目录
1. 预处理数据
- 创建train_data_new2文件夹.
- 参考这博客,生成两个文件wordslist.npy,wordVector.npy,并且放入GloVe文件夹中。
- 下载IMDB数据, 可参考这个博客,并且修改下面代码中相关目录。
import numpy as np
import os as os
import tensorflow.keras as keras
import time
import re
from sklearn.model_selection import train_test_split
vocab_size = 400000
save_dir = './train_data_new2'
# remove html tag like '<br /><br />'
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub(' ', text)
def clean_str(string):
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string) # it's -> it 's
string = re.sub(r"\'ve", " \'ve", string) # I've -> I 've
string = re.sub(r"n\'t", " n\'t", string) # doesn't -> does n't
string = re.sub(r"\'re", " \'re", string) # you're -> you are
string = re.sub(r"\'d", " \'d", string) # you'd -> you 'd
string = re.sub(r"\'ll", " \'ll", string) # you'll -> you 'll
string = re.sub(r"\'m", " \'m", string) # I'm -> I 'm
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
def process(text):
text = clean_str(text)
text = rm_tags(text)
#text = text.lower()
return text
maxlen = 200
wordVectors = np.load('./GloVe/wordVectors.npy')
wordsList = np.load('./GloVe/wordsList.npy')
wordsList = [word.decode('UTF-8') for word in wordsList]
def get_data(datapath =r'D:\train_data\aclImdb\aclImdb\train' ):
pos_files = os.listdir(datapath + '/pos')
neg_files = os.listdir(datapath + '/neg')
print(len(pos_files))
print(len(neg_files))
pos_all = []
neg_all = []
for pf, nf in zip(pos_files, neg_files):
with open(datapath + '/pos' + '/' + pf, encoding='utf-8') as f:
s = f.read()
s = process(s)
words = s.split()
size = min([200, len(words)])
word2Vectors = np.zeros((maxlen), dtype=np.int)
for i in range(0, size):
try:
word2Vectors[i] = wordsList.index(words[i])
except Exception as e :
# print(e)
pass
# print("Word: [", words[i], "] not in wvmodel! Use random embedding instead.")
pos_all.append(word2Vectors)
with open(datapath + '/neg' + '/' + nf, encoding='utf-8') as f:
s = f.read()
s = process(s)
words = s.split()
size = min([200, len(words)])
word2Vectors = np.zeros((maxlen), dtype=np.int)
for i in range(0, size):
try:
word2Vectors[i] = wordsList.index(words[i])
except Exception as e :
# print(e)
pass
# print("Word: [", words[i], "] not in wvmodel! Use random embedding instead.")
neg_all.append(word2Vectors)
print(len(pos_all))
print(pos_all[0])
print(len(neg_all))
X_orig= np.array(pos_all + neg_all)
# print(X_orig)
Y_orig = np.array([1 for _ in range(len(pos_all))] + [0 for _ in range(len(neg_all))])
print("X_orig:", X_orig.shape)
print("Y_orig:", Y_orig.shape)
return X_orig, Y_orig
def generate_train_data():
X_orig, Y_orig = get_data(r'D:\train_data\aclImdb\aclImdb\train')
X_orig_test, Y_orig_test = get_data(r'D:\train_data\aclImdb\aclImdb\test')
X_orig = np.concatenate([X_orig, X_orig_test])
Y_orig = np.concatenate([Y_orig ,Y_orig_test])
print("X_orig:", X_orig.shape)
print("Y_orig:", Y_orig.shape)
np.savez(save_dir+'/trainData', x=X_orig, y=Y_orig)
def generate_embedding_matrix():
embedding_matrix = np.random.uniform(size=(vocab_size, 50)) # +1是要留一个给index=0
print("Transfering to the embedding matrix......")
for index in range(0, vocab_size):
word_vector = wordVectors[index]
embedding_matrix[index] = word_vector
print("Finished!")
