【图像分割】【深度学习】PFNet官方Pytorch代码-PFNet网络PM定位模块解析
文章目录
前言
在详细解析PFNet代码之前,首要任务是成功运行PFNet代码【win10下参考教程】,后续学习才有意义。本博客讲解PFNet神经网络模块的PM定位模块代码,不涉及其他功能模块代码。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
PFNet网络简述
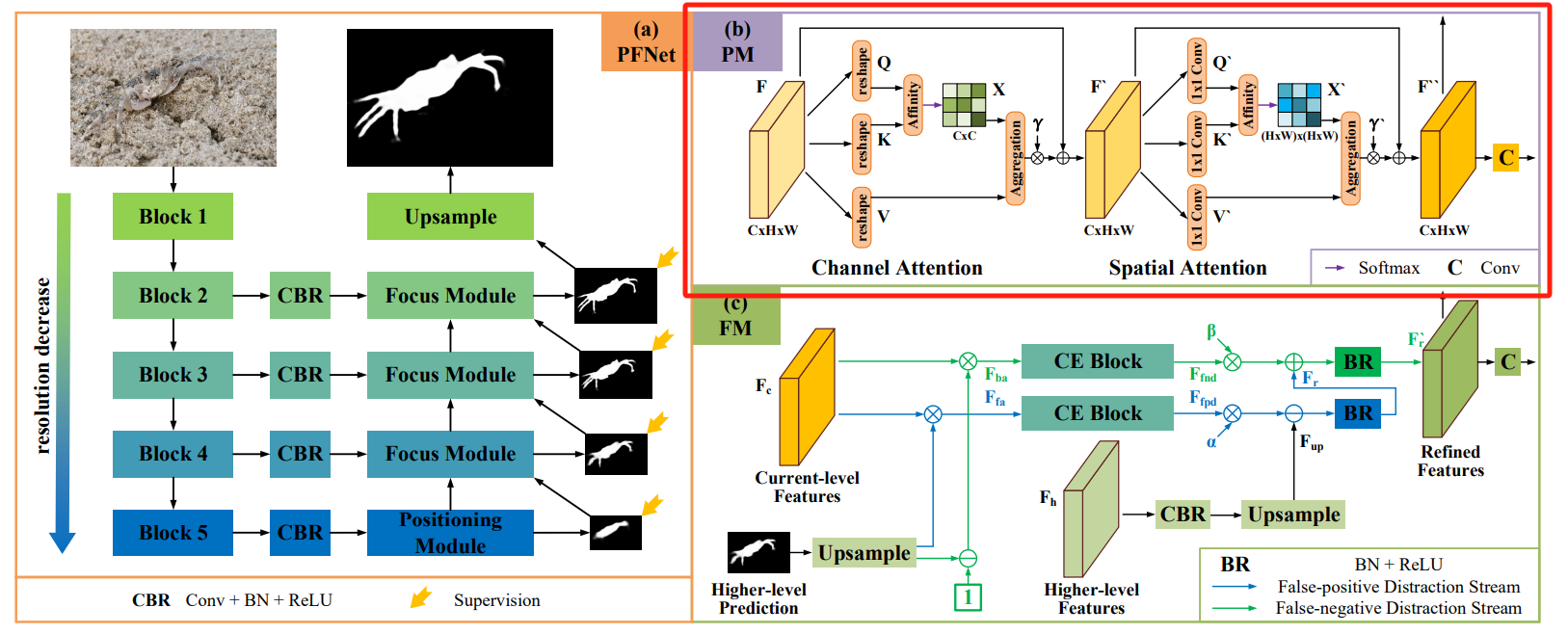
论文给出的PFNet整体架构如图所示:

输入一张RGB三通道彩色图像,先将其送入ResNet-50的backbone提取多尺度特征,然后将四个尺度的特征(layer1~4)分别通过四个卷积层(CBR)进行通道缩减。在最深层特征上使用定位模块PM来粗略定位潜在目标,然后再逐层通过聚焦模块FM细化分割结果,消除FP(假阳)和FN(假阴)的干扰,最终经过上采样后得到预测分割结果。
代码位置:PFNet.py
class PFNet(nn.Module):
def __init__(self, backbone_path=None):
super(PFNet, self).__init__()
# params
# backbone 主干网络
resnet50 = resnet.resnet50(backbone_path)
self.layer0 = nn.Sequential(resnet50.conv1, resnet50.bn1, resnet50.relu)
self.layer1 = nn.Sequential(resnet50.maxpool, resnet50.layer1)
self.layer2 = resnet50.layer2
self.layer3 = resnet50.layer3
self.layer4 = resnet50.layer4
# channel reduction
self.cr4 = nn.Sequential(nn.Conv2d(2048, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU())
self.cr3 = nn.Sequential(nn.Conv2d(1024, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU())
self.cr2 = nn.Sequential(nn.Conv2d(512, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU())
self.cr1 = nn.Sequential(nn.Conv2d(256, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU())
# positioning
self.positioning = Positioning(512)
# focus
self.focus3 = Focus(256, 512)
self.focus2 = Focus(128, 256)
