大家好,今天和各位分享一下如何使用 Pytorch 构建 ShuffleNetV2 卷积神经网络模型。
ShuffleNetV2 的原理和 TensorFlow2 实现方法可以看我下面这篇博文,建议大家一定要看一下,原理部分本文不再赘述
https://blog.csdn.net/dgvv4/article/details/123431553
1. 网络简介
ShuffleNetV2 网络模型是在 2018 年,由旷视科技和清华研究组的相关学者在 ECCV 会议上提出的。该模型证明了在同等复杂度的情况下,ShuffleNetV2 要比 ShuffleNetV1 和 MobileNetV1 更加准确。
这个网络的优势在于:(1)作为轻量级的卷积神经网络,ShuffleNetV2 相比其他轻量级模型速度稍快,准确率也更高;(2)轻量级不仅体现在速度上,还大大地减少了模型的参数量,并且通过设定每个单元的通道数便可以灵活地调整模型的复杂度。
在同一硬件实验设备下,使用相同的数据集,则得到的各模型的准确率和模型大小的平衡大小比较,如下图所示。

可以看出,作为高性能的轻量级设计的 CNN,ShuffleNetV2 网络很好地权衡了速度和准确率之间的关系。首先 ShuffleNetV2 网络内部的卷积块 Stage2,Stage3 和 Stage4 是由一个下采样单元和多个基础单元连接构成,如下图所示。
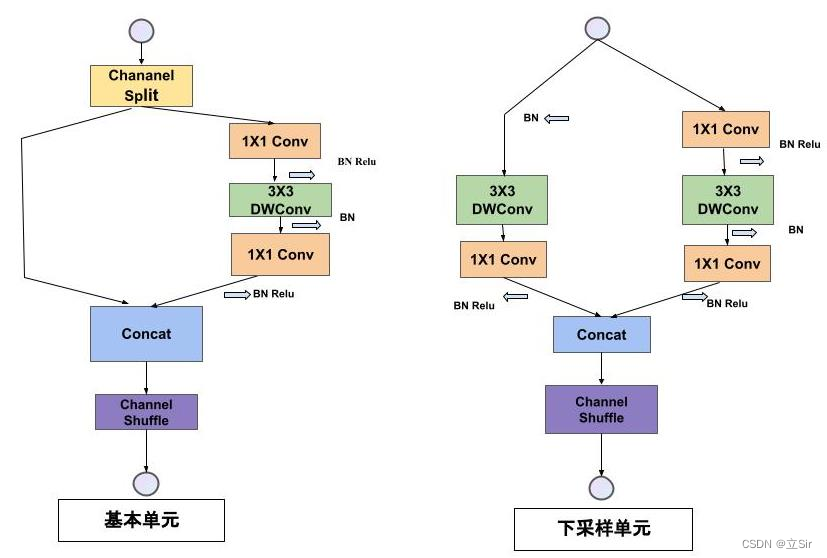
ShuffleNetV2 在基于 ShuffleNetV1 的版本上遵循了以下四个准则:
(1)图像通道宽度均衡可以使内存访问成本(MAC)最小化
对承担大部分计算开销的逐点卷积进行分析,假定输入通道数 和输出通道数
,通过网络各层时特征图的空间大小为
,那么
卷积核的计算量(FLOPs)为
,因前提是内存足够的情况下,其内存消耗
,则 B 的公式:

即仅当 时,MAC 取得最小值。因此,本模型的基本单元块和下采样单元的输入输出通道都相等。
(2)增加组卷积的同时将使得内存访问成本的增加
分析组卷积,计算量 (g 为组数),则内存消耗
。假设固定输入
和计算量 B,则 MAC 又可表示为:
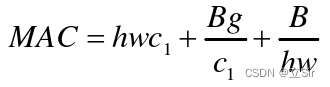
观察公式,若组数 g 增加时,内存量 MAC 也会增大。
(3)网络碎片化操作将会降低并行度
若采用如 Inception 网络那样的“多路”结构,即一个网络块中有多个卷积或池化操作。这样便容易造成网络碎片化,从而运行速度变慢,并行度降低。
(4)元素操作不可忽略
实验也发现像元素级的操作(ReLU 函数,Add 等)会带来较大的内存消耗(MAC),即使它们的运算量较小。
2. 代码实现
2.1 通道重排
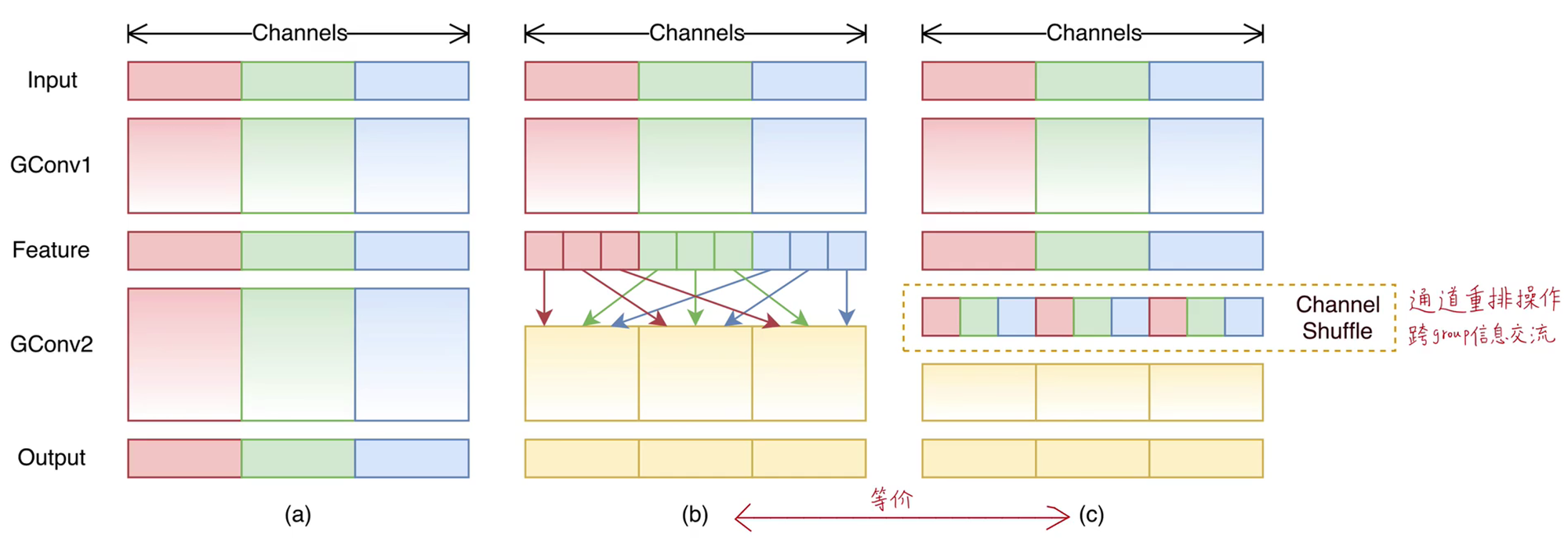
分组卷积存在一个问题,各个分组之间相互独立,没有特征融合。通道重排方法实现跨组的信息交融。
如下图(a)所示,卷积核分三组,生成特征图也是三组,每组只在内部进行信息交互,组与组之间没有任何信息交融。