print("Embedding matrix shape:\n", embedding_matrix.shape)
np.save(save_dir+'/embedding_matrix', embedding_matrix)
def generate_test_train():
trainDataNew = np.load('./train_data_new1/trainData.npz')
X = trainDataNew['x']
Y = trainDataNew['y']
word_index = X[0]
for i in range(0, len(word_index)):
vector = wordVectors[word_index[i]]
print(vector)
np.random.seed = 1
random_indexs = np.random.permutation(len(X))
X = X[random_indexs]
Y = Y[random_indexs]
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)
np.savez(save_dir + '/train', x=X_train, y=y_train)
np.savez(save_dir + '/test', x=X_test, y=y_test)
if __name__ == '__main__':
# get_data(r'D:\train_data\aclImdb\aclImdb_test\test')
generate_train_data()
generate_embedding_matrix()
generate_test_train()
2. 训练模型
- 创建文件夹lstm11
- 执行下面代码
import os
import numpy as np
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import tensorflow as tf
import time
import re
root_folder = '.\lstm11'
def get_dataset():
train_set = np.load('./train_data_new2/train.npz')
X_train = train_set['x']
y_train = train_set['y']
test_set = np.load('./train_data_new2/test.npz')
X_test = test_set['x']
y_test = test_set['y']
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)
return X_train, y_train, X_test, y_test
def lstm_model(use_pretrained_wv =True):
if use_pretrained_wv:
embedding_matrix = np.load('./train_data_new2/embedding_matrix.npy')
model = keras.Sequential([
# layers.Embedding(input_dim=400000, output_dim=50, input_length=200 , weights=[embedding_matrix], trainable=False),
layers.Embedding(input_dim=400000, output_dim=50, input_length=200, weights=[embedding_matrix]),
layers.Bidirectional(tf.keras.layers.LSTM(128,dropout=0.5)),
layers.Dense(2, activation='softmax')
])
else:
model = keras.Sequential([
layers.Embedding(input_dim=400000, output_dim=50, input_length=200),
#layers.BatchNormalization(),
layers.LSTM(100),
layers.Dropout(0.5),
#layers.BatchNormalization(),
layers.Dense(2, activation='softmax')
])
#model.compile(optimizer=keras.optimizers.Adam(), loss=keras.losses.BinaryCrossentropy(), metrics=['accuracy'])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
#metrics=['accuracy'])
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.summary()
return model
current_max_loss =9999
def train_my_model(model, X_train, y_train):
weight_dir = root_folder+'\model.h5'
if os.path.isfile(weight_dir):
print('load weight')
model.load_weights(weight_dir)
def save_weight(epoch, logs):
global current_max_loss
if(logs['val_loss'] is not None and logs['val_loss']< current_max_loss):
current_max_loss = logs['val_loss']
print('save_weight', epoch, current_max_loss)
model.save_weights(weight_dir)
batch_print_callback = keras.callbacks.LambdaCallback(
on_epoch_end=save_weight
)
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=4, monitor='loss'),
batch_print_callback,
tf.keras.callbacks.TensorBoard(log_dir=root_folder+'\logs')
]
begin = time.time()
history = model.fit(X_train, y_train, batch_size=128, epochs=25,validation_split=0.1, callbacks= callbacks)
finish = time.time()
print("train time: ", (finish - begin), 's')
import matplotlib.pyplot as plt
plt.plot(history.history['sparse_categorical_accuracy'])
plt.plot(history.history['val_sparse_categorical_accuracy'])
plt.legend(['sparse_categorical_accuracy', 'val_sparse_categorical_accuracy'], loc='upper left')
plt.show()
def test_my_module(model, X_test, y_test):
if os.path.isfile(root_folder+'\model.h5'):
print('load weight')
model.load_weights(root_folder+'\model.h5')
test_result = model.evaluate(X_test, y_test)
print('test Result', test_result)
print('Test ',test_result)
def load_my_model(model):
if os.path.isfile(root_folder + '\model.h5'):
print('load weight')
model.load_weights(root_folder + '\model.h5')
return model
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub(' ', text)
def clean_str(string):
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string) # it's -> it 's
string = re.sub(r"\'ve", " \'ve", string) # I've -> I 've
string = re.sub(r"n\'t", " n\'t", string) # doesn't -> does n't
string = re.sub(r"\'re", " \'re", string) # you're -> you are
string = re.sub(r"\'d", " \'d", string) # you'd -> you 'd
string = re.sub(r"\'ll", " \'ll", string) # you'll -> you 'll
string = re.sub(r"\'m", " \'m", string) # I'm -> I 'm
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
def process(text):
text = clean_str(text)
text = rm_tags(text)
#text = text.lower()
return text
def predict_my_module(model):
# small_word_index = np.load('./train_data_new2/small_word_index.npy', allow_pickle=True)
wordsList = np.load('./GloVe/wordsList.npy')
wordsList = [word.decode('UTF-8') for word in wordsList]
review_index = np.zeros((1, 200), dtype=int)
# review = "Story of a man who has unnatural feelings for a pig. Starts out with a opening scene that is a terrific example of absurd comedy. A formal orchestra audience is turned into an insane, violent mob by the crazy chantings of it's singers. Unfortunately it stays absurd the WHOLE time with no general narrative eventually making it just too off putting. Even those from the era should be turned off. The cryptic dialogue would make Shakespeare seem easy to a third grader. On a technical level it's better than you might think with some good cinematography by future great Vilmos Zsigmond. Future stars Sally Kirkland and Frederic Forrest can be seen briefly.";
