【图像分割】【深度学习】PFNet官方Pytorch代码-PFNet网络FM聚焦模块解析
前言
在详细解析PFNet代码之前,首要任务是成功运行PFNet代码【win10下参考教程】,后续学习才有意义。本博客讲解PFNet神经网络模块的FM聚焦模块代码,不涉及其他功能模块代码。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
聚焦模块 Focus Module
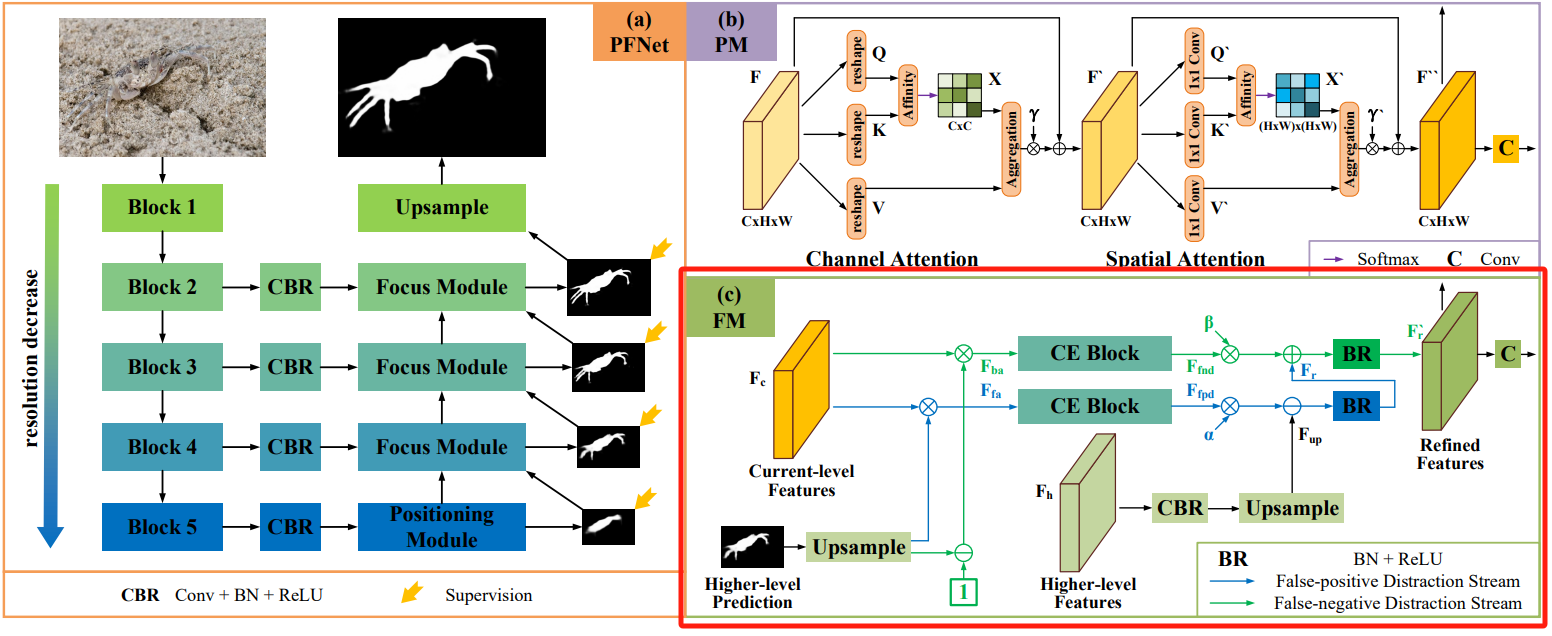
原论文中聚焦模块(Focus Module,FM)的结构如下图所示:
由于伪装对象通常与背景具有相似的外观,因此初始预测中会有假阳(FP)和假阴(FN)预测,设计使用FM聚焦模块发现和删除这些错误预测。
- 对高层预测(Higher-level Prediction)进行上采样并用sigmoid层对其进行归一化生成 F h p F_{ {\rm{hp}}} Fhp,并将 F h p F_{ {\rm{hp}}} Fhp与 ( 1 − F h p ) (1 -{F_{ {\rm{hp}}}}) (1−Fhp)与当前层特征(Current-level Features) F c F_c Fc相乘以分别生成前景注意特征 F f a F_{ {\rm{fa}}} Ffa和背景注意特征 F b a F_{ {\rm{ba}}} Fba;
- 将两种类型的特征 F f a F_{ {\rm{fa}}} Ffa和 F b a F_{ {\rm{ba}}} Fba输入到两个平行的上下文探索块(CE Block)中,以执行上下文推理,分别发现假阳性干扰 F f p d F_{ {\rm{fpd}}} Ffpd和假阴性干扰 F f n d F_{ {\rm{fnd}}} Ffnd;
- 对高层特征(Higher-level Features) F h F_h Fh进行CBR并上采样 F u p = U p ( C B R ( F h ) ) {F_{up}} = {\rm{ }}Up\left( {CBR\left( { {F_h}} \right)} \right) Fup=Up(CBR(Fh)),分别进行 F r = B R ( F u p − α F f p d ) {F_r}{\rm{ }} = {\rm{ }}BR\left( { {F_{up}}{\rm{ }} - {\rm{ }}\alpha {F_{fpd}}} \right) Fr=BR(Fup−αFfpd)逐特征像素减法运算来抑制模糊的背景(即假阳性干扰)和 F r ′ = B R ( F r + β F f n d ) F_r^\prime {\rm{ }} = {\rm{ }}BR\left( { {F_r}{\rm{ }} + {\rm{ }}\beta {F_{fnd}}} \right) Fr′=BR(Fr+βFfnd)逐特征像素加法运算来增加缺失的前景(即假阴性干扰);
- 最后通过对 F r ′ F_r^\prime {\rm{ }} Fr′进行卷积获得更准确的预测图。
CBR就是卷积层、BN层和ReLU激活层的缩写;BR就是BN层和ReLU激活层的缩写; α \alpha α和 β \beta β是可训练参数。
代码位置:PFNet.py
class Focus(nn.Module):
def __init__(self, channel1, channel2):
super(Focus, self).__init__()
self.channel1 = channel1
self.channel2 = channel2
# 对higher-level features上采样保持与current-level features通道一致
self.up = nn.Sequential(nn.Conv2d(self.channel2, self.channel1, 7, 1, 3),
