在用机器学习模型解决实际问题时,时刻离不开“拟合”(fitting)一词,拟合可以看做挖掘样本集与对应标签的规律。模型的预测值和样本的真实标签之间的差异称为“误差”(error),在实际问题中,我们通常在训练集上训练模型,由此产生“训练误差”(training error),然后将模型运用于测试集上,由此产生“泛化误差”(generalization error)。我们希望得到一个泛化误差小的模型,即处理新样本时尽可能预测准确。
在大多数情况下,我们能够通过各种方式得到一个经验误差很小的模型,即在训练集上达到极高的准确率。但由于训练集和测试集并不完全相同(数据可能来自不同分布,或同一分布下的采样差异),导致我们在训练集上的拟合过度,挖掘出的规律只适用于训练集而不适用于所有样本,把训练样本的一些特点当成了所有样本都具有的一般性质。这种现象称为“过拟合”(overfitting)。与之相对的是“欠拟合”(underfitting),即对训练样本的性质挖掘不够。
用多项式函数来模拟
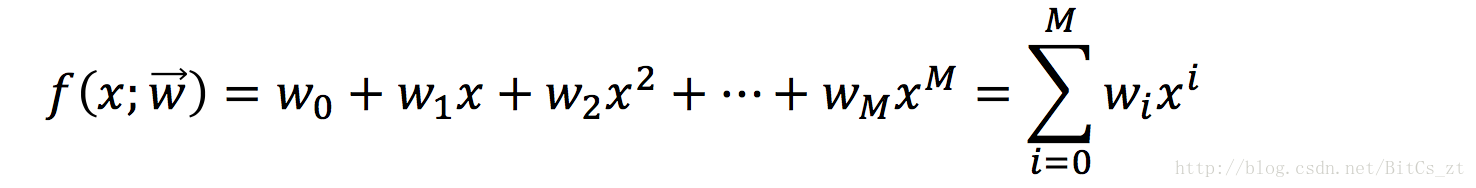
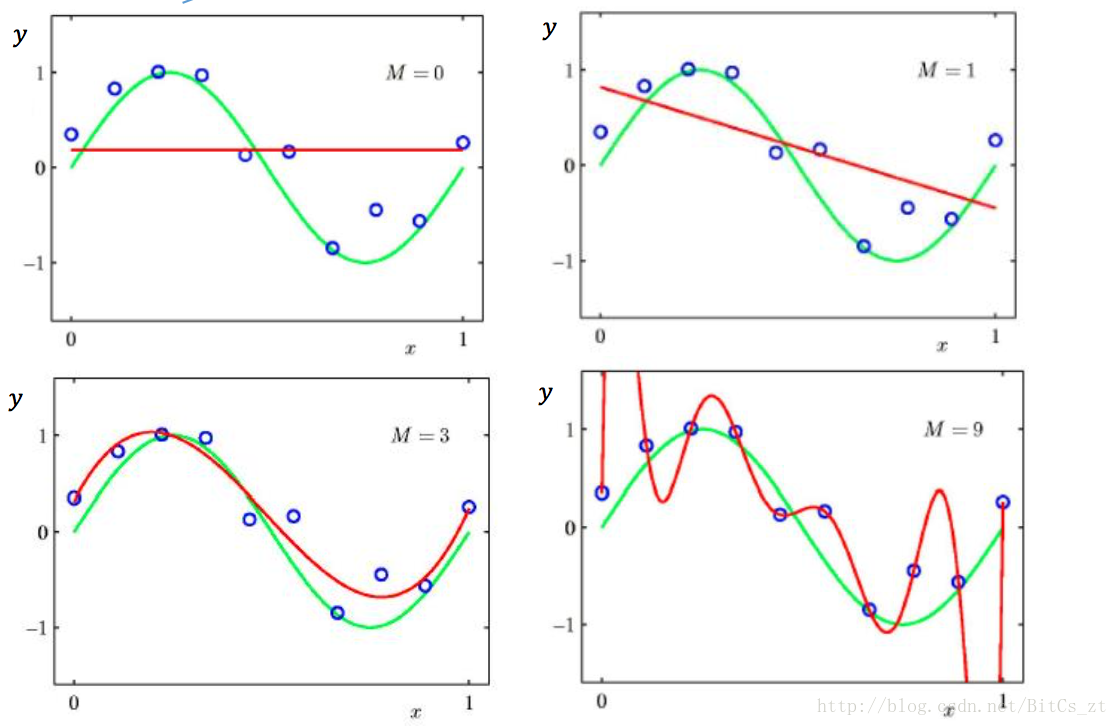
可以看到,在过拟合情况下,模型参数值巨大。若此时样本属性值稍有变化,乘以巨大的参数,便会使模型预测结果有巨大的浮动,导致泛化误差变大。

