欠拟合 under fitting
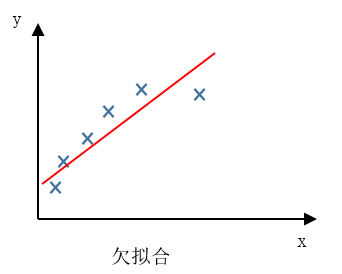
欠拟合(under fitting),这个问题的另一个术语叫做 高偏差(High bias)。这两种说法大致相似,意思是它没有很好地拟合训练数据。
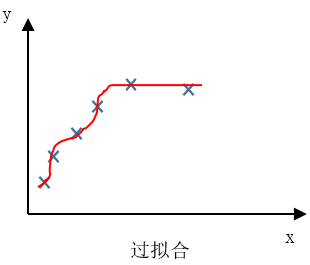
过拟合 over fitting
-
过度拟合(over fitting),另一个描述该问题的术语是 高方差(High variance)。
-
过拟合的问题经常会在模型过度复杂或训练数据较少时发生,导致模型无法泛化到新的数据样本中。
-
泛化 (generalize) 指的是一个假设模型能够应用到新样本的能力。
-
正则化技术是保证算法泛化能力的有效工具,参见: 正则化方法:数据增强、regularization、dropout
偏差与方差
学习算法的预测误差,或者说泛化误差 (generalization error) 可以分解为三个部分: 偏差(bias)、方差(variance) 和噪声(noise)。在估计学习算法性能的过程中, 我们主要关注偏差与方差。因为噪声属于不可约减的误差 (irreducible error)。
-
偏差(bias):这里的偏指的是偏离,描述的是预测值与标准值之间的差距。偏差越大,越偏离真实数据。 “标准” 也就是真实情况 (ground truth),在分类任务中, 这个 “标准” 就是真实标签 (label).
-
方差(variance):描述的是预测值的变化范围,离散程度,也就是预测值在标准值附近的波动程度。方差越大,数据的分布越分散。
-
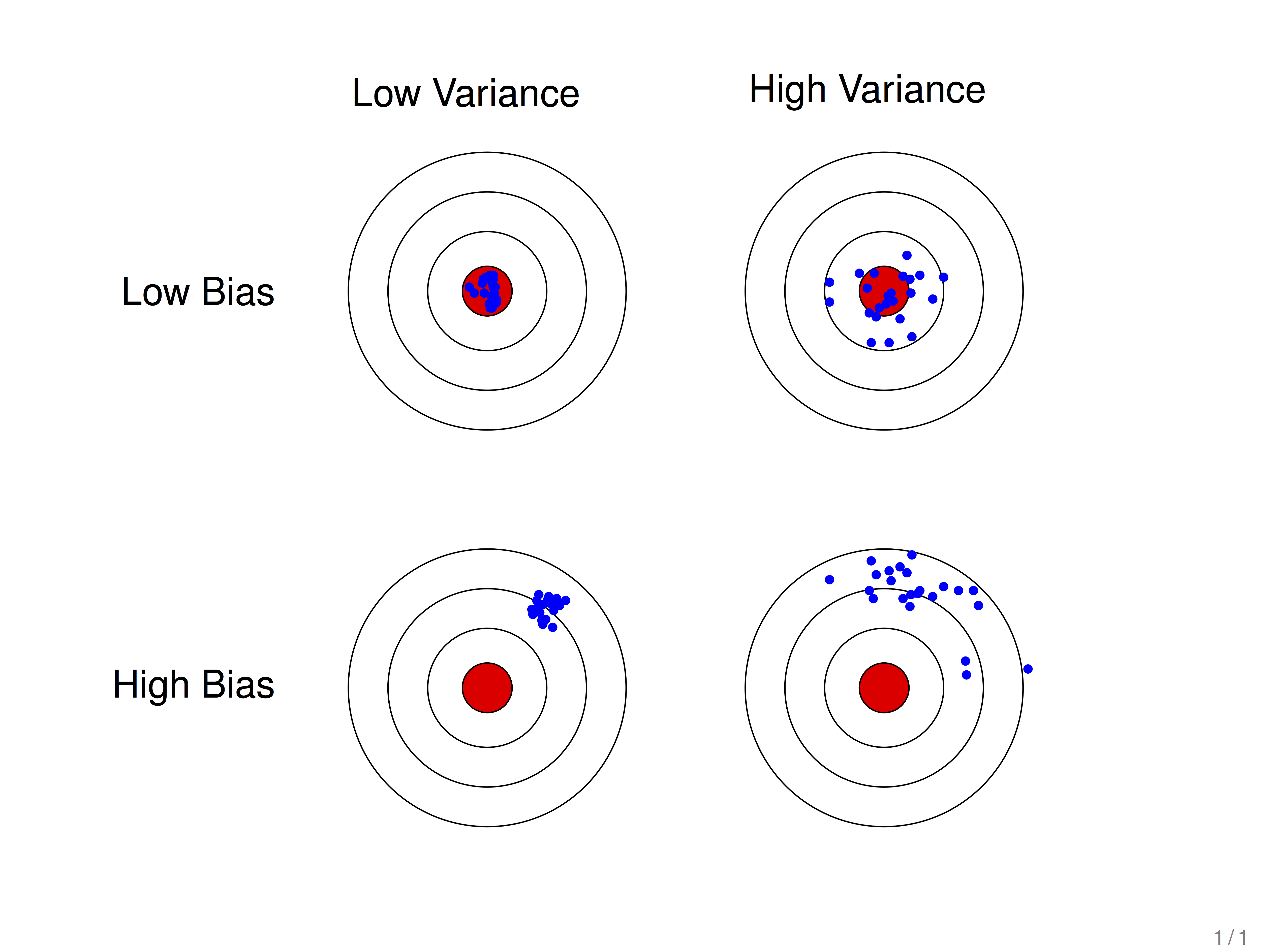
假设红色的靶心区域是学习算法的正确预测值,蓝色点为训练过程中模型对样本的预测值,蓝色点距离靶心越远,预测效果越差。
-
蓝色点比较集中时,方差比较小,比较分散时,方差比较大。
-
蓝色点比较靠近红色靶心时,偏差较小;远离靶心时,偏差较大。
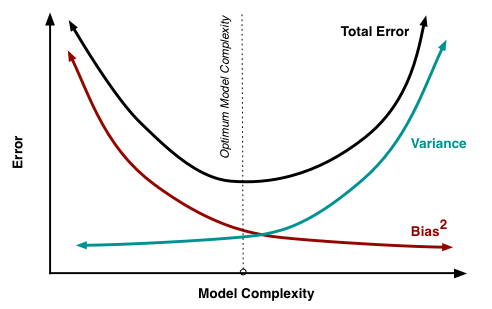
偏差-方差窘境 bias-variance dilemma
-
给定一个学习任务,在训练初期由于训练不足,学习器的拟合能力不够强,偏差比较大,也是由于拟合能力不强,数据集的扰动也无法使学习器产生显著变化,也就是欠拟合的情况。
-
随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据的扰动也能够渐渐被学习器学到。
-
充分训练后,学习器的拟合能力已非常强,训练数据的轻微扰动都会导致学习器发生显著变化,当训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合。