如图(b, c)所示,将每个组的第一份,收集起来作为下一组;每组的第二份收集起来作为下一组....这样就实现了跨组的信息交流。
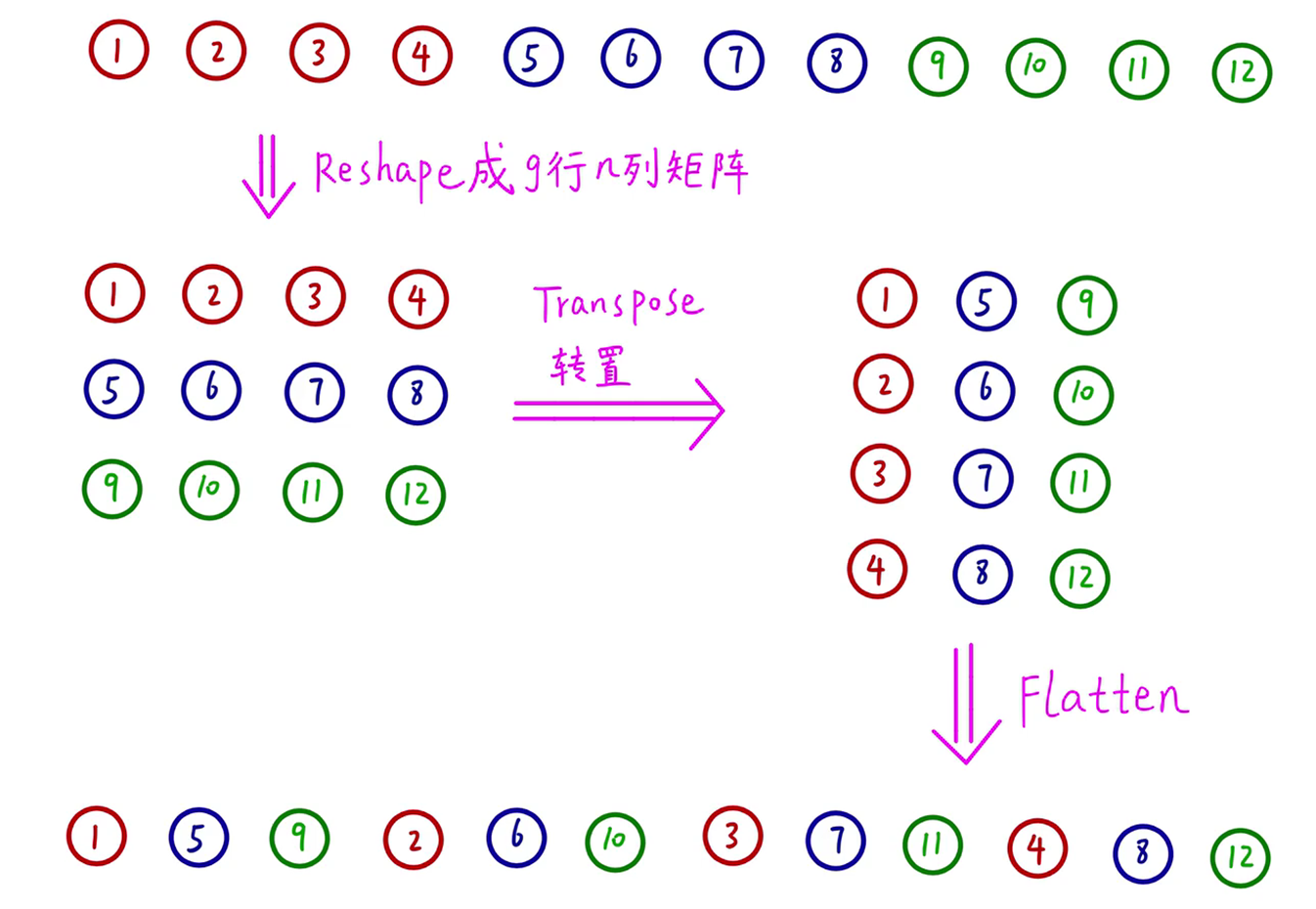
举个例子来说,如下图。分组卷积生成的三组特征图,第一组1~4;第二组5~8;第三组9~12。先将特征图重塑,为三行N列的矩形。然后进行转置,变成N行三列。最后压平,从二维tensor变成一维tensor,每一组的特征图交叉组合在一起。实现各组之间的信息交融。
代码如下
import torch
import torch.nn as nn
from torchstat import stat # 查看网络参数
# --------------------------------- #
#(1)通道重排
# --------------------------------- #
def channel_shuffle(x, groups):
# 获取输入特征图的shape=[b,c,h,w]
batch_size, num_channels, height, width = x.size()
# 均分通道,获得每个组对应的通道数
channels_per_group = num_channels // groups
# 特征图shape调整 [b,c,h,w]==>[b,g,c_g,h,w]
x = x.view(batch_size, groups, channels_per_group, height, width)
# 维度调整 [b,g,c_g,h,w]==>[b,c_g,g,h,w];将调整后的tensor以连续值的形式保存在内存中
x = torch.transpose(x,1,2).contiguous()
# 将调整后的通道拼接回去 [b,c_g,g,h,w]==>[b,c,h,w]
x = x.view(batch_size, -1, height, width)
# 完成通道重排
return x2.2 卷积块
卷积块分为基本模块(左图)和下采样模块(右图)
Channel Spilt 模块将输入图像的通道数平均分成两份,一份用于残差连接,一份用于特征提取。
Channel Shuffle 模块将堆叠的特征图的通道重新排序,实现各分组之间的特征融合。
在基本模块中,特征图size不变,通道数不变。在下采样模块中,特征图的长宽减半,通道数加倍。
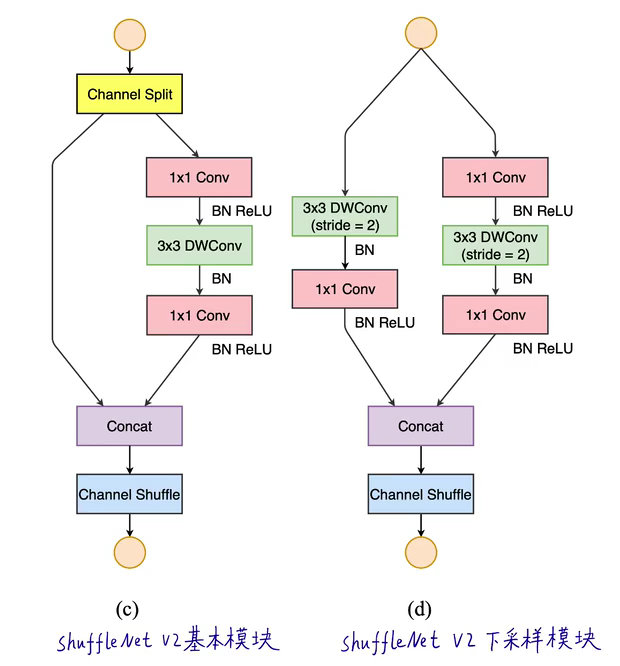
代码如下:
# ------------------------------------ #
#(2)倒残差结构
# ------------------------------------ #
class InvertedResidual(nn.Module):
# 初始化,输入特征图通道数,输出特征图通道数,DW卷积的步长=1或2
def __init__(self, input_c, output_c, stride):