self.focus1 = Focus(64, 128)
for m in self.modules():
if isinstance(m, nn.ReLU):
m.inplace = True
def forward(self, x):
# x: [batch_size, channel=3, h, w]
layer0 = self.layer0(x) # [-1, 64, h/2, w/2]
layer1 = self.layer1(layer0) # [-1, 256, h/4, w/4]
layer2 = self.layer2(layer1) # [-1, 512, h/8, w/8]
layer3 = self.layer3(layer2) # [-1, 1024, h/16, w/16]
layer4 = self.layer4(layer3) # [-1, 2048, h/32, w/32]
# channel reduction
cr4 = self.cr4(layer4)
cr3 = self.cr3(layer3)
cr2 = self.cr2(layer2)
cr1 = self.cr1(layer1)
# positioning
positioning, predict4 = self.positioning(cr4)
# focus
focus3, predict3 = self.focus3(cr3, positioning, predict4)
focus2, predict2 = self.focus2(cr2, focus3, predict3)
focus1, predict1 = self.focus1(cr1, focus2, predict2)
# rescale
predict4 = F.interpolate(predict4, size=x.size()[2:], mode='bilinear', align_corners=True)
predict3 = F.interpolate(predict3, size=x.size()[2:], mode='bilinear', align_corners=True)
predict2 = F.interpolate(predict2, size=x.size()[2:], mode='bilinear', align_corners=True)
predict1 = F.interpolate(predict1, size=x.size()[2:], mode='bilinear', align_corners=True)
if self.training:
return predict4, predict3, predict2, predict1
return torch.sigmoid(predict4), torch.sigmoid(predict3), torch.sigmoid(predict2), torch.sigmoid(
predict1)
主干网络
resnet网络结构讲解可以参看博主的博文【ResNet模型算法详解】,这里只讲解论文中使用到的主干网络相关的代码,其他主干网络的代码其实也大同小异,就不再赘述。
