【视频分割】【深度学习】MiVOS官方Pytorch代码–Propagation模块解析
MiVOS模型将交互到掩码和掩码传播分离,从而实现更高的泛化性和更好的性能。单独训练的交互模块将用户交互转换为对象掩码,传播模块使用一种新的top-k过滤策略在读取时空存储器时进行临时传播,本博客将讲解Propagation(用户交互产生分割图)。

【解析代码地址】
文章目录
前言
在详细解析MiVOS代码之前,首要任务是成功运行MiVOS代码【win10下参考教程】,后续学习才有意义。
本博客讲解Propagation(掩码传播)的功能模块,之前的博文已经讲解了S2M(用户交互产生分割图)的功能模块,因此interactive_gui.py文件只详细讲解与Propagation功能相关的代码。
【代码:用interactive_gui_4.1.py代替interactive_gui.py】

用户界面新增Propagation模块
主函数新增代码
在主函数中,实例化Propagation对象和Fusion对象并加载权重。
prop_saved = torch.load(args.prop_model)
prop_model = PropagationNetwork().cuda().eval()
prop_model.load_state_dict(prop_saved)
fusion_saved = torch.load(args.fusion_model)
fusion_model = FusionNet().cuda().eval()
fusion_model.load_state_dict(fusion_saved)
InferenceCore封装了prop_net模型和fuse_net模型为一个推理器,对应掩码传播和融合过程。
self.processor = InferenceCore(prop_net, fuse_net, images_to_torch(images, device='cpu'),
num_objects, mem_freq=mem_freq, mem_profile=mem_profile)
__init__函数新增代码
新增Propagate按钮和Propagate进度条
self.run_button = QPushButton('Propagate')
self.run_button.clicked.connect(self.on_run)
# 功能:显示progress进度
self.progress = QProgressBar(self)
self.progress.setGeometry(0, 0, 300, 25)
self.progress.setMinimumWidth(300)
self.progress.setMinimum(0)
self.progress.setMaximum(100)
self.progress.setFormat('Idle')
self.progress.setStyleSheet("QProgressBar{color: black;}")
self.progress.setAlignment(Qt.AlignCenter)
on_run函数
获取关键图片mask后,通过interact完成掩膜传播得到所有图片的mask。
def on_run(self):
if self.interacted_mask is None:
return
# 掩码传播
self.current_mask = self.processor.interact(self.interacted_mask, self.cursur,
self.progress_total_cb, self.progress_step_cb)
self.interacted_mask = None
# clear scribble and reset
self.show_current_frame()
# 清除当前图像所有交互对象的交互记录
self.reset_this_interaction()
self.progress.setFormat('Idle')
self.progress.setValue(0)

progress_total_cb/progress_step_cb函数
直观的显示当前传播的进度。
def progress_step_cb(self):
self.progress_num += 1
ratio = self.progress_num/self.progress_max
self.progress.setValue(int(ratio*100))
self.progress.setFormat('%2.1f%%' % (ratio*100))
QApplication.processEvents()
def progress_total_cb(self, total):
self.progress_max = total
self.progress_num = -1
self.progress_step_cb()