nn.BatchNorm2d(self.channel1), nn.ReLU(), nn.UpsamplingBilinear2d(scale_factor=2))
# 对higher-level prediction上采样,nn.Sigmoid()将所以小于0的值都当作背景
self.input_map = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2), nn.Sigmoid())
self.output_map = nn.Conv2d(self.channel1, 1, 7, 1, 3)
# CE block
self.fp = Context_Exploration_Block(self.channel1)
self.fn = Context_Exploration_Block(self.channel1)
# 可训练参数
self.alpha = nn.Parameter(torch.ones(1))
self.beta = nn.Parameter(torch.ones(1))
self.bn1 = nn.BatchNorm2d(self.channel1)
self.relu1 = nn.ReLU()
self.bn2 = nn.BatchNorm2d(self.channel1)
self.relu2 = nn.ReLU()
def forward(self, x, y, in_map):
# x; current-level features
# y: higher-level features
# in_map: higher-level prediction
# 对higher-level features上采样
up = self.up(y)
# 对higher-level prediction上采样
input_map = self.input_map(in_map)
# 获得current-level features上的前景
f_feature = x * input_map
# 获得current-level features上的背景
b_feature = x * (1 - input_map)
# 前景
fp = self.fp(f_feature)
# 背景
fn = self.fn(b_feature)
# 消除假阳性干扰
refine1 = up - (self.alpha * fp)
refine1 = self.bn1(refine1)
refine1 = self.relu1(refine1)
# 消除假阴性干扰
refine2 = refine1 + (self.beta * fn)
refine2 = self.bn2(refine2)
refine2 = self.relu2(refine2)
# 卷积精化
output_map = self.output_map(refine2)
return refine2, output_map
上下文探索块 CE Block
原论文中上下文探索块(Context Exploration,CE)的结构如下图所示:
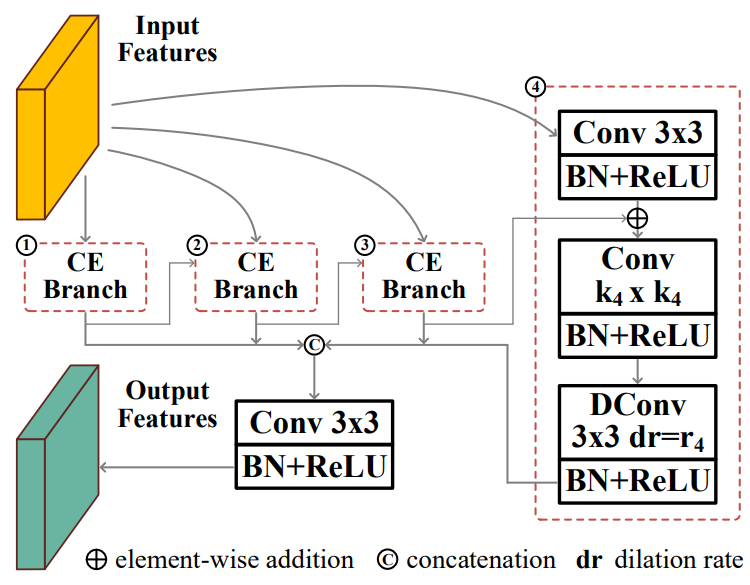
CE块由四个上下文探索分支组成,每个分支包括用于通道缩减(降维)的1×1卷积,用于局部特征提取的 k i k_i ki× k i k_i ki卷积,和用于上下文感知的膨胀率为 r i r_i ri的3×3膨胀卷积(或空洞卷积)。通过这样的设计,CE Block获得了在大范围内感知丰富上下文的能力,因此可以用于上下文推理和分开发现假阳性干扰和假阴性干扰。
原论文描述中用于降维的是3×3卷积,但是代码中是1×1卷积,博主以代码为准; k i k_i ki卷积核大小在四个分支中分别是1,3,5,7, r i r_i ri则是1,2,4,8。
博主综合论文和代码流程重新绘制了上下文探索块结构图:

- 四个分支的先后顺序按照局部特征提取层中卷积核大小排序,前一个分支会将输出特征反馈到后一个分支中以便在更大的感受野中进一步处理,后一个分支则将前一个分支的输出特征和自身降维处理的输出特征进行融合相加输出自身的特征;