主干网络选择的是resnet50:
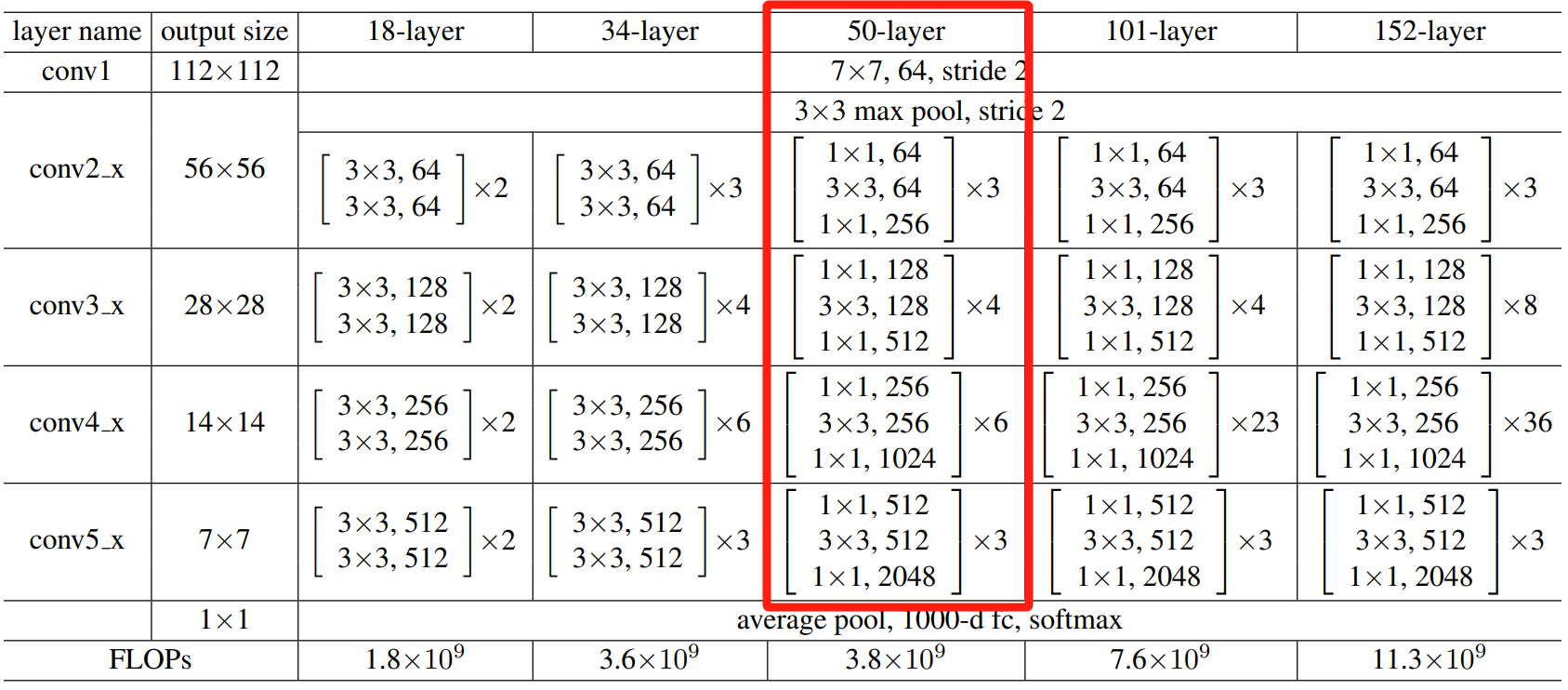
代码位置:backbone/resnet/resnet.py
def resnet50(backbone_path, pretrained=True, **kwargs):
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], backbone_path, pretrained, **kwargs)
def _resnet(arch, block, layers, backbone_path, pretrained, **kwargs):
# 初始化网络结构
model = ResNet(block, layers, **kwargs)
# 是否加载预训练网络
if pretrained:
# 通过提供的预训练权重存放路径加载预训练权重
state_dict = torch.load(backbone_path)
model.load_state_dict(state_dict)
print("From {} Load {} Weights Succeed!".format(backbone_path, arch))
return model
1×1卷积和3×3卷积是组成resnet网络最基本的结构单元。
# 3×3卷积构成
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
# pfnet的主干网络不涉及分组卷积和空洞卷积
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
# 1×1卷积
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
强调一点,pfnet的主干网络不涉及分组卷积和空洞卷积,只用到了常规卷积,因此groups和dilation默认值都是1,因此读者阅读resnet.py代码时候不必过多纠结。
resnet50的是由基础卷积块Bottleneck(block)搭建而成,只是不同深度的卷积块的channel有所不同:
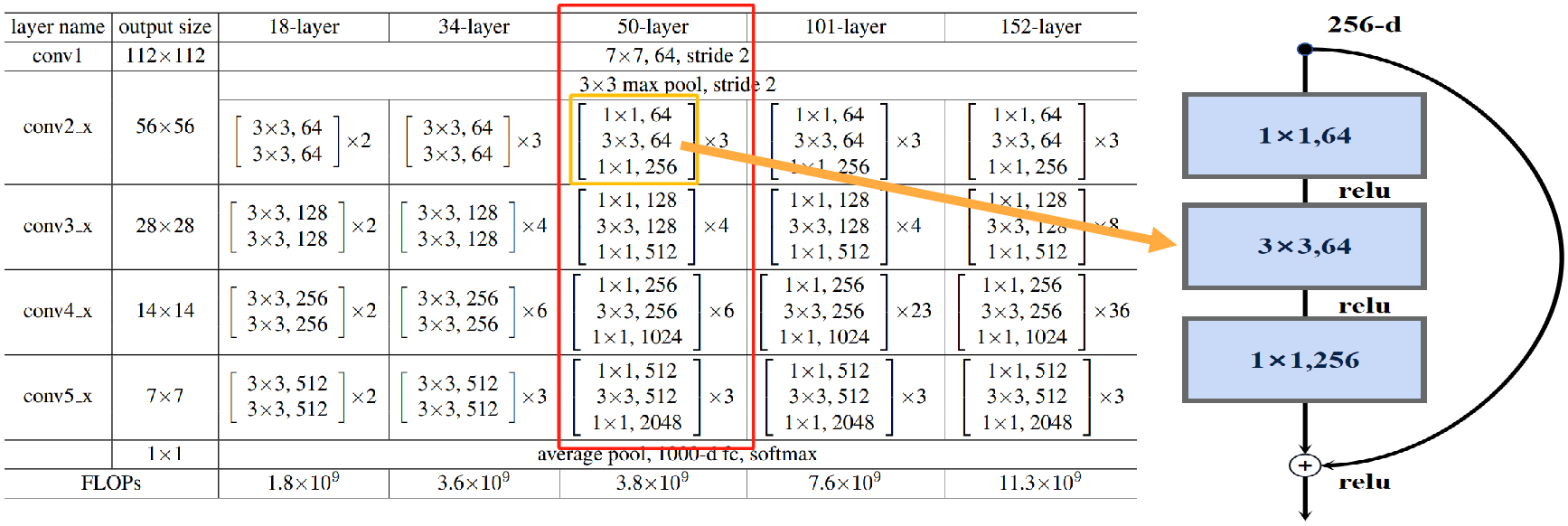
class Bottleneck(nn.Module):
expansion = 4
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# 1×1卷积
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
# 3×3卷积
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
# 1×1卷积
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
# shortcut连接
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
