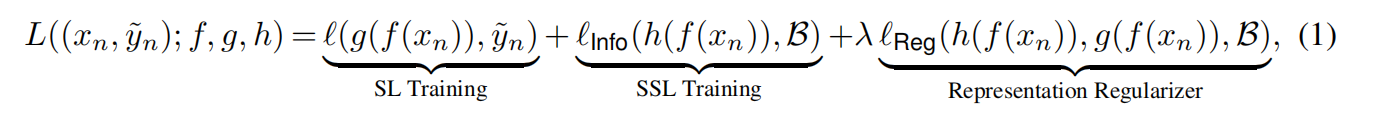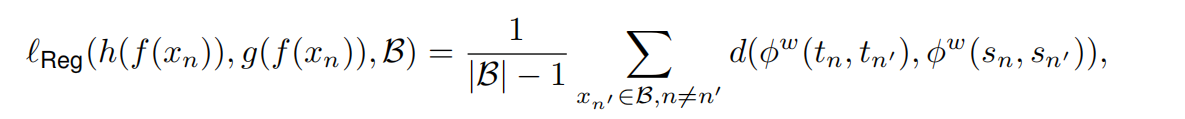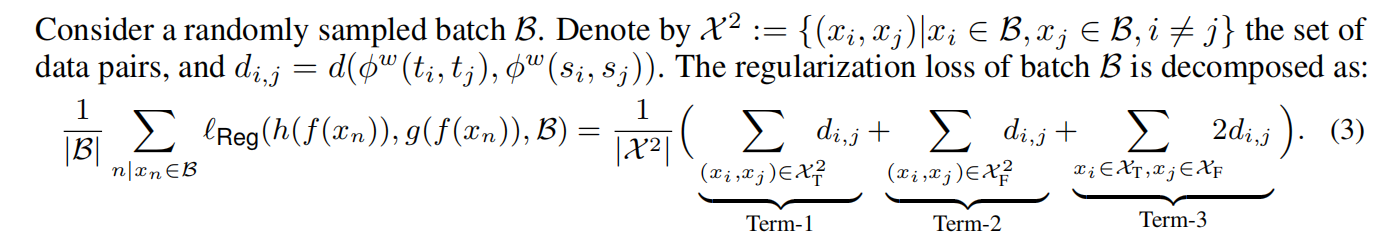在现实世界中,机器学习模型的安全部署需要检测并处理超出分布范围的输入。然而,神经网络普遍存在过度自信的问题,即对于内部和外部分布的输入都会产生异常高的置信度。本文提出了一种解决方法——对数归一化(LogitNorm),通过在训练中强制对数的常向量范数,从而缓解这个问题。我们的方法是基于分析发现,训练过程中对数的范数不断增加,导致输出过度自信。因此,LogitNorm的关键思想是在网络优化过程中分离输出范数的影响。经过LogitNorm训练的神经网络能够产生高度可区分的置信度分数,区分内部和外部分布的数据。广泛的实验表明,LogitNorm具有卓越的性能,可以将常见基准测试中的平均FPR95降低高达42.30%。
现代神经网络在开放世界中部署时,经常遇到超出分布范围(OOD)的输入,即来自网络在训练中未曾接触过的不同分布的样本,在测试时不应以高置信度进行预测。一个可靠的分类器不仅应该准确地分类已知的内部分布(ID)样本,还应将任何OOD输入标识为“未知”。这就引出了OOD检测的重要性,它确定输入是ID还是OOD,并允许模型在部署中采取预防措施。
一种朴素的解决方案是使用最大softmax概率(MSP)来进行OOD检测(Hendrycks&Gimpel,2016)。操作假设是OOD数据应该触发相对较低的softmax置信度,而不是ID数据。尽管直观,但现实情况显示出一个非平凡的困境。特别是,深度神经网络可以轻松地产生过度自信的预测,即使输入与训练数据相距甚远(Nguyen等人,2015)。这对使用softmax置信度进行OOD检测产生了重大疑问。事实上,许多先前的工作转而定义替代的OOD评分函数(Liang等人,2018; Lee等人,2018; Liu等人,2020; Sastry&Oore,2020; Sun等人,2021; Huang等人,2021; Sun等人,2022)。然而,迄今为止,社区对过度自信问题的根本原因和缓解仍有有限的理解。
- 我们引入了LogitNorm——一种简单有效的交叉熵损失替代方法,它将对数的范数影响与训练过程分离。我们展示了LogitNorm可以有效地推广到不同的网络架构,并提高不同的后续OOD检测方法的性能。
- 我们进行了广泛的评估,表明LogitNorm可以在保持ID数据分类准确性的同时,提高OOD检测和置信度校准。与交叉熵损失相比,LogitNorm在使用softmax置信度评分的常见基准测试中将FPR95降低了33.87%。
- 我们进行了消融研究,以改进我们的方法的理解。特别是,我们与替代方法(例如GODIN(Hsu等人,2020),Logit Penalty)进行对比,并展示了LogitNorm的优势。我们希望我们的见解能够激发未来的研究,进一步探索OOD检测的损失函数设计。
OOD检测是在开放世界中部署机器学习模型越来越重要的一个主题,并吸引了两个方向的大量关注。
1)一些方法旨在设计OOD检测的评分函数,例如OpenMax分数(Bendale&Boult,2016),最大softmax概率(Hendrycks&Gimpel,2016),ODIN分数(Liang等人,2018; Hsu等人,2020),基于马氏距离的分数(Lee等人,2018),基于能量的分数(Liu等人,2020; Wang等人,2021b; Morteza和Li,2022),ReAct(Sun等人,2021),GradNorm分数(Huang等人,2021)和非参数KNN分数(Sun等人,2022; Zhu等人,2022)。在这项工作中,我们首先展示了对数归一化可以显著缓解OOD数据的过度自信问题,从而提高现有评分函数在OOD检测中的性能。