super(InvertedResidual, self).__init__()
# 属性分配
self.stride = stride
# 特征图的通道数必须是2的整数倍,保证平分和拼接后的通道数不变
assert output_c % 2 == 0
# 每个分支对应的通道数
branch_features = output_c // 2
# 如果stride==1,输入特征图的通道数是输出特征图的2倍
assert (self.stride != 1) or (input_c == branch_features * 2)
# ------------------------------------------- #
# 步长为2, 下采样模块, 左分支第二个1*1卷积调整通道数,右分支第一个1*1卷积调整通道
# ------------------------------------------- #
if self.stride == 2:
# 左分支DW卷积+逐点卷积
self.branch1 = nn.Sequential(
# DW卷积,输入和输出特征图的通道数相同
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1), # 在特征图周围填充一圈0,卷积后的size不变
nn.BatchNorm2d(input_c), # 对输出特征图的每个通道做BN
# 1*1卷积调整通道数,下降为一半。有BN就不要偏置
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True) # 覆盖输入数据,节省内存
)
# 右分支1*1卷积+DW卷积+1*1卷积
self.branch2 = nn.Sequential(
# 1*1卷积下降通道数,下降一半
nn.Conv2d(in_channels=input_c, out_channels=branch_features,
kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features), # 对输出的每个通道做BN
nn.ReLU(inplace=True),
# 3*3 DW卷积,输入和输出通道数相同
self.depthwise_conv(branch_features, branch_features,
kernel_s=3, stride=self.stride, padding=1,bias=False),
nn.BatchNorm2d(branch_features),
# 1*1普通卷积
nn.Conv2d(in_channels=branch_features, out_channels=branch_features,
kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