resnet50主干网络搭建
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
# 分组卷积相关可以忽略
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
# 分组卷积相关可以忽略
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
# 图像分类器部分可以忽略
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 图像分类器部分可以忽略
# 模型初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 对部分模块进行零初始化
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
# 空洞卷积相关可以忽略
if dilate:
self.dilation *= stride
# 空洞卷积相关可以忽略
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
定位模块 Positioning Module
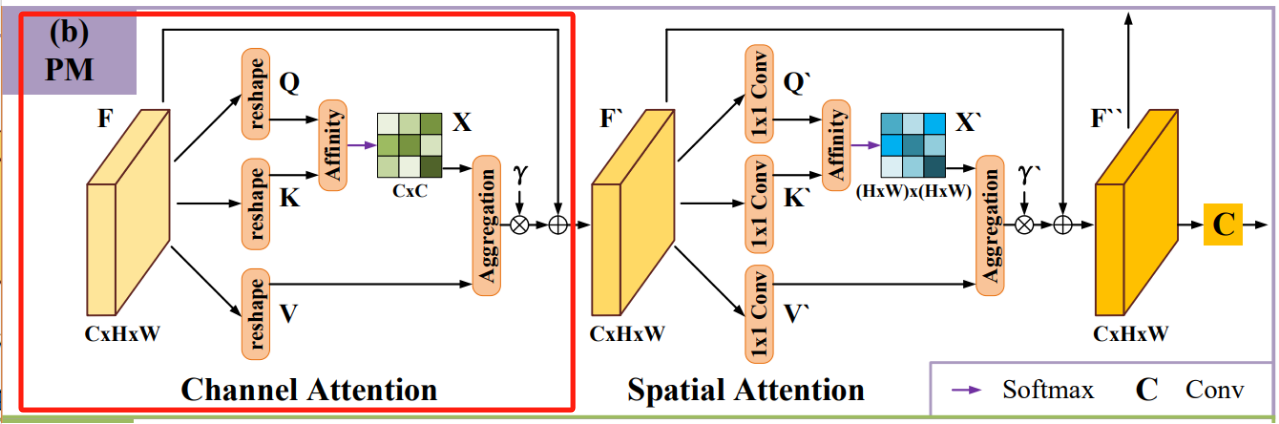
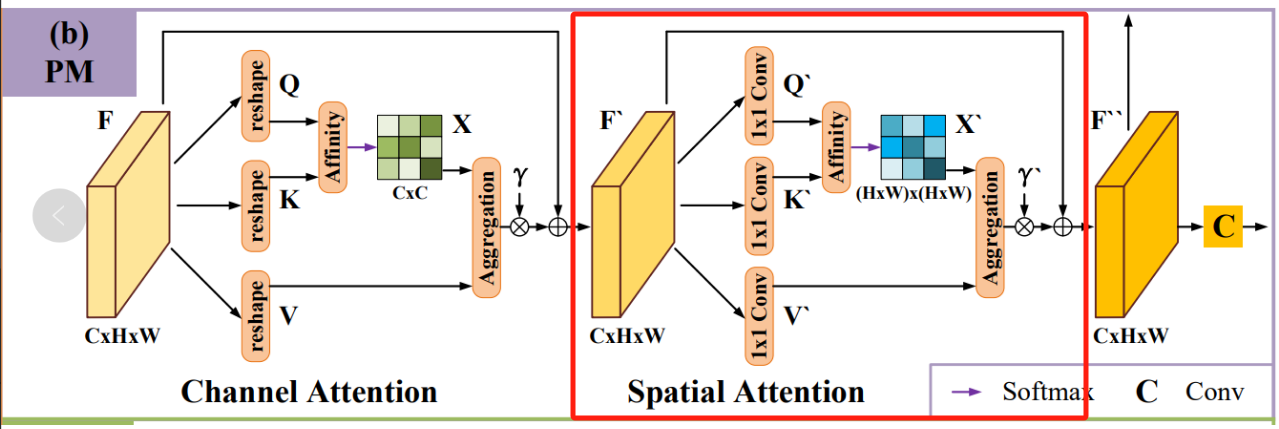
原论文中定位模块(Positioning Module,PM)的结构如下图所示:
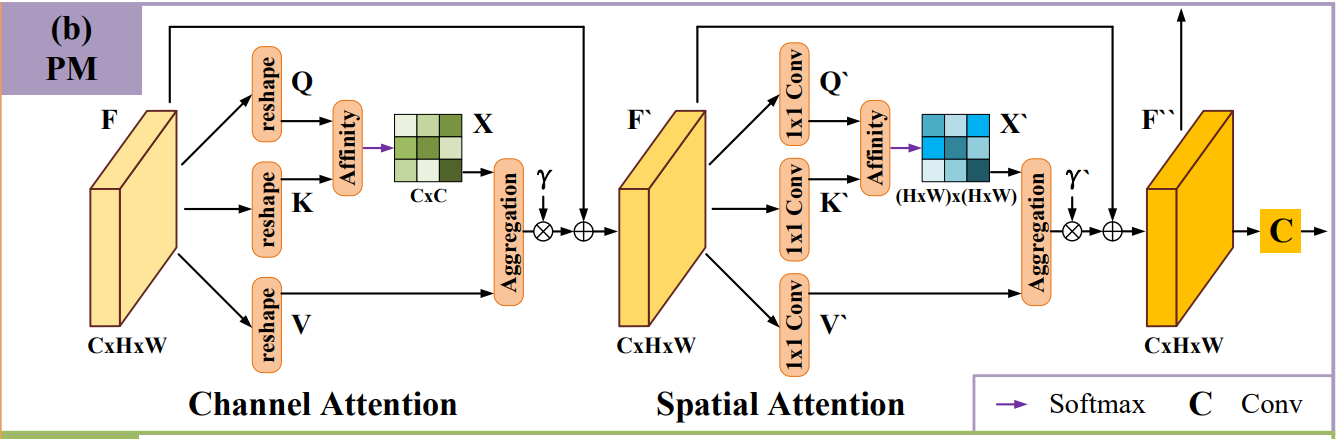
在输入深层特征 F F F后,分别经过通道注意力模块(Channel Attention)和空间注意力模块(Spatial Attention) 捕捉通道和空间位置上的依赖关系,最后再经过一层卷积获得更准确的预测图。
代码位置:PFNet.py
class Positioning(nn.Module):
def __init__(self, channel):
super(Positioning, self).__init__()
self.channel = channel
# Channel Attention
self.cab = CA_Block(self.channel)
# Spatial Attention
self.sab = SA_Block(self.channel)
# 7×7卷积
self.map = nn.Conv2d(self.channel, 1, 7, 1, 3)
def forward(self, x):
cab = self.cab(x)
sab = self.sab(cab)
map = self.map(sab)
return sab, map
通道注意力模块 Channel Attention