2)一些工作通过训练时正则化(Lee等人,2017; Bevandi´c等人,2018; Hendrycks等人,2019; Geifman&El-Yaniv,2019; Malinin&Gales,2018; Mohseni等人,2020; Jeong&Kim,2020; Liu等人,2020; Chen等人,2021; Wei等人,2021; 2022; Ming等人,2022a)解决了OOD检测问题。例如,鼓励模型对异常值进行均匀分布(Lee等人,2017; Hendrycks等人,2019)或更高能量的预测(Liu等人,2020; Du等人,2022b; Ming等人,2022a; Du等人,2022a; Katz-Samuels等人,2022)。基于能量的正则化具有直接的理论解释,因此自然适用于OOD检测。对比学习方法也被用于OOD检测任务(Tack等人,2020; Sehwag等人,2021; Ming等人,2022b),但训练成本可能比我们的方法更高。
在这项工作中,我们专注于探索基于分类的损失函数,用于OOD检测,只需要在训练中使用内部分布数据。LogitNorm易于实现和使用,并且与标准交叉熵损失具有相同的训练方案。
Confidence calibration 置信度校准。近年来,置信度校准在各种情境下得到研究。一些研究通过事后方法解决误校准问题,例如温度缩放(Platt等,1999;Guo等,2017)和直方图分箱(Zadrozny&Elkan,2001)。此外,还提出了一些正则化方法来提高深度神经网络的校准质量,例如权重衰减(Guo等,2017),标签平滑(Szegedy等,2016;M¨uller等,2019)和焦点损失(Lin等,2017;Mukhoti等,2020)。基于符合性预测的方法(Lei等,2013)在“非典型性”过高的情况下输出空集作为预测结果。顶级标签校准旨在校准预测类标签的报告概率(Gupta&Ramdas,2022)。最近的研究(Wang等,2021a)表明,这些正则化方法使得通过事后方法进一步改善校准性能更加困难。LogitNorm损失在温度缩放下比交叉熵具有更好的校准性能。
MITIGATING MEMORIZATION OF NOISY LABELS VIAREGULARIZATION BETWEEN REPRESENTATIONS
在学习噪声标签时,设计鲁棒的损失函数是很受欢迎的,但现有的设计没有明确考虑深度神经网络(DNNs)的过拟合属性。
- 因此,应用这些损失可能仍然会在训练过程中遭受过拟合/记忆噪声标签的问题。在本文中,我们首先理论分析了记忆效应,并表明低容量模型可能在噪声数据集上表现更好。
- 然而,对于任意任务,设计最佳容量的神经网络是非常困难的。
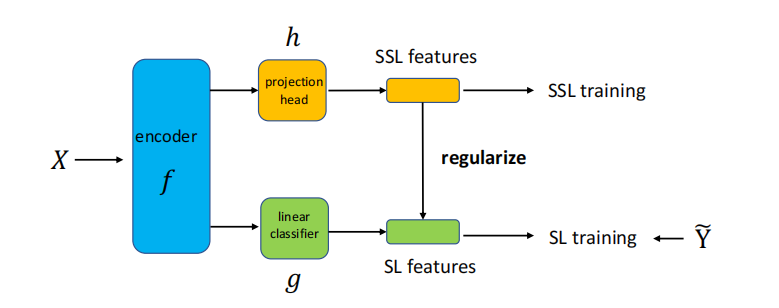
- 为了避免这种困境,我们将DNNs解耦为编码器和线性分类器,并提出通过表示正则化器限制DNNs的函数空间。特别地,我们要求两个自监督特征之间的距离与对应的两个监督模型输出之间的距离呈正相关关系。我们提出的框架易于扩展,并可以结合许多其他鲁棒损失函数进一步提高性能。广泛的实验和理论分析支持我们的论点。
Main work:
为了充分理解噪声标签学习中的记忆效应,我们将泛化误差分解为估计误差和逼近误差。通过分析这两个误差,我们发现DNN在不同的标签噪声类型上表现不同,防止过拟合的关键是控制模型复杂度。然而,为了学习噪声标签,专门设计模型结构是困难的。一个可行的解决方案是使用表示正则化器来削减一些冗余的函数空间,而不会影响最优解。因此,我们提出了一个利用表示来减轻记忆效应的统一框架。我们列出以下主要贡献:
• 我们首先在噪声标签学习的背景下,通过将泛化误差分解为估计误差和逼近误差,从理论上分析了记忆效应,并表明低容量模型可能在噪声数据集上表现更好。
• 由于为任意任务设计最佳容量的神经网络需要巨大的努力,因此我们将DNN解耦为编码器和线性分类器,并提出通过表示之间的结构信息来限制DNN的函数空间。特别地,我们要求两个自监督特征之间的距离与对应的两个监督模型输出之间的距离呈正相关关系。
• 我们通过理论分析和数值实验证明了所提出的正则化器的有效性。我们的框架可以整合许多当前的鲁棒损失,并帮助它们进一步提高性能。