有多种因素可能导致过拟合,最常见的原因是由于模型学习能力过于强大,如神经网络理论上可以逼近任何函数,自然也就能拟合所有训练数据。而欠拟合通常是由于模型学习能力弱,实际中比较容易解决,如加强模型表示能力或者更换更强有力的模型。解决过拟合问题是机器学习面临的关键障碍,好比在崎岖的山路上赛车,如果速度慢(欠拟合)只需要加速即可,而速度过快(过拟合)只会车毁人亡,找到合适的车速,既能不冲出赛道又能快速到达终点是很困难的。
想要得到泛化误差小的模型,无外乎两点。首先需要一个能很好拟合训练数据的模型(避免欠拟合),然后该模型必须能适用于测试集(不要太复杂的模型)。因此,在训练过程中,我们不仅要减小训练误差,还要同时控制模型复杂度,即我们训练时最小化的目标是:

前一项即训练误差,通常也称为“经验风险”(empirical risk)。后一项为正则化项(regularization),也称为“结构风险”(structure risk),
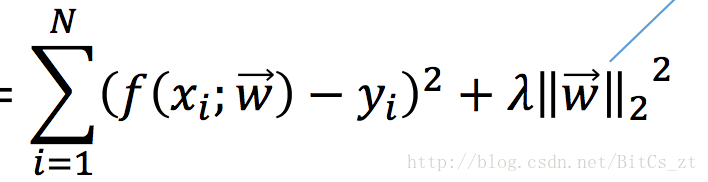
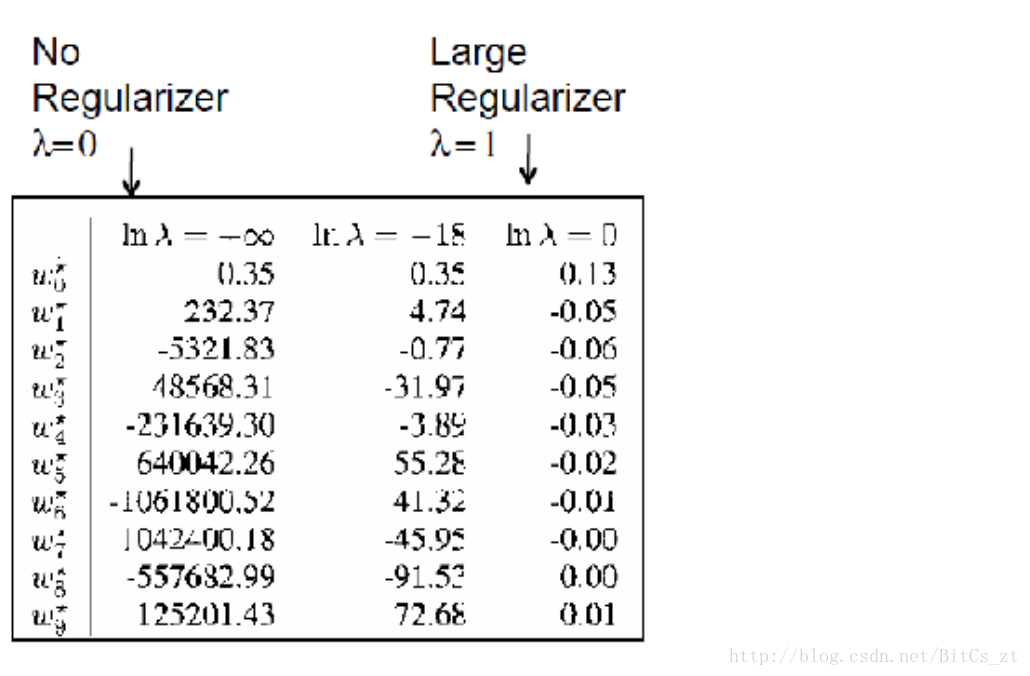
本例中正则化项为L2范数,在加入了对模型的限制条件后再进行训练,可以看到参数数值都被限制得比较小,此时若样本属性值发生变化,乘以小的参数,也不会使预测结果有太大波动,使泛化误差变小。
值得一提的是,除了控制模型复杂度从而解决过拟合问题,我们还可以增加训练数据量。当训练数据增多时,训练数据分布也就越接近真实数据分布,挖掘出的规律越可能适用于全部数据,数据越多,强模型越能发挥威力。