捕捉通道之间的依赖关系, 输入特征图 F ∈ R C × H × W F \in {R^{C \times H \times W}} F∈RC×H×W, C C C代表输入特征图通道数目, H H H表示特征图高度, W W W表示特征图宽度,对 F F F进行reshape获得query Q Q Q、key K K K和value V V V,其中 { Q , K , V } ∈ R C × N , N = H × W \left\{ { {\rm{Q}},{\rm{K}},{\rm{V}}} \right\} \in {R^{C \times N}},N = H \times W { Q,K,V}∈RC×N,N=H×W为特征图像素数量:
- 对 Q Q Q和 K T {K^T} KT( K K K的转置)使用矩阵乘法而后进行softmax归一化计算出通道注意力图 X ∈ R C × C X \in {R^{C \times C}} X∈RC×C:
x i j = exp ( Q i : ⋅ K : j T ) ∑ j = 1 C exp ( Q i : ⋅ K : j T ) {x_{ij}} = \frac{ {\exp \left( { {Q_{i:}} \cdot K_{\rm{:j}}^T} \right)}}{ {\sum\limits_{j = 1}^C {\exp \left( { {Q_{i:}} \cdot K_{\rm{:j}}^T} \right)} }} xij=j=1∑Cexp(Qi:⋅K:jT)exp(Qi:⋅K:jT)
其中, Q i : Q_{i:} Qi:表示矩阵 Q Q Q的第 i i i行, K : j T K_{\rm{:j}}^T K:jT表示矩阵 K K K的第 j j j行, x i j x_{ij} xij表示特征图中第j个通道对第i个通道的影响。 - 将 x i j x_{ij} xij与 V j : V_{j:} Vj:矩阵进行矩阵乘法,并将结果reshape成 R C × H × W {R^{C \times H \times W}} RC×H×W,为了增强容错能力,将结果乘以可学习的尺度参数 γ \gamma γ,得到最终输出 F ′ ∈ R C × H × W {F^\prime} \in{R^{C \times H \times W}} F′∈RC×H×W:
F i : ′ = γ ∑ j = 1 C ( x i j V j : ) + F i : F_{\rm{i:}}^\prime{\rm{ }} = \gamma \sum\limits_{j= 1}^C {\left( { { {\rm{x}}_{ij}}{V_{j:}}} \right)} + {F_{\rm{i:}}}{\rm{ }} Fi:′=γj=1∑C(xijVj:)+Fi:
其中, γ \gamma γ从初始值1逐渐学习权重。
代码位置:PFNet.py
class CA_Block(nn.Module):
def __init__(self, in_dim):
super(CA_Block, self).__init__()
self.chanel_in = in_dim
# 可训练参数γ
self.gamma = nn.Parameter(torch.ones(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps (B X C X H X W)
