原
WebRTC之noise suppression算法
更多资源见<https://www.gitbook.com/book/shichaog1/hand-book-of-asr-processing/details>
WebRTC噪声抑制核心算法在ns_core.c文件里。
噪声频谱可以使用如语音/噪声似然函数进行估计。将接收到的每帧信号和频率分量分类为噪声或语音。
算法原理
该算法的核心思想是采用维纳滤波器抑制估计出来的噪声。
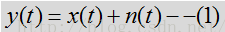
上式中x和n分别表示语音和噪声,而y表示麦克风采集到的信号。
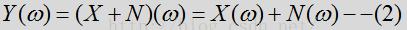
它们的频谱关系如上,从上图可以看出语音和噪声是加性且不相关的关系,对于非加性关系可以有AEC等算法对不同场景进行抑制。根据中心极限定义,一般认为噪声和语音分布服从均值为0,方差为ui的正态分布。但是也有采用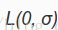
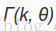
所以这里的中心思想就变成了从Y中估计噪声D,然后抑制D以得到语音,即:

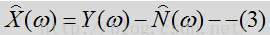
所以对噪声的估计准确性是至关重要的,噪声估计的越准得到的结果就越好,由此又多出来几种估计噪声的方法。
1. 基于VAD检测的噪声估计,VAD对Y进行检测,如果检测没有语音,则认为噪声,这是对噪声的一种估计方法。
2.基于全局幅度谱最小原理,该估计认为幅度谱最小的情况必然对应没有语音的时候。
3.还有基于矩阵奇异值分解原理估计噪声的
webRTC没有采用上述的方法,而是对似然比(VAD检测时就用了该方法)函数进行改进,将多个语音/噪声分类特征合并到一个模型中形成一个多特征综合概率密度函数,对输入的每帧频谱进行分析。其可以有效抑制风扇/办公设备等噪声。
其抑制过程如下:
对接收到的每一帧带噪语音信号,以对该帧的初始噪声估计为前提,定义语音概率函数,测量每一帧带噪信号的分类特征,使用测量出来的分类特征,计算每一帧基于多特征的语音概率,在对计算出的语音概率进行动态因子(信号分类特征和阈值参数)加权,根据计算出的每帧基于特征的语音概率,修改多帧中每一帧的语音概率函数,以及使用修改后每帧语音概率函数,更新每帧中的初始噪声(连续多帧中每一帧的分位数噪声)估计。
基于特征的语音概率函数通过使用映射函数(sigmoid/tanh又称S函数,在神经元分类算法中常用为种子函数)将每帧的信号分类特征映射到一个概率值而得出的。
分类特征包括:随时间变化的平局似然比,频谱平坦度测量以及频谱模板差异测量。频谱模板差异测量以输入信号频谱与模板噪声频谱的对比为基础。
信号分析:包括缓冲、加窗和离散傅立叶变换(DFT) 的预处理步骤
噪声估计和过滤包括:初始噪声估计、后验和先验SNR的判决引导(DD)更新、语音/噪声可能性测定,可能性测定是基于似然比(LR)因子进行的,而似然比是使用后验和先验SNR,以及语音概率密度函数(HF)模型 (如高斯、拉普拉斯算子、伽马、超高斯等),还有根据特征建模、噪声估计更新并应用维纳增益滤波器确定的概率而确定的。
信号合成:离散傅立叶逆变换、缩放和窗口合成。
初始噪声估计是以分位数噪声估计为基础。噪声估计受分位数参数控制,该参数以q表示。根据初始噪声估计步骤确定的噪声估计,仅能用作促进噪声更新/估计的后续流程的初始条件。
set_feature_extraction_parameters
设置了特征提取使用到的参数,当前WebRTC噪声抑制算法使用了LRT特征/频谱平坦度和频谱差异度三个指标,没有使用频谱熵和频谱方差这两个特征。
WebRtcNs_InitCore
NS(noise suppression)模块初始化,后面的代码按fs=8000,来分析。
- //语音数据的长度,8k/10ms的数据量是80
- self->blockLen = 80;
- //分析长度,由于是在频域分析,将长度像上取2的幂次,最小的值是128,实际上是fft的长度。
- self->anaLen = 128;
- //窗函数,采用混合汉宁平顶窗函数
- self->window = kBlocks80w128;
//语音数据的长度,8k/10ms的数据量是80 self->blockLen = 80; //分析长度,由于是在频域分析,将长度像上取2的幂次,最小的值是128,实际上是fft的长度。 self->anaLen = 128; //窗函数,采用混合汉宁平顶窗函数 self->window = kBlocks80w128;初始化FFT用到的相关存储成员
- // Initialize FFT work arrays.
- self->ip[0] = 0; // Setting this triggers initialization.
- memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
- WebRtc_rdft(self->anaLen, 1, self->dataBuf, self->ip, self->wfft);
- //是滑动分析窗,针对80点128的fft而言,每一次会保留前一帧的128-80=48个点的数据,而不是对80点简单填充0变成128点做fft。
- //但这会带来合成上的问题,通常采用加窗以防止重叠带来的突变。可以使用做fft变换一样的窗函数。但这要求窗函数保幂映射,即重叠
- //区部分窗口的平方和必须为1.
