537649825997692
数据可视化以及lmd=0时拟合的线性方程

学习曲线可以看出存在高偏差问题,因为随着样本数量增加训练误差和验证误差之间的差距不大且基本上维持稳定,而且我们这里设定的模型过于简单,存在欠拟合问题。

p=6时拟合的多项式曲线,可以看出基本上所有点都在线上。

但是此时的学习曲线看出存在高方差问题,因为训练误差一直很小,而验证误差一直较高,他们之间存在差距,这时表示模型过拟合风险较大,需要后续再采取正则化等方式减小过拟合风险。

lmd=1时,曲线拟合的较好,且训练误差和验证误差都较小

lmd=100时,惩罚太大,以至于拟合的很差,而且两种误差都很大。

选取验证误差最小的那个值,可以看出当lmd=1时验证误差最小,为4.63784765。这里和作业中的结果有点差异,因为选择的是展开到6阶的多项式。

最后用lmd=1训练出的模型在测试集上计算误差,可以看出由验证集选出来的模型不一定是最适合测试集的,可能误差也比较高。因此也再次说明了把数据分为三部分的必要性。

