Neural Network 1
神经网络里的非线性是很重要且必不可少的。在全连接层之间引入非线性单元,可以让神经网络具有更强的表达能力。一个三层的神经网络可以大概写成这样子的形式,
Modeling the Neurons
- 86 billion neurons in human nervous system
- connected with
1014−1015 synapses(突触) - dendrites(树突) and axon(轴突)
- 树突是神经元自己的,较短的突触 input
- 轴突是神经元连接别的神经元的,且较长的突触 output
- fire rate of neuron
⇔ activation functionsf - 实际的神经元要复杂的多,这里只是 coarse model,如
- 有很多种不同的神经元,结构和功能都不同
- 树突不只是一个权重值,而是复杂的非线性动态系统
- 神经信号的传输时间很重要,这忽略了
- Single neuron as linear classifier
- Binary Softmax classifier (logistic regression)
- Binary SVM classifier (with max-margin hinge loss)
- Regularazation interpretation
⇔ gradual forgetting
Activation functions
sigmoid
-
σ(x)=1/(1+e−x) - 有点落伍了(fallen out of favor and it is rarely ever used)
- 原因 1:梯度饱和问题(sigmoid saturate and kill gradients),即如果神经元的激活值很大,返回的梯度几乎为零,因此反向传播的时候,也会阻断(or kill)从此处流动的梯度。此外初始化的时候,也要注意,如果梯度很大的话,也很容易造成梯度饱和。
- 原因 2:sigmoid outputs are not zero-centered,因为输出结果在
[0,1] 之间,都是整数,所以造成了某些维度一直更新正的梯度,某些则相反。就会造成 zig-zagging 形状的参数更新。不过利用 batch sgd 就会缓解这个问题,没有第一个问题严重。
-
tanh
-
tanh(x)=2σ(2x)−1 - 很明显,tanh non-linearity 虽然也有梯度饱和问题,但是起码是 zero-centered,因此实际中比 sigmoid 效果更好。
-
ReLU
- Rectified Linear Unit,即
f(x)=max(0,x) - 好处(pros)之一,加速收敛速度,据说是因为线性,非饱和(non-saturating)的形式
- 好处之二,运算(oprations)很实现都很简单,不用指数(exponentials)操作
- 坏处,很脆弱(fragile),容易死掉(die),即如果很大的梯度经过神经元,那么就会造成此神经元不会再对任何数据点有激活。不过学习率设置小一点就不会有太大的问题。【refer to stackexchange and Quora】
- Rectified Linear Unit,即
Leaky ReLU
- 不是单纯的把负数置零,而是加一个很小的 slope,比如 0.01
-
f(x)=1(x<0)(αx)+1(x≥0)(x) - 是为了修复 “dying ReLU” 问题。
- 如果
α 作为参数,即每个神经元的 slope 都不一样,可以自学习的话,就是 PReLU
- Maxout
- 每个神经元会有两个权重,激活函数为
max(wT1x+b1,wT2+b2) - 当
w1=b1=0 时,就是 ReLU - 虽然和 ReLU 一样没有梯度饱和问题,也没有 dying ReLU 问题,但是参数确实原来的两倍
- 每个神经元会有两个权重,激活函数为
实践中,用 ReLU 较多,学习率要调小一点,如果 dead units 很多的话,用 PReLU 或者 Maxout 试一下。
Neural Network architectures
- fully-connected layer or MLP(Multi-Layer Perceptrons) or ANN(Artificial Neural Network)
- 注意单层神经网络指的是没有隐藏层的网络
- neurons == units
- 输出层,即在 Softmax 之前的那一层,units 数量等于要分类的类别数,是没有激活函数的,表示对每个类别的评分。
算整个神经网络里的参数数量的时候,一般都是计算
至少带有一层隐层(因为至少得引入非线性的激活函数,如sigmoid)的神经网络,这个就是通用逼近理论(universal approximation theorem),在 1989 年就已经证明了的。Michael Nielsen 的网站也有直观的实验。【refer to intuitive explanation】
虽然经验上多层的,深度的网络结构和单个隐层的神经网络的表达能力(representational power).
Setting number of layers and their sizes
神经网络的层数和神经元的数量该怎么设置?