# --------------------------------------------- #
# 步长为1, 基本模块,跟在下采样模块后面,左分支不做任何处理
# --------------------------------------------- #
else:
# 左分支
self.branch1 = nn.Sequential()
# 右分支1*1卷积+DW卷积+1*1卷积
self.branch2 = nn.Sequential(
# 1*1卷积通道数不变
nn.Conv2d(in_channels=branch_features, out_channels=branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features), # 对输出的每个通道做BN
nn.ReLU(inplace=True),
# 3*3 DW卷积,输入和输出通道数相同
self.depthwise_conv(branch_features, branch_features,
kernel_s=3, stride=self.stride, padding=1, bias=False),
nn.BatchNorm2d(branch_features),
# 1*1普通卷积
nn.Conv2d(in_channels=branch_features, out_channels=branch_features,
kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
# ------------------------------------ #
# DW卷积
# ------------------------------------ #
def depthwise_conv(self, input_c, output_c, kernel_s,
stride=1, padding=0, bias=False):
# 深度可分离卷积,卷积核对每张通道做卷积运算
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias,
groups=input_c)
# ------------------------------------ #
# 前向传播
# ------------------------------------ #
def forward(self, x): # x代表输入特征图
# 基本单元
if self.stride == 1:
# 将输入特征图在通道维度上均分2份
x1, x2 = x.chunk(2, dim=1)
# 分别对左右分支做前向传播,通道数不变
x1 = self.branch1(x1)
x2 = self.branch2(x2)
# 将输出特征图在通道维度上堆叠,通道数还原
out = torch.cat((x1,x2), dim=1)
# 下采样模块
if self.stride == 2:
# 对输入特征图分别做左右分支的前传
x1 = self.branch1(x)