InferenceCore类关键代码讲解
在inference_core.py文件中。
__init__函数
InferenceCore类封装了prop_net模型和fuse_net模型,对输入模型的图片做了简单的预处理,设置了程序运行时GPU资源的使用权限等等。
def __init__(self, prop_net : PropagationNetwork, fuse_net : FusionNet, images, num_objects,
mem_profile=0, mem_freq=5, device='cuda:0'):
self.prop_net = prop_net.to(device, non_blocking=True) # 掩码传播
if fuse_net is not None:
self.fuse_net = fuse_net.to(device, non_blocking=True) # 掩码融合
self.mem_profile = mem_profile # 使用GPU资源的权限,0~3级 数字越高权限越低
self.mem_freq = mem_freq # 使用内存资源的时间,数字越高内存使用越少
self.device = device
# 使用GPU资源的不同权限
if mem_profile == 0:
self.data_dev = device
self.result_dev = device
self.q_buf_size = 105
self.i_buf_size = -1 # 无需缓冲的图像(-1表示都加载)
elif mem_profile == 1:
self.data_dev = 'cpu'
self.result_dev = device
self.q_buf_size = 105
self.i_buf_size = 105 # 无需缓冲的图像 105张
elif mem_profile == 2:
self.data_dev = 'cpu'
self.result_dev = 'cpu'
self.q_buf_size = 3
self.i_buf_size = 3
else:
self.data_dev = 'cpu'
self.result_dev = 'cpu'
self.q_buf_size = 1
self.i_buf_size = 1
# 图片数量
t = images.shape[1]
h, w = images.shape[-2:]
# 目标数
self.k = num_objects
# 用补padding的方式将输入的图片高宽变为16的整数倍
self.images, self.pad = pad_divide_by(images, 16, images.shape[-2:])
# 补过padding后新图片的高宽
nh, nw = self.images.shape[-2:]
# 图片是否加载到GPU
self.images = self.images.to(self.data_dev, non_blocking=False)
# 这两者以不同的格式存储相同的信息
# masks是为了输入到模型中,np_masks是为了在主界面展示
self.masks = torch.zeros((t, 1, nh, nw), dtype=torch.uint8, device=self.result_dev)
self.np_masks = np.zeros((t, h, w), dtype=np.uint8)
# prob表示包括背景在内目标的概率
self.prob = torch.zeros((self.k+1, t, 1, nh, nw), dtype=torch.float32, device=self.result_dev) # k+1:object_num t:batch
# 防止背景概率为0
self.prob[0] = 1e-7
# 记录图片batchsize 原始高宽
self.t, self.h, self.w = t, h, w
# 记录padding处理后的高宽
self.nh, self.nw = nh, nw
# padding处理后图像的比
self.kh = self.nh//16
self.kw = self.nw//16
# 查询缓冲区
self.query_buf = {
}
# 图片缓冲区
self.image_buf = {
}
# 存储有过交互的图片序号
self.interacted = set()
# 存储key/value
self.certain_mem_k = None
self.certain_mem_v = None
关于Propagation模块中深度学习网络会单出一期详细讲解,现在暂不展开讲解,避免内容过于杂乱,只需要读者知道流程。
interact函数
以用户当前帧作为起点,对mask进行双向传播,通过用户标注,获取某些帧的mask,再通过双向传播获得所有帧的mask。
过去带有对象掩码的帧视为内存帧self.image_buf(get_image_buffered),计算memory的key和value存入self.certain_mem_k和self.certain_mem_v中,用于预测查询帧的对象掩码。通过do_pass完成包括传播和融合的完整过程。
def interact(self, mask, idx, total_cb=None, step_cb=None):
"""
Interact -> Propagate -> Fuse
mask - One-hot mask of the interacted frame, background included
idx - Frame index of the interacted frame
total_cb, step_cb - Callback functions for the GUI
Return: all mask results in np format for DAVIS evaluation
"""
# 记录有过交互的图片序号
self.interacted.add(idx)
mask = mask.to(self.device)
# 用补padding的方式将输入的mask高宽变为16的整数倍
mask, _ = pad_divide_by(mask, 16, mask.shape[-2:])
self.mask_diff = mask - self.prob[:, idx].to(self.device)
# idx正差异
self.pos_mask_diff = self.mask_diff.clamp(0, 1)
# idx负差异
self.neg_mask_diff = (-self.mask_diff).clamp(0, 1)
# 对于图片idx,直接用mask更新self.prob
self.prob[:, idx] = mask
# mask是包括背景的各目标可能的概率-->mask[1:]除去背景
# 获得图像idx的存储key/value
key_k, key_v = self.prop_net.memorize(self.get_image_buffered(idx), mask[1:])
# key_k 用于评估当前帧和之前帧的相似性 [num_objects, 512, 1, H/16, W/16]
# key_v 用来生成最后mask精细结果信息 [num_objects, 512, 1, H/16, W/16]
# 记录所有有过交互的图片idex的存储key/value
if self.certain_mem_k is None:
self.certain_mem_k = key_k
self.certain_mem_v = key_v
else:
# shape的第2维就代表certain_mem_k存储的图片key/value的数量
self.certain_mem_k = torch.cat([self.certain_mem_k, key_k], 2)
self.certain_mem_v = torch.cat([self.certain_mem_v, key_v], 2)
# 统计当前图片前后传播给其他图片的范围
# 这部分与GUI界面中进度条有关
if total_cb is not None:
# 前向传播找最近的(min) idx---->
front_limit = min([ti for ti in self.interacted if ti > idx] + [self.t])
# 反向传播找最近的(max) <----idx
back_limit = max([ti for ti in self.interacted if ti < idx] + [-1])
# max<----idx---->min
# 传播不包括max和min以及自身idx
total_num = front_limit - back_limit - 2 # -1 for shift, -1 for center frame
if total_num > 0:
total_cb(total_num)
# 这部分与GUI界面中进度条有关
# 这部分与模型真在的传播过程有关
# True 正向传播 False 反向传播
self.do_pass(key_k, key_v, idx, True, step_cb=step_cb)
self.do_pass(key_k, key_v, idx, False, step_cb=step_cb)
# 这部分与模型真在的传播过程有关
# This is a more memory-efficient argmax
# mask对应的原始片像素位属于概率最大的obj
for ti in range(self.t):
self.masks[ti] = torch.argmax(self.prob[:, ti], dim=0)
out_masks = self.masks
# 去除padding部分
if self.pad[2]+self.pad[3] > 0:
out_masks = out_masks[:, :, self.pad[2]:-self.pad[3], :]
if self.pad[0]+self.pad[1] > 0:
out_masks = out_masks[:, :, :, self.pad[0]:-self.pad[1]]
# np_masks是为了GUI界面显示
self.np_masks = (out_masks.detach().cpu().numpy()[:, 0]).astype(np.uint8)
return self.np_masks
产生memory的key/value示意图:
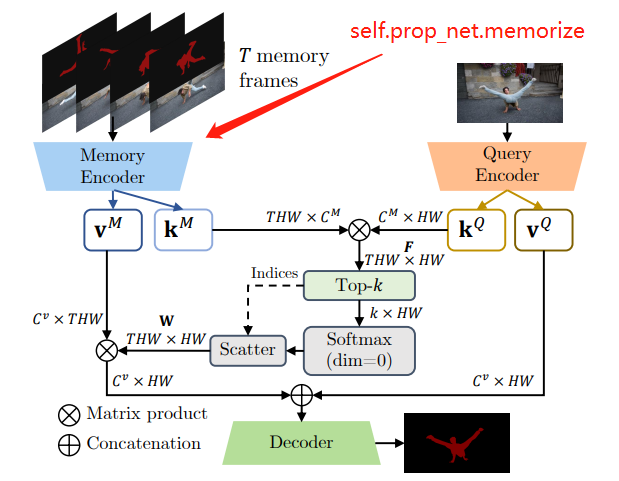
get_image_buffered函数
将当前带有对象掩码的帧放入到内存self.image_buf中。
def get_image_buffered(self, idx):
# 模型的加载模式(cpu/GPU)与数据的加载模式一致,数据不再处理
if self.data_dev == self.device:
return self.images[:, idx]
# 图片是否在图片缓冲区
if idx not in self.image_buf:
# 是否超过了图像缓冲区支持的最大缓冲值
if len(self.image_buf) > self.i_buf_size:
self.image_buf = {
} # 重置图片缓冲区
# 设置当前图片加载模式与模型的一致,并放入图像缓冲区,
self.image_buf[idx] = self.images[:, idx].to(self.device)
# 返回图片缓冲区
result = self.image_buf[idx]
return result
do_pass函数
传播和融合的完整过程。
双向传播操作,forward标志用判断是前向传播还是反向传播,一旦遇到结尾帧或者交互过的帧就停止传播。max<----idx---->min

