【图像分割】【深度学习】PFNet官方Pytorch代码-PFNet网络损失函数模块解析
前言
在详细解析PFNet代码之前,首要任务是成功运行PFNet代码【win10下参考教程】,后续学习才有意义。本博客讲解PFNet神经网络模块的损失函数模块代码,不涉及其他功能模块代码。
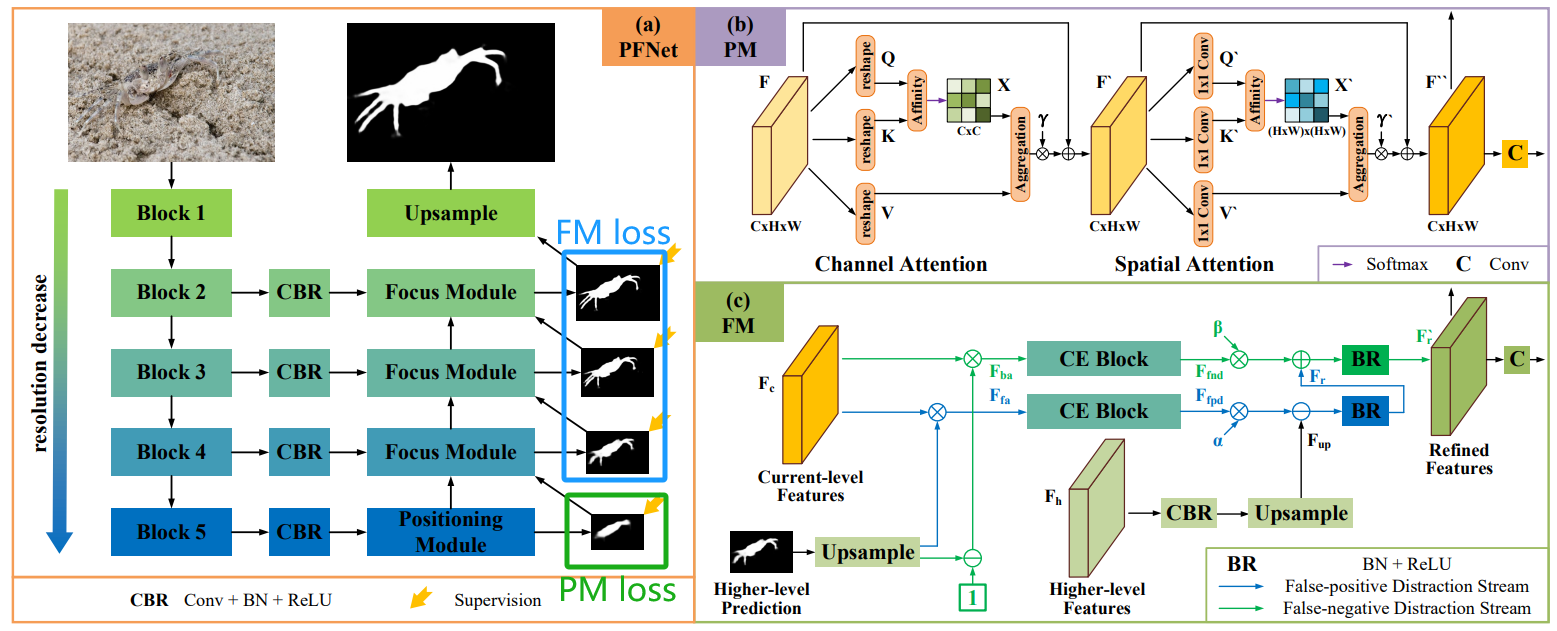
PFNet中有四个输出预测,一个来自定位模块(PM),三个来自聚焦模块(FM),整体的损失函数为:
ℓ o v e r a l l = ℓ p m + ∑ i = 1 3 2 ( 3 − i ) ℓ f m i {\ell _{overall}}{\rm{ }} = {\rm{ }}{\ell _{pm}} + \sum\limits_{i = 1}^3 {
{2^{(3 - i)}}} \ell _{fm}^i ℓoverall=ℓpm+i=1∑32(3−i)ℓfmi
其中 ℓ f m i \ell _{fm}^i ℓfmi表示在PFNet网络中至上往下第 i i i个的聚焦模块的预测的损失。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
PM定位模块损失函数
对于PM模块,使用二值交叉熵损失(Binary CrossEntropy Loss,BCE)损失 ℓ b c e \ell _{
{\rm{bce}}} ℓbce和IoU损失 ℓ i o u \ell _{
{\rm{iou}}} ℓiou的输出,即 ℓ p m = ℓ b c e + ℓ i o u {\ell _{
{\rm{pm}}}} = {\ell _{
{\rm{bce}}}} + {\ell _{
{\rm{iou}}}} ℓpm=ℓbce+ℓiou,以引导PM探索目标对象的初始位置。
二值交叉熵损失 ℓ i o u \ell _{
{\rm{iou}}} ℓiou是常见用法,因此不再具体讲解,本小节主要介绍 ℓ i o u \ell _{
{\rm{iou}}} ℓiou,因为它不同于目标检测中用于衡量预测边界框与真实边界框之间的重叠程度,而在论文中对此并没有详细解释,因此博主根据论文源码绘制以下示意图具体讲解 ℓ i o u \ell _{
{\rm{iou}}} ℓiou的作用:

ℓ i o u = 1 − i o u {\ell _{
{\rm{iou}}}} = 1 - iou ℓiou=1−iou, i o u iou iou重合度越高, ℓ i o u \ell _{
{\rm{iou}}} ℓiou损失越小, i o u = i n t e r u n i o n − i n t e r iou = \frac{
{
{\rm{inter}}}}{
{
{\rm{union - inter}}}} iou=union−interinter。那么 i n t e r inter inter和 u n i o n − i n t e r union - inter union−inter分别表示什么含义呢?博主将根据所绘制的示意图详细说明其中的含义,如上图所示, m a s k mask mask只有前景为1背景为0俩种值, p r e d pred pred的取值范围则在(0~1)之间,为了方便理解博主也是暴力的拆解成前景为0.8背景为0.2俩种值。
- i n t e r inter inter表示真实标签 m a s k mask mask和预测标签 p r e d pred pred对应像素相乘后再对像素值求和的值,如上图的inter所示(只表示到对应元素相乘), i n t e r inter inter的含义可以理解成真实标签的前景部分在预测标签上的预测结果,简单来说就是只考虑预测标签针对真实前景的预测效果,默认背景部分完全预测正确,屏蔽了背景不作考虑,因此 i n t e r = T b + P f inter=T_b+P_f inter=Tb+Pf;