- 将所有四个分支的输出连接,然后经过3×3卷积融合获得了在大范围内感知丰富上下文的能力。
代码位置:PFNet.py
class Context_Exploration_Block(nn.Module):
def __init__(self, input_channels):
super(Context_Exploration_Block, self).__init__()
self.input_channels = input_channels
self.channels_single = int(input_channels / 4)
# 1×1卷积用减少通道数降维
self.p1_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# k×k用于局部特征提取
self.p1 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# 使用空洞卷积用于上下文感知
self.p1_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=1, dilation=1),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 3, 1, 1),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=2, dilation=2),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 5, 1, 2),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=4, dilation=4),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 7, 1, 3),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=8, dilation=8),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# 综合考虑所有的特征
self.fusion = nn.Sequential(nn.Conv2d(self.input_channels, self.input_channels, 1, 1, 0),
nn.BatchNorm2d(self.input_channels), nn.ReLU())
def forward(self, x):
p1_input = self.p1_channel_reduction(x)
p1 = self.p1(p1_input)
p1_dc = self.p1_dc(p1)
# 融合前一个分支输出和自身降维输出
p2_input = self.p2_channel_reduction(x) + p1_dc
p2 = self.p2(p2_input)
p2_dc = self.p2_dc(p2)
# 融合前一个分支输出和自身降维输出
p3_input = self.p3_channel_reduction(x) + p2_dc
p3 = self.p3(p3_input)
p3_dc = self.p3_dc(p3)
# 融合前一个分支输出和自身降维输出
p4_input = self.p4_channel_reduction(x) + p3_dc
p4 = self.p4(p4_input)
p4_dc = self.p4_dc(p4)
# 四个分支融合
ce = self.fusion(torch.cat((p1_dc, p2_dc, p3_dc, p4_dc), 1))
return ce
总结
尽可能简单、详细的介绍PFNet网络中的FM聚焦模块的结构和代码。