CS231n系列课程笔记:作为本人的笔记记录,并无商用用途
CS231n:http://cs231n.stanford.edu/
关于训练神经网络的误解:
1.ConvNets needs a lot of data to train!实际做法:利用Image data训练网络,利用本地数据微调网络
2.Infinite compute.实际:有限的计算能力
当前进度:Mini-Batch SGD(训练步骤如下)
1.随机取样
2.前向传播(forward prop),得到损失函数(loss function)
3.反向传播(back prop),求偏导计算梯度(gradient)
4.更新参数
激活函数(Activation Function)
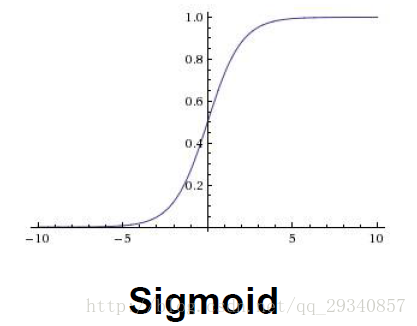
sigmoid
优点:可微
缺点:1.当参数达到饱和状态(比如w较大或w较小时,w的剃度很小,更新很慢很慢,“kill” gradient)
2.sigmoid函数的输出是在零到一之间,没有小于零的值(not zero centered),一定程度上限制了神经网络的拟合能力
3.exp()运算占用较多计算能力(相较于线性函数的计算)
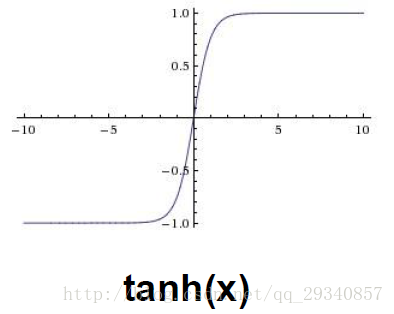
tanh
优点:1.可微
2.输出是zero centered数据
缺点:1.当参数达到饱和状态(比如w较大或w较小时,w的剃度很小,更新很慢很慢,“kill” gradient)
2.tanh运算相较于线性运算,占用了较多计算力
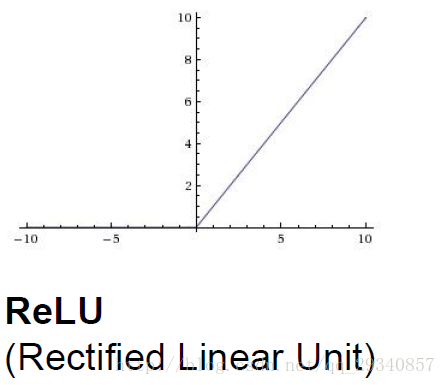
ReLU(Rectified Linear Units)
优点:1.w>0时可微,并且导数是常数
2.线性计算占用的计算力小
3.没有饱和状态,只要存在损失,可以一直更新参数(相同的梯度,梯度没有变化)
4.收敛的更快(例如:6x的导数和sigmoid的导数)
缺点:1.w一旦小于零,相应的节点永远不会被激活(kill node)
2.输出数据not zero centered
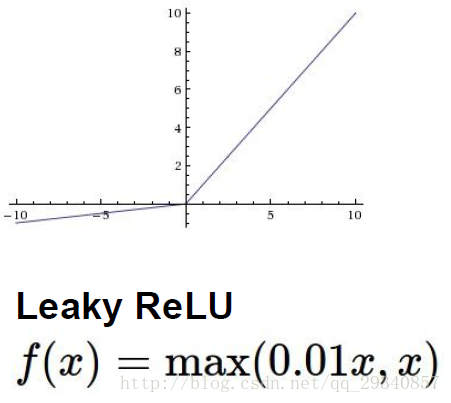
Leaky ReLU
所有ReLU的优点,同时1.不会kill node2.输出数据zero centered
maxout
优点:同Leaky ReLU
缺点:使神经网络中参数的数量翻倍
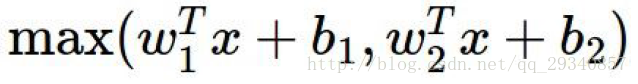
ELU(Exponential Linear Units)
优点:同Leaky ReLU
缺点:exp()计算占用较多的计算力
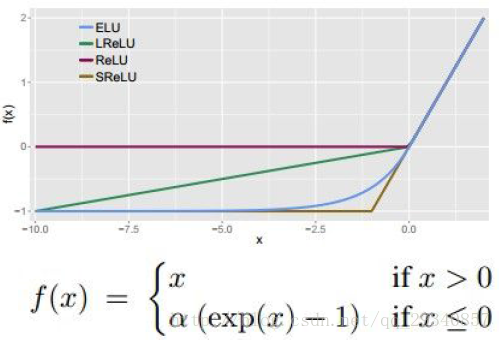
激活函数的总结:
- 使用ReLU作为激活函数,但是学习率初始化不能太大(过大的学习率会使部分神经元死亡,永远不会再被激活)
- 不要使用sigmoid作为激活函数
- 可以尝试ELU,Leaky ReLU,Maxout
- tanh的效果可能不如以上三者,但是可以尝试
数据预处理(Data Preprocessing)
1.原始数据处理(只针对图片,mean centered data)
- 提取所有通道(例如RGB三个通道)的均值,方差(e.g. AlexNet)
- 提取单个通道的均值,方差(e.g. VGGNet)
2.参数初始化(Weights Initialization)
- 高斯分布(均值为0,方差为较小值(例如:0.01))
问题:对于层数较少的神经网络作用很好,一旦层数增大,输出的激活值接近0,并且在BackProp过程中更新缓慢 - Xavier initialization 使得网络中信息流动更充分,解决上面的问题
表达式:

3.批量正则化(Batch Normalization)
步骤如下:
- 分别计算不同维度的均值,方差
- 正则化,表达式如下:
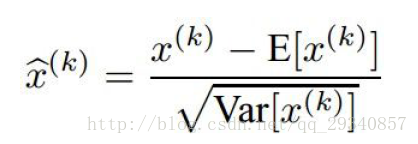
经验法则:Batch Normalization Layer通常在非线性激活(nonlinearity)函数层之前,例如tanh
4.记录观察学习过程
训练建议:在本地训练时,最好对train dataset的准确率能够达到100%准确,尽量对本地数据做到过拟合,这样分类器反而在实际中能够有更好的表现
关于学习率的技巧:
1.如果loss一直不下降,学习率过小了
2.如果loss增大,学习率过大了
5.超参数优化(Hyperparameter Optimization)
粗调参数时,训练代数设置小一点,做到既可以观察loss趋势,又可以节省时间