x2 = self.branch2(x)
# 将输出特征图堆叠
out = torch.cat((x1,x2), dim=1)
# 通道重排
out = channel_shuffle(out, 2)
return out2.3 主干网络
ShuffleNetV2 的网络结构如下,stage2,stage3,stage4 代表2.2小节构建的卷积块,例如,stage2 堆叠了 1 个下采样模块(stride=2)和 3 个基本模块(stride=1)。
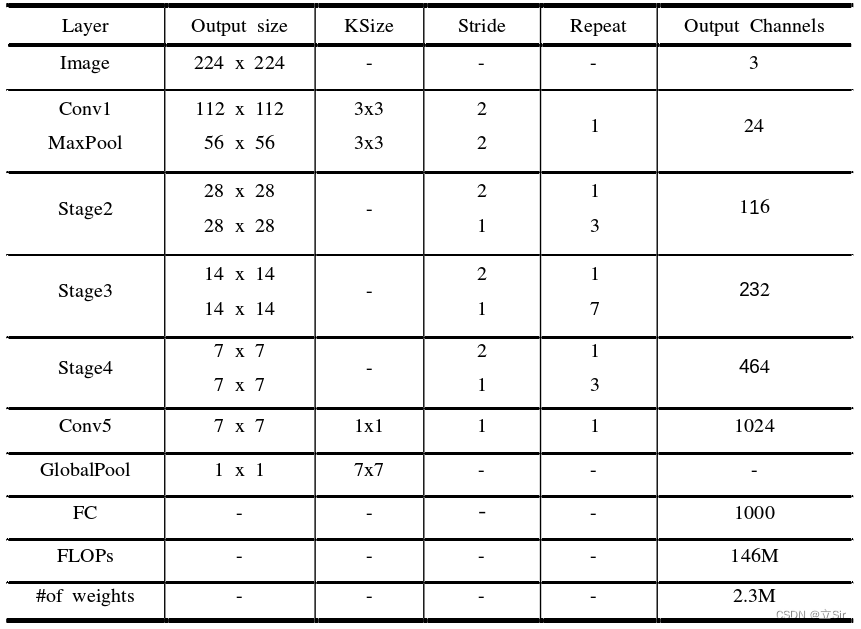
代码如下:
# ------------------------------------ #
#(3)主干网络
# ------------------------------------ #
class ShuffleNetV2(nn.Module):
# 初始化
def __init__(self,
num_classes = 1000, # 分类数
):
super(ShuffleNetV2, self).__init__()
# 输入特征图通道数RGB
input_channels = 3
# 第一个卷积块的输出特征图通道数24
output_channels = 24
# 1*1普通卷积调整通道数
self.conv1 = nn.Sequential(
# [b,3,224,224]==>[b,24,112,112]
nn.Conv2d(in_channels=input_channels, out_channels=output_channels,
kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
# 最大池化层 [b,24,112,112]==>[b,24,56,56]
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 主干的三个卷积块
inverted_block = [
# input_c, output_c, stride
# 下采样 [b,24,56,56] ==> [b,116,28,28]
InvertedResidual(24, 116, 2),
# [b,116,28,28]==>[b,116,28,28]
InvertedResidual(116, 116, 1),
InvertedResidual(116, 116, 1),
InvertedResidual(116, 116, 1),
# 下采样 [b,116,28,28]==>[b,232,14,14]
InvertedResidual(116, 232, 2),
# [b,232,14,14]==>[b,232,14,14]
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
InvertedResidual(232, 232, 1),