# review = "This movie is terrible, I don't like it."
# review = "I like this movie very much"
# review = "this is bad movie "
# review = "This is good movie"
# review = "This is a amazing movie, I like it very much."
# review = "I think this is bad movie"
# review = "I am very disappointed with this movie"
review = "I am very happy to watch this movie, it is amazing."
#neg:0 postive:1
review = process(review)
counter = 0
for word in review.split():
try:
print(word, wordsList.index(word))
review_index[0][counter] = wordsList.index(word)
counter = counter + 1
except Exception:
print('Word error', word)
print(review_index.shape)
s = model.predict(x=review_index)
print(s)
if __name__ == '__main__':
X_train, y_train, x_test, y_test = get_dataset()
model = lstm_model()
train_my_model(model, X_train, y_train)
# test_my_module(model,x_test, y_test)
# load_my_model(model)
# predict_my_module(model)
247/247 [==============================] - 158s 640ms/step - loss: 0.0495 - sparse_categorical_accuracy: 0.9815 - val_loss: 0.4767 - val_sparse_categorical_accuracy: 0.8963
Epoch 24/25
247/247 [==============================] - 157s 635ms/step - loss: 0.0414 - sparse_categorical_accuracy: 0.9857 - val_loss: 0.4965 - val_sparse_categorical_accuracy: 0.8954
Epoch 25/25
247/247 [==============================] - 157s 637ms/step - loss: 0.0426 - sparse_categorical_accuracy: 0.9839 - val_loss: 0.5218 - val_sparse_categorical_accuracy: 0.8946
train time: 3892.924721479416 s
3. 测试模型
if __name__ == '__main__':
X_train, y_train, x_test, y_test = get_dataset()
model = lstm_model()
# train_my_model(model, X_train, y_train)
load_my_model(model)
test_my_module(model,x_test, y_test)
# predict_my_module(model)执行的结果。测试集上准确率是88%
扫描二维码关注公众号,回复:
15456612 查看本文章

load weight
469/469 [==============================] - 18s 37ms/step - loss: 0.3095 - sparse_categorical_accuracy: 0.8838
test Result [0.3094595968723297, 0.8838000297546387]
Test [0.3094595968723297, 0.8838000297546387]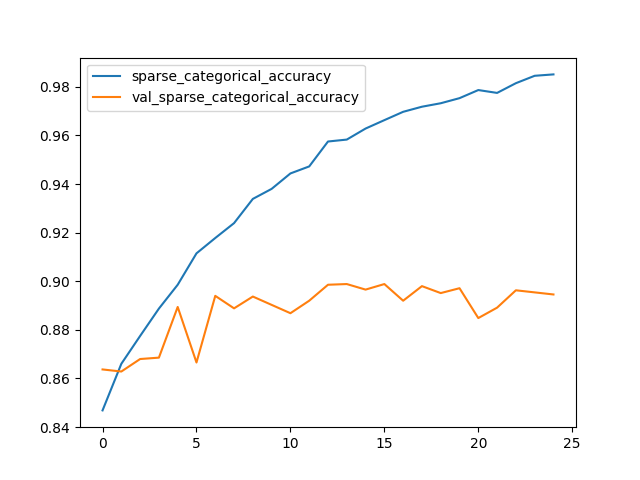
4. 预测模型
def predict_my_module(model):
# small_word_index = np.load('./train_data_new2/small_word_index.npy', allow_pickle=True)
wordsList = np.load('./GloVe/wordsList.npy')
wordsList = [word.decode('UTF-8') for word in wordsList]
review_index = np.zeros((1, 200), dtype=int)
# review = "Story of a man who has unnatural feelings for a pig. Starts out with a opening scene that is a terrific example of absurd comedy. A formal orchestra audience is turned into an insane, violent mob by the crazy chantings of it's singers. Unfortunately it stays absurd the WHOLE time with no general narrative eventually making it just too off putting. Even those from the era should be turned off. The cryptic dialogue would make Shakespeare seem easy to a third grader. On a technical level it's better than you might think with some good cinematography by future great Vilmos Zsigmond. Future stars Sally Kirkland and Frederic Forrest can be seen briefly.";
# review = "This movie is terrible, I don't like it."
# review = "I like this movie very much"
# review = "this is bad movie "
# review = "This is good movie"
# review = "This is a amazing movie, I like it very much."
# review = "I think this is bad movie"
# review = "I am very disappointed with this movie"
review = "I am very happy to watch this movie, it is amazing."