上面我们只是从直观的角度理解了拟合问题、训练误差和泛化误差,下面利用偏差-方差分解对上述问题进行理论分析。
令
-
x 为测试样本 -
yD 为x 在数据集(非训练集)中的标签 -
y 为x 的真实标记 -
f(x;D) 为训练集D 上学得的模型f 在x 上的预测输出
则模型的期望预测为:
使用样本数相同的不同训练集产生的方差(varience)为:
噪声为:
期望输出与真实标记的差别称为偏差(bias),为:
假定噪声期望为0,即:
则算法的期望泛化误差可分解为:
即泛化误差可分解为偏差、方差和噪声之和。其中
可以看到,给定特定的模型(算法)和具体的问题,期望泛化误差是一定的,降低bias将增加varience,反之亦然。偏差-方差的控制存在一个trade-off,强有力的模型能降低bias,但可能会使varience增加,泛化性能差,对应的是过拟合的情况。而简单的模型(加正则项的强模型)可能在训练误差大,bias高,但可能泛化性能强,varience相对较低,对应的则是欠拟合的情况。如下图所示:
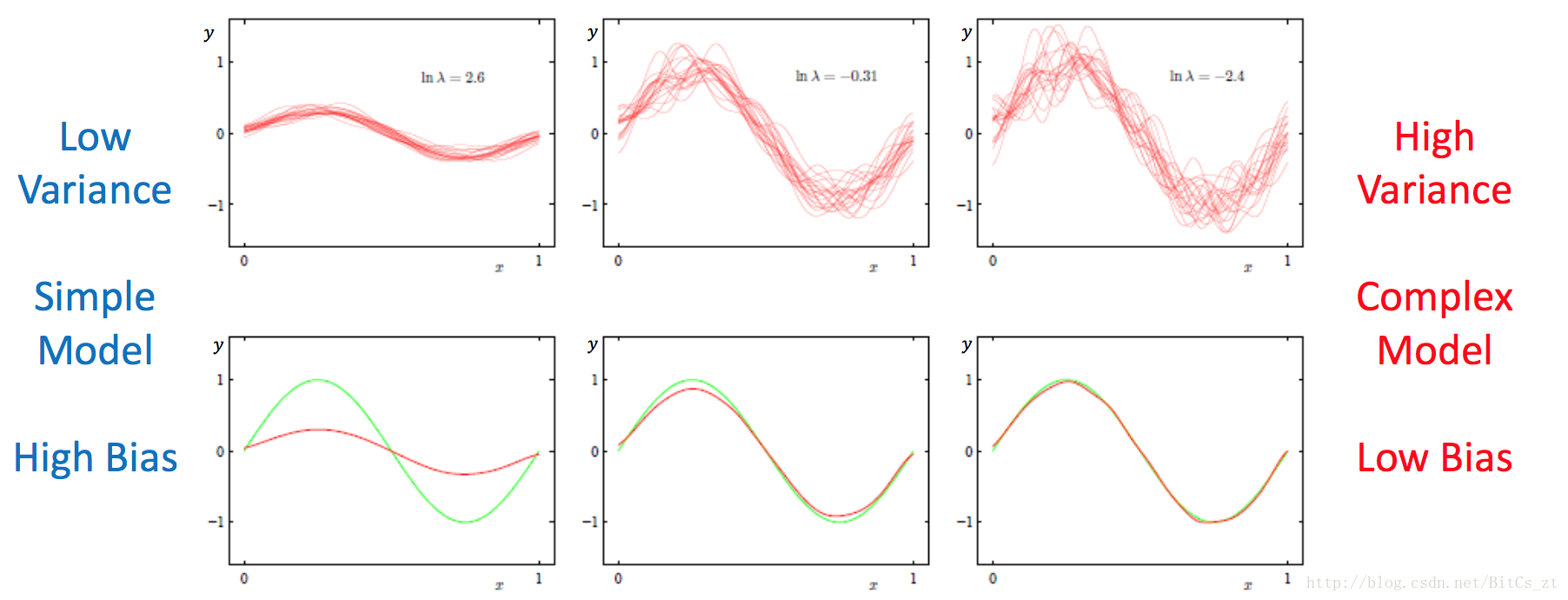
实际上,我们只能通过不断的实验调节参数,最终找到较好的折中方案。这不仅需要我们对模型有深刻的认识,知道如何去限制或释放模型的能力,更需要我们对数据有深刻的认识,选择出适用于特定问题的模型来解决问题。