# 下采样 [b,232,14,14]==>[b,464,7,7]
InvertedResidual(232, 464, 2),
# [b,464,7,7]==>[b,464,7,7]
InvertedResidual(464, 464, 1),
InvertedResidual(464, 464, 1),
InvertedResidual(464, 464, 1),
]
# 将堆叠的倒残差结构以非关键字参数返回
self.inverted_block = nn.Sequential(*inverted_block)
# 1*1卷积调整通道 [b,464,7,7]==>[b,1024,7,7]
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=464, out_channels=1024,
kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True)
)
# [b,1024,1,1]==>[b,1000]
self.fc = nn.Linear(1024, num_classes)
# 前相传播
def forward(self, x): # x输入特征图
x = self.conv1(x)
x = self.maxpool(x)
x = self.inverted_block(x)
x = self.conv5(x)
# 全局池化[b,1024,7,7]==>[b,1024,1,1]
x = x.mean([2,3])
# [b,1024,1,1]==>[b,1000]
x = self.fc(x)
return x2.4 网络结构
查看网络结构和参数量,计算量。ShuffleNetV2 的参数量只有两百多万,对比 MobileNetV2 的三百多万的参数量,已经非常轻量化了。
# ---------------------------------------------------- #
#(4)查看网络结构
# ---------------------------------------------------- #
if __name__ == '__main__':
# 模型实例化
model = ShuffleNetV2(num_classes=1000)
# 构造输入层shape==[4,3,224,224]
inputs = torch.rand(4,3,224,224)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) # [4, 1000]
# 查看模型参数,不需要指定batch维度
stat(model, input_size=[3,224,224])
'''
Total params: 2,278,604
Total memory: 22.10MB
Total MAdd: 297.76MMAdd
Total Flops: 150.6MFlops
Total MemR+W: 51.57MB
'''