- u n i o n union union表示真实标签 m a s k mask mask和预测标签 p r e d pred pred对应像素相加后再对像素值求和的值,如上图的union所示(只表示到对应元素相加),那么 u n i o n − i n t e r union-inter union−inter的含义可以理解成真实标签的背景部分在预测标签上的预测结果,如上图的union-inter所示,简单来说就是只考虑预测标签针对真实背景的预测效果,默认前景部分完全预测正确,屏蔽了前景不作考虑,因此 u n i o n − i n t e r = T f + P b union-inter=T_f+P_b union−inter=Tf+Pb。
T b T_b Tb表示背景位置真实像素求和值(也就是0), P f P_f Pf表示前景位置预测像素求和值, T f T_f Tf表示前景位置真实像素求和值, P b P_b Pb表示背景位置预测像素求和值。
注意!!!!区分背景位置预测像素和预测背景像素俩个概念!!!前者是真实背景像素位置可能真确预测为背景,也可能错误预测成前景;后者则是对预测一个像素位置为背景。
解释了 i n t e r inter inter和 u n i o n − i n t e r union - inter union−inter的含义, i o u iou iou也可以表示成 i o u = T b + P f T f + P p iou = \frac{
{
{T_b} + {P_{\rm{f}}}}}{
{
{T_f} + {P_p}}} iou=Tf+PpTb+Pf, T b T_b Tb和 T f T_f Tf是固定不变的,那么 ℓ i o u \ell _{
{\rm{iou}}} ℓiou的优化目标就是 P f P_f Pf越来越大且 P b P_b Pb越来越小。
代码位置:train.py
# PM loss function
bce_loss = nn.BCEWithLogitsLoss().cuda(device_ids[0])
iou_loss = loss.IOU().cuda(device_ids[0])
def bce_iou_loss(pred, target):
bce_out = bce_loss(pred, target)
iou_out = iou_loss(pred, target)
loss = bce_out + iou_out
return loss
代码位置:loss.py
博主为了方便大家理解,小改了下源码,但是没有丝毫影响源码的原始目的。
class IOU(torch.nn.Module):
def __init__(self):
super(IOU, self).__init__()
def _iou(self, pred, target):
pred = torch.sigmoid(pred)
# 交集区域
inter = (pred * target).sum(dim=(2, 3))
# 并集区域
union = (pred + target).sum(dim=(2, 3))
# iou损失
iou = 1 - (inter / (union- inter))
return iou.mean()
def forward(self, pred, target):
return self._iou(pred, target)
FM聚焦模块损失函数
对于FM模块,希望更多地关注对象的边界、细长区域或孔处等分散注意力区域。因此,使用加权二值交叉熵损失(Binary CrossEntropy Loss,BCE)损失 ℓ w b c e \ell _{
{\rm{wbce}}} ℓwbce和加权IoU损失 ℓ w i o u \ell _{
{\rm{wiou}}} ℓwiou的输出,即 ℓ f m = ℓ w b c e + ℓ w i o u {\ell _{
{\rm{fm}}}} = {\ell _{
{\rm{wbce}}}} + {\ell _{
{\rm{wiou}}}} ℓfm=ℓwbce+ℓwiou,以迫使FM更加关注可能的分散注意力区域。
ℓ i o u \ell _{