Capacity 指的是神经网络的表达能力
Neural Network 2
Data Preprocessing
- Mean subtraction
- 注意,对于图片的话,三个不同的通道要分别减去。
- zero-centered
- Normalization
- 把最大值和最小值放缩到
[−1,1] 之间 - 其实图片已经在
[0,255] 之间了,每个维度的权重都是一样的,如果是别的特征,就要做 normalization
- 把最大值和最小值放缩到
原图,中心化,归一化,三张图如下所示:
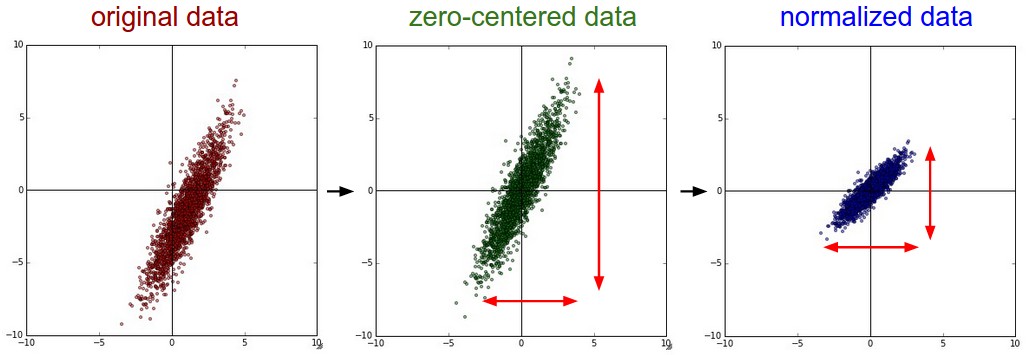
- PCA 和 whitening (白化)
首先求协方差矩阵,代码很简单,但是数学公式需要推导一下。
N, D = X.shape # 训练集放在矩阵 X 里,N 是样本集大小,D 是特征的维度
X -= np.mean(X, axis=0) # 对每个维度的数据,都求出一个均值来
cov = np.dot(X.T, X) / N # 得到 D x D 的协方差矩阵首先 np.mean(X, axis = 0) 得到的是维度为
X -= np.mean(X, axis=0) 对应的公式就是
最后一行矩阵乘法得到的协方差矩阵
由上面的解释可以看出,协方差矩阵(covariance matrix)是衡量数据不同维度之间相关度的,具体数据是由协方差来计算,因为一共有
现在话题要跑偏了,注意啦!
其实协方差矩阵不仅是对称矩阵,而且还是半正定矩阵。怎么证明呢?根据矩阵论那本书的第 31 页定理 1.25,对于一个对称矩阵
- 对称矩阵 A 是半正定矩阵
- 对称矩阵 A 的特征值全部都是非负实数
- 存在矩阵
n 阶方阵P , 使得A=PTP
显然我们的协方差矩阵就是通过
怎么证明半正定呢?考虑二次型
如果额外地满足矩阵
接着,对协方差矩阵进行 SVD 分解,得到特征向量矩阵 U,奇异值向量 S,因为协方差矩阵是对称的且半正定的,所以奇异值又是特征值的平方。
U,S,V = np.linalg.svd(cov) # 奇异值分解
Xrot = np.dot(X, U) # 得到 decorrelated data
Xrot_reduced = np.dot(X, U[:, :100]) # PCA 降维
Xwhite = Xrot / np.sqrt(S + 1e-5) # 白化,就是除以对应方向的特征值
得到的数据如下,
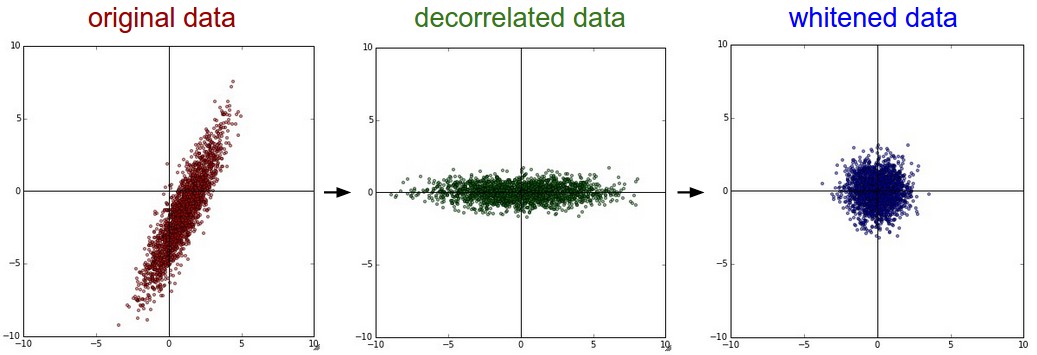
Weight Initialization 权重初始化
猜测最后的权重 W 可能一般是正数,一般是负数,所以可以初始化在零矩阵附近。但是如果简单地全部置零,会造成激活值和导数都是一样的,所以参数更新也一样。可以有下面的几种初始化方法,
W = 0.01 * np.random.randn(D, H)
W = np.random.randn(n) / sqrt(n) # W is flatten here.
W = np.random.randn(n) * sqrt(2 / n)- 上面第一种是简单地初始化成小的高斯随机数,但是整个 W 的方差,会随着输入的个数增大而增大。
- 上面第二种就是除以一个和 n 相关的数,做矫正(Calibrating the variance),但是为啥要这样子做呢?
- 上面第三种是针对 ReLU 的初始化方法。[refer to Kaiming He, et.]
- 然而初始化时,梯度也不能太小,否则的话开始时学习会很慢。
- 如果加了 Batch Normalization 的话,激活值都会被强迫乘以一个高斯分布,感觉也没啥用啊,为啥书里说就可以对坏的初始化鲁棒性很好。
- 见 Batch Normalization 的论文
Regularization 正则化
-
L2 正则化比较常用,一般得到的权重会比较分散(diffuse) -
L1 正则化,会引导稀疏化权重 sparse - 也可以把两个正则化都用上
- 如果不做特征选择时,不建议用
L1 - Max norm constraints 给一个上限,要求
∥w∥2<c ,注意这个和 RNN 的梯度裁剪不一样。这个是给权重加上界,那个是梯度。 - Dropout 只有 p 的概率会激活,否则会置零。加在激活函数之前或者之后都是一样的。
- 一般会用 inverted dropout,以避免在 test time 再做改动
Loss Function
- 当类别数很大时,一般都是会用 Hierarchical Softmax
- 最好把任务抽象成分类问题而非回归。
- Structured prediction 结构学习?
