【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁移性)转移到新的图像分布和任务,一个图像分割新的任务、模型和数据集。SAM由三个部分组成:一个强大的图像编码器(Image encoder)计算图像嵌入,一个提示编码器(Prompt encoder)嵌入提示,然后将两个信息源组合在一个轻量级掩码解码器(Mask decoder)中来预测分割掩码。本博客将讲解Mask decoder模块的深度学习网络代码。

文章目录
前言
在详细解析SAM代码之前,首要任务是成功运行SAM代码【win10下参考教程】,后续学习才有意义。本博客讲解Mask decoder模块的深度网络代码,不涉及其他功能模块代码。
MaskDecoder网络简述
SAM模型关于MaskDeco网络的配置
博主以sam_vit_b为例,详细讲解MaskDeco网络的结构。
代码位置:segment_anything/build_sam.py
def build_sam_vit_b(checkpoint=None):
return _build_sam(
# 图像编码channel
encoder_embed_dim=768,
# 主体编码器的个数
encoder_depth=12,
# attention中head的个数
encoder_num_heads=12,
# 需要将相对位置嵌入添加到注意力图的编码器( Encoder Block)
encoder_global_attn_indexes=[2, 5, 8, 11],
# 权重
checkpoint=checkpoint,
)
sam模型中Mask_decoder模块初始化
mask_decoder=MaskDecoder(
# 消除掩码歧义预测的掩码数
num_multimask_outputs=3,
# 用于预测mask的网咯transformer
transformer=TwoWayTransformer(
# 层数
depth=2,
# 输入channel
embedding_dim=prompt_embed_dim,
# MLP内部channel
mlp_dim=2048,
# attention的head数
num_heads=8,
),
# transformer的channel
transformer_dim=prompt_embed_dim,
# MLP的深度,MLP用于预测掩模质量的
iou_head_depth=3,
# MLP隐藏channel
iou_head_hidden_dim=256,
),
MaskDeco网络结构与执行流程
Mask decoder源码位置:segment_anything/modeling/mask_decoder.py
MaskDeco网络(MaskDecoder类)结构参数配置。
def __init__(
self,
*,
# transformer的channel
transformer_dim: int,
# 用于预测mask的网咯transformer
transformer: nn.Module,
# 消除掩码歧义预测的掩码数
num_multimask_outputs: int = 3,
# 激活层
activation: Type[nn.Module] = nn.GELU,
# MLP深度,MLP用于预测掩模质量的
iou_head_depth: int = 3,
# MLP隐藏channel
iou_head_hidden_dim: int = 256,
) -> None:
super().__init__()
self.transformer_dim = transformer_dim # transformer的channel
#----- transformer -----
self.transformer = transformer # 用于预测mask的网咯transformer
# ----- transformer -----
self.num_multimask_outputs = num_multimask_outputs # 消除掩码歧义预测的掩码数
self.iou_token = nn.Embedding(1, transformer_dim) # iou的taken
self.num_mask_tokens = num_multimask_outputs + 1 # mask数
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim) # mask的tokens数
#----- upscaled -----
# 4倍上采样
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
# ----- upscaled -----
# ----- MLP -----
# 对应mask数的MLP
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# ----- MLP -----
# ----- MLP -----
# 对应iou的MLP
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# ----- MLP -----
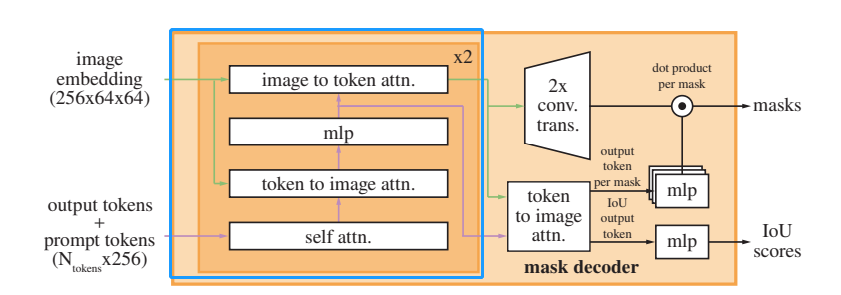
SAM模型中MaskDeco网络结构如下图所示:

原论文中Mask decoder模块各部分结构示意图:

MaskDeco网络(MaskDecoder类)在特征提取中的几个基本步骤:
- transformer:融合特征(提示信息特征与图像特征)获得粗略掩膜src
- upscaled:对粗略掩膜src上采样
- mask_MLP:全连接层组(计算加权权重,使粗掩膜src转变为掩膜mask)
- iou_MLP:全连接层组(计算掩膜mask的Score)
def forward(
self,
# image encoder 图像特征
image_embeddings: torch.Tensor,
# 位置编码
image_pe: torch.Tensor,
# 标记点和标记框的嵌入编码
sparse_prompt_embeddings: torch.Tensor,
# 输入mask的嵌入编码
dense_prompt_embeddings: torch.Tensor,
# 是否输出多个mask
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# Select the correct mask or masks for output
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
return masks, iou_pred
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# Concatenate output tokens
# 1,E and 4,E --> 5,E
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
# 5,E --> B,5,E
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
# B,5,E and B,N,E -->B,5+N,E N是点的个数(标记点和标记框的点)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# 扩展image_embeddings的B维度,因为boxes标记分割时,n个box时batchsize=batchsize*n
# Expand per-image data in batch direction to be per-mask
# B,C,H,W
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
# B,C,H,W + 1,C,H,W ---> B,C,H,W
src = src + dense_prompt_embeddings
# 1,C,H,W---> B,C,H,W
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# ----- transformer -----
# Run the transformer
# B,N,C
hs, src = self.transformer(src, pos_src, tokens)
# ----- transformer -----
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1: (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
# B,N,C-->B,C,H,W
src = src.transpose(1, 2).view(b, c, h, w)
# ----- upscaled -----
# 4倍上采样
upscaled_embedding = self.output_upscaling(src)
# ----- upscaled -----
hyper_in_list: List[torch.Tensor] = []
# ----- mlp -----
for i in range(self.num_mask_tokens):
# mask_tokens_out[:, i, :]: B,1,C
# output_hypernetworks_mlps: B,1,c
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# B,n,c
hyper_in = torch.stack(hyper_in_list, dim=1)
# ----- mlp -----
b, c, h, w = upscaled_embedding.shape
# B,n,c × B,c,N-->B,n,h,w
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# ----- mlp -----
# Generate mask quality predictions
# iou_token_out: B,1,n
iou_pred = self.iou_prediction_head(iou_token_out)
# ----- mlp -----
# masks: B,n,h,w
# iou_pred: B,1,n
return masks, iou_pred
MaskDeco网络基本步骤代码详解
transformer
MaskDeco由多个重复堆叠TwoWayAttention Block和1个Multi-Head Attention组成。
class TwoWayTransformer(nn.Module):
def __init__(
self,
# 层数
depth: int,
# 输入channel
embedding_dim: int,
# attention的head数
num_heads: int,
# MLP内部channel
mlp_dim: int,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
) -> None:
super().__init__()
self.depth = depth # 层数
self.embedding_dim = embedding_dim # 输入channel
self.num_heads = num_heads # attention的head数
self.mlp_dim = mlp_dim # MLP内部隐藏channel
self.layers = nn.ModuleList()
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim, # 输入channel
num_heads=num_heads, # attention的head数
mlp_dim=mlp_dim, # MLP中间channel
activation=activation, # 激活层
attention_downsample_rate=attention_downsample_rate, # 下采样
skip_first_layer_pe=(i == 0),
)
)
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor,
image_pe: Tensor,
point_embedding: Tensor,
) -> Tuple[Tensor, Tensor]:
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
bs, c, h, w = image_embedding.shape
# 图像编码(image_encoder的输出)
# BxHWxC=>B,N,C
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
# 图像位置编码
# BxHWxC=>B,N,C
image_pe = image_pe.flatten(2).permute(0, 2, 1)
# 标记点编码
# B,N,C
queries = point_embedding
keys = image_embedding
# -----TwoWayAttention-----
for layer in self.layers:
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding,
key_pe=image_pe,
)
# -----TwoWayAttention-----
q = queries + point_embedding
k = keys + image_pe
# -----Attention-----
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
# -----Attention-----
queries = queries + attn_out
queries = self.norm_final_attn(queries)
return queries, keys