#neg:0 postive:1
review = process(review)
counter = 0
for word in review.split():
try:
print(word, wordsList.index(word))
review_index[0][counter] = wordsList.index(word)
counter = counter + 1
except Exception:
print('Word error', word)
print(review_index.shape)
s = model.predict(x=review_index)
print(s)
if __name__ == '__main__':
# X_train, y_train, x_test, y_test = get_dataset()
model = lstm_model()
# train_my_model(model, X_train, y_train)
# test_my_module(model,x_test, y_test)
load_my_model(model)
predict_my_module(model)预测的结果是[[0.1285436 0.8714564]]。消极影评概率0.1285436, 积极的影评概率是0.8714564。
2023-05-05 19:32:36.458301: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 200, 50) 20000000
_________________________________________________________________
bidirectional (Bidirectional (None, 256) 183296
_________________________________________________________________
dense (Dense) (None, 2) 514
=================================================================
Total params: 20,183,810
Trainable params: 20,183,810
Non-trainable params: 0
_________________________________________________________________
load weight
i 41
am 913
very 191
happy 1751
to 4
watch 1716
this 37
movie 1005
, 1
it 20
is 14
amazing 5772
(1, 200)
2023-05-05 19:32:37.010888: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
[[0.1285436 0.8714564]]
Process finished with exit code 0
其它的模型
可以参考,
def build_model(top_words=top_words,max_words=max_words,num_labels=num_labels,mode='LSTM',hidden_dim=[32]):
if mode=='RNN':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(SimpleRNN(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='MLP':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='LSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(LSTM(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='GRU':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(GRU(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN': #一维卷积
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(64))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='BiLSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation='softmax'))
#下面的网络采用Funcional API实现
elif mode=='TextCNN':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
## 词嵌入使用预训练的词向量
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Conv1D(32, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPooling1D(pool_size=2)(cnn1)
cnn2 = Conv1D(32, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPooling1D(pool_size=2)(cnn2)
cnn3 = Conv1D(32, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPooling1D(pool_size=2)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(num_labels, activation='softmax')(drop)
model = Model(inputs=inputs, outputs=main_output)
elif mode=='Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(64)(attention_mul) #原始的全连接
fla=Flatten()(mlp)
output = Dense(num_labels, activation='softmax')(fla)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Attention*3':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(32,activation='relu')(attention_mul)
attention_probs = Dense(32, activation='softmax', name='attention_vec1')(mlp)
attention_mul = Multiply()([mlp, attention_probs])
mlp2 = Dense(32,activation='relu')(attention_mul)
attention_probs = Dense(32, activation='softmax', name='attention_vec2')(mlp2)
attention_mul = Multiply()([mlp2, attention_probs])
mlp3 = Dense(32,activation='relu')(attention_mul)
fla=Flatten()(mlp3)
output = Dense(num_labels, activation='softmax')(fla)
model = Model(inputs=[inputs], outputs=output)
elif mode=='BiLSTM+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
bilstm = Bidirectional(LSTM(64, return_sequences=True))(layer) #参数保持维度3
bilstm = Bidirectional(LSTM(64, return_sequences=True))(bilstm)
layer = Dense(256, activation='relu')(bilstm)
layer = Dropout(0.2)(layer)
## 注意力机制
attention = Attention(step_dim=max_words)(layer)
layer = Dense(128, activation='relu')(attention)
output = Dense(num_labels, activation='softmax')(layer)
model = Model(inputs=inputs, outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(64,activation='relu')(attention_mul) #原始的全连接
#bat=BatchNormalization()(mlp)
#act=Activation('relu')
gru=Bidirectional(GRU(32))(mlp)
mlp = Dense(16,activation='relu')(gru)
output = Dense(num_labels, activation='softmax')(mlp)
model = Model(inputs=[inputs], outputs=output)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model