Neural Network 3
Sanity checks Tips/Tricks
可以先手动算一下第一个 loss,因为我们假设第一次的输出是均匀分布,所以 loss 应该是
- 可以先在小数据集上做训练,让模型过拟合,loss 变成零。
权重和梯度的比值最好在 10^3:1 左右
print np.linalg.norm(W.ravel()) / np.linalg.norm(grad.ravel()) # expect 10^3调参的时候,可以把激活函数后面的值打印出来,比如 tanh 后面应该是在 [-1, 1] 范围内的值,而不是挤在了两个端点上。
- 也可以把第一层的features可视化出来。正确的应该是平滑的,各种features,而不是很多噪点的特征。
Parameter updates
SGD 更新公式
# 1. Vanilla update
x += - learning_rate * dx
# 2. Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
# 3. Nesterov momentum
x_ahead = x + mu * v
v = mu * v - learning_rate * dx_ahead
x += v学习率的衰减(decay)
- Step decay
- 比如每 20 Epoch 衰减 10%,或者每次验证集停止降低错误率的时候,衰减学习率。
- Exponential decay
- 学习率为
α=α0e−kt 其中α0,k 是超参,t 是迭代数。
- 学习率为
- 1/t decay
-
α=α0/(1+kt) 参数同上
-
牛顿法
-
x=x−[Hf(x)]−1f(x) - BFGS,L-BFGS 就是 Limited-memory BFGS
Per-parameter adaptive learning methods
# Adagrad
cache += dx ** 2 # accumulation of gradients
x += - learning_rate * dx / (np.sqrt(cache) + eps) cache 是梯度的平方的积累,开始时梯度很大,就会造成学习率下降的很快,后面的会很慢。eps 是平滑的参数,一般取 1e-4 ~ 1e-8 左右。
# RMSprop
cache = decay_rate * cache + (1 - decay_rate) * dx ** 2
x += - learning_rate * dx / (np.sqrt(cache) + eps)RMSprop 的方法,是 Geoff Hinton 的 Coursera 上的课件提到的方法。和 Adagrad 差不多的公式,只是 cache 在积累梯度的时候,加了个 decay_rate。
# Adam
m = beta1 * m + (1 - beta1) * dx
v = beta2 * v + (1 - beta2) * (dx ** 2)
x += - learning_rate * m / (np.sqrt(v) + eps)Adam 的方法和 RMSprop 差不多,只是给梯度也加了动量。一般取 eps = 1e-8, beta1 = 0.9, beta2 = 0.999,一般推荐这种方法做默认的优化方法,而 SGD + Nesterov Momentum 也值得一试。
Hyperparameter optimization 参数优化
Prefer random search to grid
由于一些参数在当时的问题影响不大,所以格子调参的方法其实是浪费了,而随机的参数搜索,比格子调参效果要好一点,图解如下,
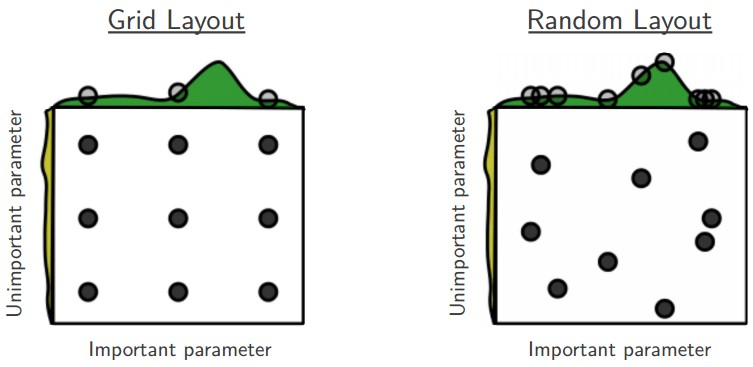
注意参数的边界值,很可能参数范围取的不正确。可以先用边界值试试,比如学习率为1和1e-6。等全部的参数组合跑了一遍以后,看看结果(所以为什么要画图),思考一下有没有收敛。
粗调参到精细调参 coarse to fine tune
- search,最好自动化,可视化,从粗调参逐渐精细调参。
- 确定边界 -> 5 epoch 跑大范围的参数取值 -> final range
- 不要忙目地瞎试
Bayesian Hyperparameter Optimization 略~
Model Ensemble 模型集成
可以考虑把不同的模型集成起来,如
- 相同的模型架构,不同的参数初始化
- cross-validation 交叉验证时的几个最好的模型
- 单个模型的不同 checkpoint
- running average of parameters during training
- 参考 Geoff Hinton 的 Dark Knowledge