returns :
out : channel attentive features
"""
# [B,C,H,W]
m_batchsize, C, height, width = x.size()
# [B,C,H X W]
proj_query = x.view(m_batchsize, C, -1)
# [B,H X W,C]
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
# [B,C,C]
energy = torch.bmm(proj_query, proj_key)
# [B,C,C]
attention = self.softmax(energy)
# [B,C,H X W]
proj_value = x.view(m_batchsize, C, -1)
# [B,C,H X W]
out = torch.bmm(attention, proj_value)
# [B,C,H,W]
out = out.view(m_batchsize, C, height, width)
# [B,C,H,W]
out = self.gamma * out + x
return out
可能上述代码理解起来有点困难,博主将以上代码绘制成以下流程示意图:
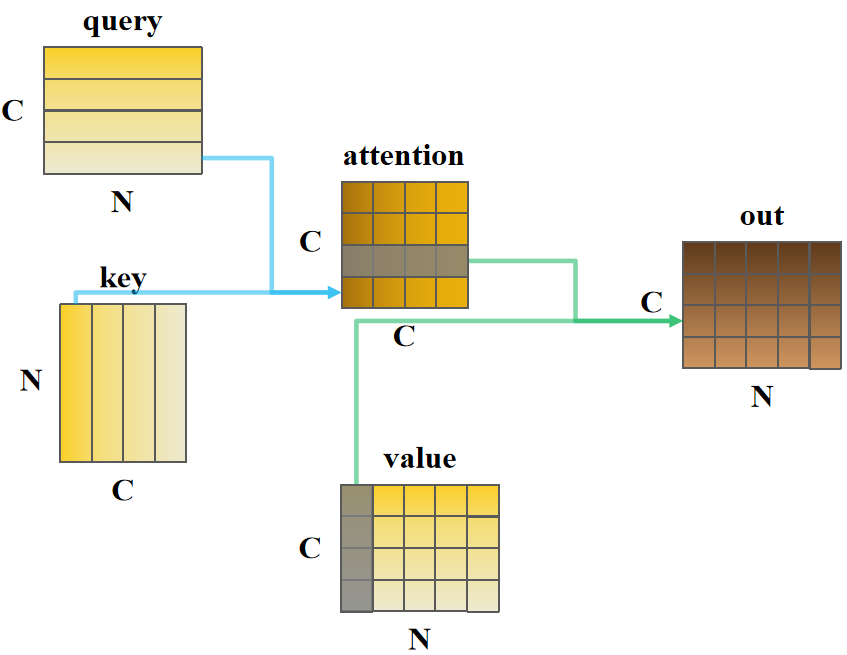
如图所示,query的第4行和key的第1列矩阵相乘计算出了attention的第4行1列的值,表示特征图中第4个通道与第1个通道的"亲疏关系";那么attention的第4行整体就表示第4个通道对包括其自身的所有通道的亲疏关系。
计算特征图通道 m m m和 n n n的亲疏关系:首先计算俩个通道中每个空间位置 N i m N_i^m Nim和 N i n N_i^n Nin的乘积,而后再将所有乘积相加,即矩阵相乘,再进行softmax计算而,因此"亲疏关系"总和为1,亲疏值越大关系越紧密。通道注意力图attention是对称矩阵, i i i行 j j j列表示通道 j j j对通道 i i i的影响。
attention的第3行和value的第1列矩阵相乘计算出out的第3行第1列的值,是根据输入特征图value所有通道的第1个空间位置加权attention第3个通道相关亲疏值再相加综合计算得到;那么out的第3行是根据输入特征图value的所有通道的每个空间位置分别加权相同通道亲疏值再相加得到。
空间注意力模块 Spatial Attention
捕捉空间位置的依赖关系, 将通道注意力模块的输出特征 F ′ F^\prime F′作为输入,使用3个1×1的卷积层对 F ′ F^\prime{\rm{ }} F′进行卷积和reshape后得到 Q ′ Q^\prime Q′、 K ′ K^\prime K′和 V ′ V^\prime V′,其中 { Q ′ , K ′ } ∈ R N × C 8 , V ′ ∈ R C × N \left\{ { {Q^\prime},{K^\prime}} \right\} \in {R^{N\times \frac{C}{8} }},{V^\prime} \in {R^{C \times N}} { Q′,K′}∈RN×8C,V′∈RC×N:
- 对 Q ′ Q^\prime Q′和 K ′ T K^{\prime T} K′T( K ′ K^\prime K′的转置)使用矩阵乘法而后进行softmax归一化计算出空间注意力图 X ′ ∈ R N × N X^\prime \in {R^{N \times N}} X′∈RN×N:
x i j = exp ( Q i : ′ ⋅ K : j ′ T ) ∑ j = 1 N exp ( Q i : ′ ⋅ K : j ′ T ) {x_{ij}} = \frac{ {\exp \left( { {Q_{i:}^\prime} \cdot K_{\rm{:j}}^{\prime T}} \right)}}{ {\sum\limits_{j = 1}^N {\exp \left( { {Q_{i:}^\prime} \cdot K_{\rm{:j}}^{\prime T}} \right)} }} xij=j=1∑Nexp(Qi:′⋅K:j′T)exp(Qi:′⋅K:j′T)
其中, Q i : ′ Q_{i:}^\prime Qi:′表示矩阵 Q Q Q的第 i i i行, K : j ′ T K_{\rm{:j}}^{\prime T} K:j′T表示矩阵 K ′ K^\prime K′的第 j j j行, x i j ′ x_{ij}^\prime xij′表示特征图中第j个空间位置对第i个空间位置的影响。 - 将 x i j ′ x_{ij}^\prime xij′与 V i : ′ V_{i:}^\prime Vi:′矩阵进行矩阵乘法,并将结果reshape成 R C × H × W {R^{C \times H \times W}} RC×H×W,为了增强容错能力,将结果乘以可学习的尺度参数 γ ′ \gamma^\prime γ′,得到最终输出 F ′ ′ ∈ R C × H × W {F^{\prime \prime}} \in{R^{C \times H \times W}} F′′∈RC×H×W:
F i : ′ ′ = γ ′ ∑ j = 1 C ( V i : x i j ) + F i : ′ F_{\rm{i:}}^{\prime \prime}{\rm{ }} = \gamma^{\prime} \sum\limits_{j= 1}^C {\left( { { {V_{i:}}{\rm{x}}_{ij}}} \right)} + {F_{\rm{i:}}^{\prime}}{\rm{ }} Fi:′′=γ′j=1∑C(Vi:xij)+Fi:′
其中, γ \gamma γ从初始值1逐渐学习权重。
代码位置:PFNet.py
class SA_Block(nn.Module):
def __init__(self, in_dim):
super(SA_Block, self).__init__()
self.chanel_in = in_dim