差异感知与线性结果作为共同输入来预测最终的输出(fuse_one_frame)。
这里是传播和深度学习训练过程的传播不是一个概念
def do_pass(self, key_k, key_v, idx, forward=True, step_cb=None):
"""
Do a complete pass that includes propagation and fusion
key_k/key_v - memory feature of the starting frame
idx - Frame index of the starting frame
forward - forward/backward propagation
step_cb - Callback function used for GUI (progress bar) only
"""
# Pointer in the memory bank
# 已经存在的关键帧数量
num_certain_keys = self.certain_mem_k.shape[2]
# 关键帧指针
m_front = num_certain_keys
# Determine the required size of the memory bank
# 双向传播操作,一旦遇到结尾帧或者交互过的帧就停止传播
if forward:
# 前向传播找最近的(min) idx---->min
closest_ti = min([ti for ti in self.interacted if ti > idx] + [self.t])
# closest_ti - idx - 1:不包括idx和min; mem_freq是内存容量
total_m = (closest_ti - idx - 1)//self.mem_freq + 1 + num_certain_keys
else:
# 反向传播找最近的(max) max<----idx
closest_ti = max([ti for ti in self.interacted if ti < idx] + [-1])
# 不包括idx和max
total_m = (idx - closest_ti - 1)//self.mem_freq + 1 + num_certain_keys
K, CK, _, H, W = key_k.shape
_, CV, _, _, _ = key_v.shape
# Pre-allocate keys/values memory
keys = torch.empty((K, CK, total_m, H, W), dtype=torch.float32, device=self.device)
values = torch.empty((K, CV, total_m, H, W), dtype=torch.float32, device=self.device)
# Initial key/value passed in
# 初始化关键帧的key和value
keys[:, :, 0:num_certain_keys] = self.certain_mem_k
values[:, :, 0:num_certain_keys] = self.certain_mem_v
prev_in_mem = True
last_ti = idx # 在传播过程中保证在mem_freq范围内
# Note that we never reach closest_ti, just the frame before it
if forward:
# 前向传播的范围
this_range = range(idx+1, closest_ti)
step = +1
end = closest_ti - 1
else:
# 反向传播的范围
this_range = range(idx-1, closest_ti, -1)
step = -1
end = closest_ti + 1
for ti in this_range:
if prev_in_mem: # 包不包括idx的key/value
this_k = keys[:, :, :m_front]
this_v = values[:, :, :m_front]
else:
this_k = keys[:, :, :m_front+1]
this_v = values[:, :, :m_front+1]
query = self.get_query_kv_buffered(ti)
# 获得mask:正确区分背景和多个目标前景
out_mask = self.prop_net.segment_with_query(this_k, this_v, *query)
out_mask = aggregate_wbg(out_mask, keep_bg=True)
if ti != end:
keys[:, :, m_front:m_front+1], values[:, :, m_front:m_front+1] = self.prop_net.memorize(
self.get_image_buffered(ti), out_mask[1:])
if abs(ti-last_ti) >= self.mem_freq:
# Memorize the frame
m_front += 1
last_ti = ti
prev_in_mem = True
else:
prev_in_mem = False
# In-place fusion, maximizes the use of queried buffer
# esp. for long sequence where the buffer will be flushed
if (closest_ti != self.t) and (closest_ti != -1):
# 差异感知融合
self.prob[:, ti] = self.fuse_one_frame(closest_ti, idx, ti, self.prob[:, ti], out_mask,
key_k, query[3]).to(self.result_dev)
else:
self.prob[:, ti] = out_mask.to(self.result_dev)
# Callback function for the GUI
if step_cb is not None:
step_cb()
return closest_ti
产生query的key/value示意图:

计算query和memory的关系:
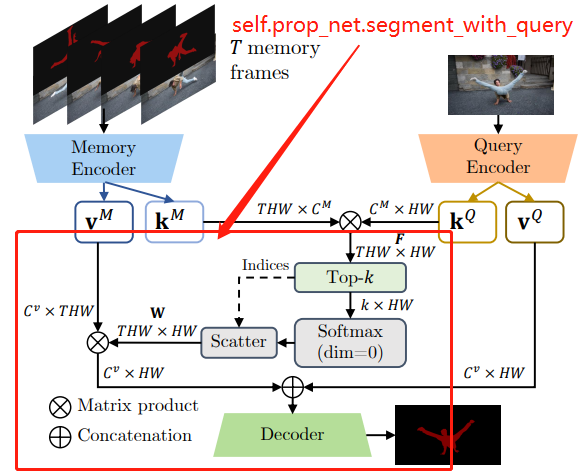
get_query_kv_buffered函数
def get_query_kv_buffered(self, idx):
# 图片是否在查询缓冲区
if idx not in self.query_buf:
# 是否超过了查询缓冲区支持的最大缓冲值
if len(self.query_buf) > self.q_buf_size:
self.query_buf = {
} # 重置查询缓存区
# 返回f16, f8, f4, k16, v16
# k16 [num_objects, 128, 1, H/16, W/16] v16 [num_objects, 512, 1, H/16, W/16]
self.query_buf[idx] = self.prop_net.get_query_values(self.get_image_buffered(idx))
# 返回查询缓冲区
result = self.query_buf[idx]
return result
fuse_one_frame函数
结合了差异感知融合方法与线性融合方法,将差异感知与线性结果作为共同输入,再通过一个简单的网络来预测最终的输出。
def fuse_one_frame(self, tc, tr, ti, prev_mask, curr_mask, mk16, qk16):
assert(tc<ti<tr or tr<ti<tc) # 必须在符合的传播范围内
prob = torch.zeros((self.k, 1, self.nh, self.nw), dtype=torch.float32, device=self.device)
nc = abs(tc-ti) / abs(tc-tr)
nr = abs(tr-ti) / abs(tc-tr)
# 时间相关
dist = torch.FloatTensor([nc, nr]).to(self.device).unsqueeze(0)
for k in range(1, self.k+1):
# 注意力位置
attn_map = self.prop_net.get_attention(mk16[k-1:k], self.pos_mask_diff[k:k+1], self.neg_mask_diff[k:k+1], qk16)
# 融合过程
w = torch.sigmoid(self.fuse_net(self.get_image_buffered(ti),
prev_mask[k:k+1].to(self.device), curr_mask[k:k+1].to(self.device), attn_map, dist))
prob[k-1] = w
return aggregate_wbg(prob, keep_bg=True)
融合的完整过程示意图。

总结
尽可能简单、详细的介绍MiVOS中Propagation模块的代码。后续会讲解Propagation的网络原理和代码(PropagationNetwork和FusionNet)以及MiVOS的训练。