一、GloVe模型的理解
1) 原理
功能:基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型对词汇进行向量化表示
输入:语料库 输出:词向量
2)与Skip-Gram、CBOW模型比较
例如:句子为"dog barked at the mailman" ,目标单词为'at'
Skip-gram模型:Skip-gram模型只关注单个输入/输出元组中的目标词和上下文中的单个单词,输入为["dog", "at"]
CBOW模型:关注目标单词和单个样本中上下文的所有单词,则输入为[["dog","barked","the","mailman"],"at"]
因此,在给定数据集中,对于指定单词的上下文而言,CBOW比Skip-gram会获取更多的信息。Global Vector融合了矩阵分解的全局统计信息和上下文信息。
3)步骤
1.构建共现矩阵
例如句子为:i love you but you love him i am sad
包括7个单词:i、love、you、but、him、am、sad
设context = 5,则目标单词的左右长度都为2,以下为统计窗口:
注:中心词为目标单词,窗口内容为目标单词的左右各两个单词。
扫描二维码关注公众号,回复:
4013142 查看本文章

如:"i"左边无单词,右边有两个单词"love","you",所以窗口内容为["i","love","you"]

设:语料句子长度为n,共现矩阵为 ,n*n维的矩阵,矩阵元素为
表示在整个语料库中,单词
和单词
出现在同一个窗口中的次数。
如中心词为“you”(下标为2),context单词为“i、love、but、you”
(下标分别为0,1,3,4),则执行:
再重复以上步骤,将整个语料库遍历一遍。
2.使用GloVe模型训练词向量
代价函数为
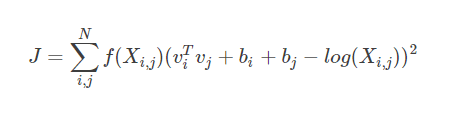
下一篇文章为Glove工具的具体实现。