# 3个1×1卷积
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
# 可训练参数γ
self.gamma = nn.Parameter(torch.ones(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps (B X C X H X W)
returns :
out : spatial attentive features
"""
# [B,C,H,W]
m_batchsize, C, height, width = x.size()
# [B,H X W,C]
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1)
# [B,C,H X W]
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height)
# [B,H X W,H X W]
energy = torch.bmm(proj_query, proj_key)
# [B,H X W,H X W]
attention = self.softmax(energy)
# [B,C,H X W]
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height)
# [B,C,H X W]
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
# [B,C,H,W]
out = out.view(m_batchsize, C, height, width)
# [B,C,H,W]
out = self.gamma * out + x
return out
可能上述代码理解起来有点困难,博主将以上代码绘制成以下流程示意图:
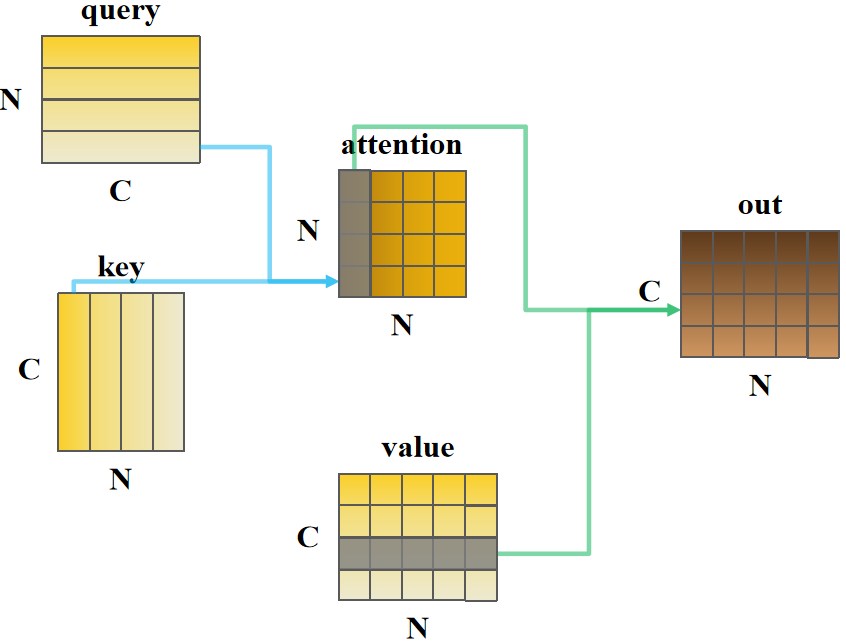
同理,如图所示,query的第4行和key的第1列矩阵相乘计算出了attention的第4行1列的值,表示特征图中第4个空间位置与第1个空间位置的"亲疏关系",那么attention的第4行整体就表示第4个空间位置对包括其自身的所有空间位置的亲疏关系。
计算特征图空间位置 m m m和 n n n的亲疏关系:首先计算俩个空间位置中每个通道 C i m C_i^m Cim和 C i n C_i^n Cin的乘积,而后再将所有乘积相加,即矩阵相乘,再进行softmax计算而,因此"亲疏关系"总和为1,亲疏值越大关系越紧密。空间位置注意力图attention是对称矩阵, i i i行 j j j列表示空间位置 j j j对空间位置 i i i的影响。
value的第3行矩阵和attention的第1列矩阵相乘计算出out的第3行第1列的值,是根据输入特征图value第3个通道的所有空间位置加权attention第1个空间位置相关亲疏值再相加综合计算得到,那么out的第3行是根据输入特征图value的第3个通道的所有空间位置分别加权每个空间位置亲疏值再相加得到。
总结
尽可能简单、详细的介绍PFNet网络中的主干网络模块和PM定位模块的结构和代码。