【视频分割】【深度学习】MiVOS官方Pytorch代码–Propagation模块FusionNet网络解析
MiVOS模型将交互到掩码和掩码传播分离,从而实现更高的泛化性和更好的性能。单独训练的交互模块将用户交互转换为对象掩码,传播模块使用一种新的top-k过滤策略在读取时空存储器时进行临时传播,本博客将讲解Propagation(用户交互产生分割图)模块中的深度学习网络代码,Propagation模块封装了PropagationNet和FusionNet模型。

文章目录
前言
在详细解析MiVOS代码之前,首要任务是成功运行MiVOS代码【win10下参考教程】,后续学习才有意义。
本博客讲解Propagation模块的深度网络(FusionNet)代码,不再复述其他功能模块代码。
MiVOS原论文中关于Fusion Module的示意图:
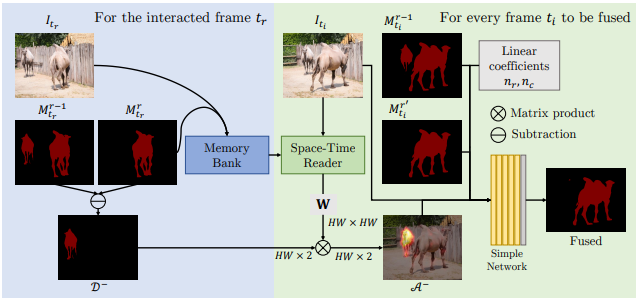
关键帧是用户在某一帧有交互行为,传播帧是根据这些交互行为而需要改变的帧。
AttentionMemory
注意力区域:在model/propagation/prop_net.py文件内
pos_mask和neg_mask是关键帧的mask与当前传播帧上次的mask之间进行算术运算操作得到的"差异",attn_memory(AttentionMemory)方法通过Memory key特征和Query key特征计算得到weight map(权重图),然后pos_mask和neg_mask做加权获得pos_map和neg_map。
class AttentionMemory(nn.Module):
def __init__(self, k):
super().__init__()
self.k = k
def forward(self, mk, qk):
"""
T=1 only. Only needs to obtain W
"""
B, CK, _, H, W = mk.shape
mk = mk.view(B, CK, H*W)
mk = torch.transpose(mk, 1, 2) # B * HW * CK
qk = qk.view(1, CK, H*W).expand(B, -1, -1) / math.sqrt(CK) # B * CK * HW
affinity = torch.bmm(mk, qk) # B * HW * HW
affinity = F.softmax(affinity, dim=1)
return affinity
pos_mask和neg_mask分别做加权获得新的pos_map和neg_map后拼接。
def get_W(self, mk16, qk):
W = self.attn_memory(mk16, qk)
return W
def get_attention(self, mk16, pos_mask, neg_mask, qk16):
b, _, h, w = pos_mask.shape
nh = h//16
nw = w//16
W = self.get_W(mk16, qk16)
pos_map = (F.interpolate(pos_mask, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W)
neg_map = (F.interpolate(neg_mask, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W)
attn_map = torch.cat([pos_map, neg_map], 1)
attn_map = attn_map.reshape(b, 2, nh, nw)
attn_map = F.interpolate(attn_map, mode='bilinear', size=(h,w), align_corners=False)
return attn_map

weight map(权重图)是关键帧的Memory key 和当前传播的帧Query key矩阵相乘计算而来,而后加权到pos_mask和neg_mask获得pos_map和neg_map。PropagationNet也有一部类似的操作,注意区分。
FusionNet类
class FusionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(9, 32, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
)
self.relu = nn.ReLU()
self.final_conv = nn.Conv2d(32, 1, kernel_size=3, padding=1, stride=1)
def forward(self, im, seg1, seg2, attn, time):
'''
Args:
im: 原始图片
seg1: 当前传播帧上次生成的mask
seg2: PropagationNet生成的当前传播帧mask
attn: 注意力区域
time: 时间
Returns:
'''
h, w = im.shape[-2:]
time = time.unsqueeze(2).unsqueeze(2)
time = time.expand(-1, -1, h, w)
x = torch.cat([im, seg1, seg2, attn, time], 1)
x = self.conv1(x)
r = self.conv2(x)
x = self.relu(x + r)
r = self.conv3(x)
x = self.relu(x + r)
x = self.final_conv(x)
return x
网络结构如下图所示:

fuse_one_frame
在inference_core.py内
时间相关其实就是看当前传播帧离前向传播和反向传播的终点的距离,现在有了原始图片、当前传播帧上次的mask、PropagationNet输出传播帧的mask和注意力区域就能通过fuse_net(FusionNet)融合出传播帧此次的mask。
def fuse_one_frame(self, tc, tr, ti, prev_mask, curr_mask, mk16, qk16):
assert(tc<ti<tr or tr<ti<tc) # 必须在符合的传播范围内
prob = torch.zeros((self.k, 1, self.nh, self.nw), dtype=torch.float32, device=self.device)
nc = abs(tc-ti) / abs(tc-tr)
nr = abs(tr-ti) / abs(tc-tr)
# 时间相关
dist = torch.FloatTensor([nc, nr]).to(self.device).unsqueeze(0)
for k in range(1, self.k+1):
# 注意力位置
attn_map = self.prop_net.get_attention(mk16[k-1:k], self.pos_mask_diff[k:k+1], self.neg_mask_diff[k:k+1], qk16)
# 融合过程
w = torch.sigmoid(self.fuse_net(self.get_image_buffered(ti),
prev_mask[k:k+1].to(self.device), curr_mask[k:k+1].to(self.device), attn_map, dist))
prob[k-1] = w
return aggregate_wbg(prob, keep_bg=True)
总结
尽可能简单、详细的介绍MiVOS中Propagation模块中FusionNet网络的代码。后续会讲解MiVOS的训练。