{\rm{iou}}} ℓiou在上个章节就进行了说明, ℓ w i o u \ell _{
{\rm{wiou}}} ℓwiou大同小异,因此不再具体讲解,本小节主要介绍 ℓ w b c e \ell _{
{\rm{wbce}}} ℓwbce和 ℓ w i o u \ell _{
{\rm{wiou}}} ℓwiou中的 w w w权重的产生,在论文中对此并没有详细解释,因此博主根据论文源码绘制以下示意图具体讲解 w w w的作用:
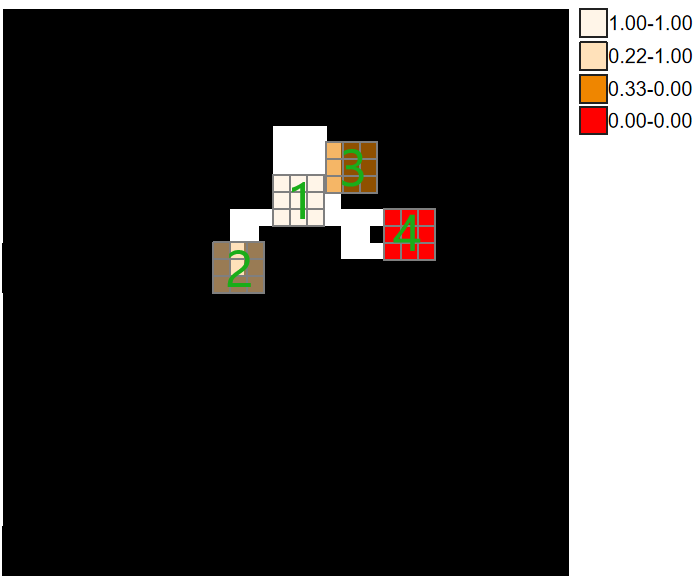
w w w权重是通过对标签 m a s k mask mask进行平均池化操作,再减去 m a s k mask mask,最后取绝对值:
w = 1 + 5 × ∣ A v g P o o l ( m a s k ) − m a s k ∣ w = 1 + 5 \times \left| {\left. {AvgPool(mask) - mask} \right|} \right. w=1+5×∣AvgPool(mask)−mask∣
为什么这么简单的操作就能让 w w w更加关注可能的分散注意力区域?博主分以下几种情况讨论:
- 第一种情况:如上图1所示位置,该前景像素位于前景目标的内部,因此不是对象的边界、细长区域或孔处等分散注意力区域,其 w w w权重计算为1,不需要对其做额外加强;
- 第二种情况:如上图2所示位置,该前景像素是对象的边界,属于分散注意力区域,其 w w w权重计算为4.9,可谓是剧烈加强;
- 第三种情况:如上图3所示位置,该背景像素是模糊边界,也属于分散注意力区域,其 w w w权重计算为4.3,也是剧烈加强;
- 第四种情况:如上图4所示位置,该像素是背景,其 w w w权重计算为1,不需要对其做额外加强;
博主绘制的示意图只是为了方便理解,真实的池化核大小不可能只有3×3那么小,源码中使用的池化核大小是31×31。
代码位置:train.py
# FM loss function
structure_loss = loss.structure_loss().cuda(device_ids[0])
代码位置:loss.py
class structure_loss(torch.nn.Module):
def __init__(self):
super(structure_loss, self).__init__()
def _structure_loss(self, pred, mask):
print(pred.shape)
# 根据mask标签生成关于mask的权重
# 根据公式可以知道,越是靠近前景目标边缘的像素,权重可能就越高,而越靠近前景目标的中心的像素权重越低,最低为1
weit = 1 + 5 * torch.abs(F.avg_pool2d(mask, kernel_size=31, stride=1, padding=15) - mask)
# 因为预测标签还要进行加权,暂时需要保留结构,所以损失在每个元素上计算,reduce选择none
wbce = F.binary_cross_entropy_with_logits(pred, mask, reduce='none')
# 加权的bce
wbce = (weit * wbce).sum(dim=(2, 3)) / weit.sum(dim=(2, 3))
pred = torch.sigmoid(pred)
# 交集区域
inter = ((pred * mask) * weit).sum(dim=(2, 3))
# 并集区域
union = ((pred + mask) * weit).sum(dim=(2, 3))
# 加权的iou损失
wiou = 1 - (inter) / (union - inter)
return (wbce + wiou).mean()
def forward(self, pred, mask):
return self._structure_loss(pred, mask)
总结
尽可能简单、详细的介绍PFNet网络中的损失函数模块的结构和代码。