TwoWayAttention Block
TwoWayAttention Block由LayerNorm 、Multi-Head Attention和MLP构成。
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int, # 输入channel
num_heads: int, # attention的head数
mlp_dim: int = 2048, # MLP中间channel
activation: Type[nn.Module] = nn.ReLU, # 激活层
attention_downsample_rate: int = 2, # 下采样
skip_first_layer_pe: bool = False,
) -> None:
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# queries:标记点编码相关(原始标记点编码经过一系列特征提取)
# keys:原始图像编码相关(原始图像编码经过一系列特征提取)
# query_pe:原始标记点编码
# key_pe:原始图像位置编码
# 第一轮本身queries==query_pe没比较再"残差"
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
TwoWayAttentionBlock的结构对比示意图:
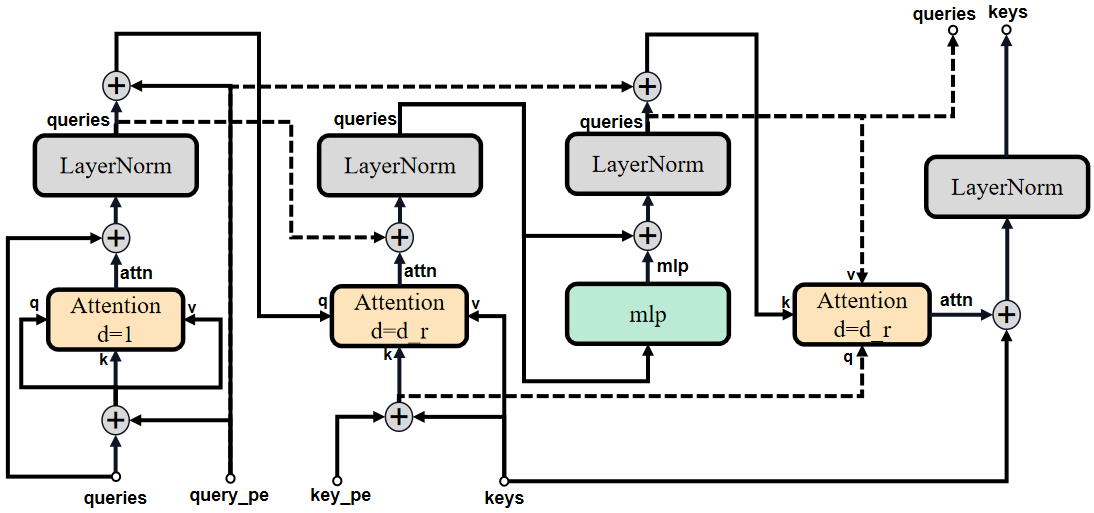
原论文中TwoWayAttention部分示意图:
个人理解:TwoWayAttentionBlock是Prompt encoder的提示信息特征与Image encoder的图像特征的融合过程,而Prompt encoder对提示信息没有过多处理,因此博主认为TwoWayAttentionBlock的目的是边对提示信息特征做进一步处理边与图像特征融合。
Attention
MaskDeco的Attention与ViT的Attention有些细微的不同:MaskDeco的Attention是3个FC层分别接受3个输入获得q、k和v,而ViT的Attention是1个FC层接受1个输入后将结果均拆分获得q、k和v。
class Attention(nn.Module):
def __init__(
self,
embedding_dim: int, # 输入channel
num_heads: int, # attention的head数
downsample_rate: int = 1, # 下采样
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."
# qkv获取
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2)
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# Input projections
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# Separate into heads
# B,N_heads,N_tokens,C_per_head
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# Attention
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # B,N_heads,N_tokens,C_per_head
# Scale
attn = attn / math.sqrt(c_per_head)
attn = torch.softmax(attn, dim=-1)
# Get output
out = attn @ v
# # B,N_tokens,C
out = self._recombine_heads(out)
out = self.out_proj(out)
return out
MaskDeco的Attention和ViT的Attention的结构对比示意图:
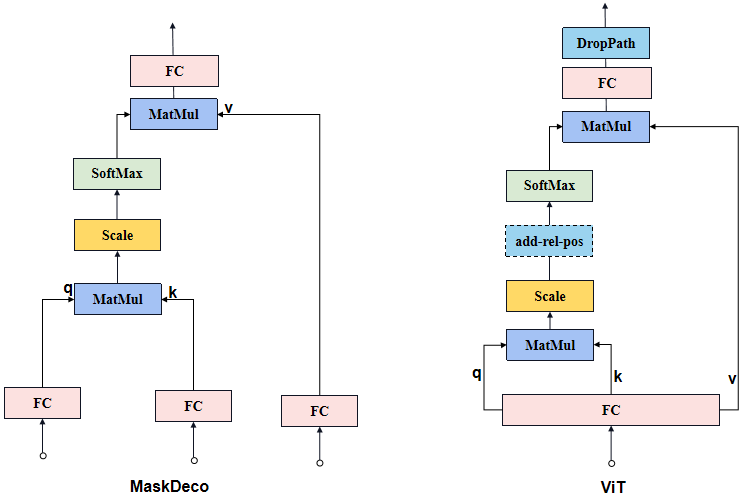
原论文中Attention部分示意图:

transformer_MLP
class MLPBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
mlp_dim: int,
act: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
self.act = act()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lin2(self.act(self.lin1(x)))
transformer中MLP的结构对比示意图:

upscaled
# 在MaskDecoder的__init__定义
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
# 在MaskDecoder的predict_masks添加位置编码
upscaled_embedding = self.output_upscaling(src)
upscaled的结构对比示意图:

mask_MLP
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
# 在MaskDecoder的__init__定义
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# 在MaskDecoder的predict_masks添加位置编码
for i in range(self.num_mask_tokens):
# mask_tokens_out[:, i, :]: B,1,C
# output_hypernetworks_mlps: B,1,c
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# B,n,c
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
# B,n,c × B,c,N-->B,n,h,w
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
iou_MLP
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
# 在MaskDecoder的__init__定义
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# 在MaskDecoder的predict_masks添加位置编码
iou_pred = self.iou_prediction_head(iou_token_out)
MaskDeco_MLP
class MLP(nn.Module):
def __init__(
self,
input_dim: int, # 输入channel
hidden_dim: int, # 中间channel
output_dim: int, # 输出channel
num_layers: int, # fc的层数
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
if self.sigmoid_output:
x = F.sigmoid(x)
return x
MaskDeco中MLP的结构对比示意图:

总结
尽可能简单、详细的介绍SAM中Mask decoder模块的MaskDeco网络的代码。