- memset(self->analyzeBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
- //dataBuf存储的是原始时域信号
- memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
- //syntBuf是谱减法,减去噪声后变换到时域的信号
- memset(self->syntBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
- // For HB processing. 这是高频部分,最多有两个band,
- memset(self->dataBufHB,
- 0,
- sizeof(float) * NUM_HIGH_BANDS_MAX * ANAL_BLOCKL_MAX);
// Initialize FFT work arrays.
self->ip[0] = 0; // Setting this triggers initialization.
memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
WebRtc_rdft(self->anaLen, 1, self->dataBuf, self->ip, self->wfft);
//是滑动分析窗,针对80点128的fft而言,每一次会保留前一帧的128-80=48个点的数据,而不是对80点简单填充0变成128点做fft。
//但这会带来合成上的问题,通常采用加窗以防止重叠带来的突变。可以使用做fft变换一样的窗函数。但这要求窗函数保幂映射,即重叠
//区部分窗口的平方和必须为1.
memset(self->analyzeBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
//dataBuf存储的是原始时域信号
memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
//syntBuf是谱减法,减去噪声后变换到时域的信号
memset(self->syntBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
// For HB processing. 这是高频部分,最多有两个band,
memset(self->dataBufHB,
0,
sizeof(float) * NUM_HIGH_BANDS_MAX * ANAL_BLOCKL_MAX);
初始化分位数估计用到的变量
- // For quantile noise estimation.
- memset(self->quantile, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- //3帧同步估计,lquantile是对数分位数。density是概率密度,计算分位数用到概率密度的。
- for (i = 0; i < SIMULT * HALF_ANAL_BLOCKL; i++) {
- self->lquantile[i] = 8.f;
- self->density[i] = 0.3f;
- }
- for (i = 0; i < SIMULT; i++) {
- //我的理解counter是一个权值,代表的每一帧对分位数估计而言其所占的比重。
- self->counter[i] =
- (int)floor((float)(END_STARTUP_LONG * (i + 1)) / (float)SIMULT);
- }
- self->updates = 0;
// For quantile noise estimation.
memset(self->quantile, 0, sizeof(float) * HALF_ANAL_BLOCKL);
//3帧同步估计,lquantile是对数分位数。density是概率密度,计算分位数用到概率密度的。
for (i = 0; i < SIMULT * HALF_ANAL_BLOCKL; i++) {
self->lquantile[i] = 8.f;
self->density[i] = 0.3f;
}
for (i = 0; i < SIMULT; i++) {
//我的理解counter是一个权值,代表的每一帧对分位数估计而言其所占的比重。
self->counter[i] =
(int)floor((float)(END_STARTUP_LONG * (i + 1)) / (float)SIMULT);
}
self->updates = 0;
维纳滤波器初始化
- for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
- self->smooth[i] = 1.f;
- }
for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
self->smooth[i] = 1.f;
}
设置抑制噪声的激进度
- // Set the aggressiveness: default.
- self->aggrMode = 0;
// Set the aggressiveness: default. self->aggrMode = 0;
噪声估计使用到的
- // Initialize variables for new method.
- self->priorSpeechProb = 0.5f; // Prior prob for speech/noise.
- // Previous analyze mag spectrum.
- memset(self->magnPrevAnalyze, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // Previous process mag spectrum.
- memset(self->magnPrevProcess, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // Current noise-spectrum.
- memset(self->noise, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // Previous noise-spectrum.
- memset(self->noisePrev, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // Conservative noise spectrum estimate.
- memset(self->magnAvgPause, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // For estimation of HB in second pass.
- memset(self->speechProb, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- // Initial average magnitude spectrum.
- memset(self->initMagnEst, 0, sizeof(float) * HALF_ANAL_BLOCKL);
- for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
- // Smooth LR (same as threshold).
- self->logLrtTimeAvg[i] = LRT_FEATURE_THR;
- }
// Initialize variables for new method.
self->priorSpeechProb = 0.5f; // Prior prob for speech/noise.
// Previous analyze mag spectrum.
memset(self->magnPrevAnalyze, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Previous process mag spectrum.
memset(self->magnPrevProcess, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Current noise-spectrum.
memset(self->noise, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Previous noise-spectrum.
memset(self->noisePrev, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Conservative noise spectrum estimate.
memset(self->magnAvgPause, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// For estimation of HB in second pass.
memset(self->speechProb, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Initial average magnitude spectrum.
memset(self->initMagnEst, 0, sizeof(float) * HALF_ANAL_BLOCKL);
for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
// Smooth LR (same as threshold).
self->logLrtTimeAvg[i] = LRT_FEATURE_THR;
}
特征量,计算噪声用到
- // Feature quantities.
- // Spectral flatness (start on threshold).
- self->featureData[0] = SF_FEATURE_THR;
- self->featureData[1] = 0.f; // Spectral entropy: not used in this version.
- self->featureData[2] = 0.f; // Spectral variance: not used in this version.
- // Average LRT factor (start on threshold).
- self->featureData[3] = LRT_FEATURE_THR;
- // Spectral template diff (start on threshold).
- self->featureData[4] = SF_FEATURE_THR;
- self->featureData[5] = 0.f; // Normalization for spectral difference.
- // Window time-average of input magnitude spectrum.
- self->featureData[6] = 0.f;
- // Histogram quantities: used to estimate/update thresholds for features.
- memset(self->histLrt, 0, sizeof(int) * HIST_PAR_EST);
- memset(self->histSpecFlat, 0, sizeof(int) * HIST_PAR_EST);
- memset(self->histSpecDiff, 0, sizeof(int) * HIST_PAR_EST);
- // Update flag for parameters:
- // 0 no update, 1 = update once, 2 = update every window.
- self->modelUpdatePars[0] = 2;
- self->modelUpdatePars[1] = 500; // Window for update.
- // Counter for update of conservative noise spectrum.
- self->modelUpdatePars[2] = 0;
- // Counter if the feature thresholds are updated during the sequence.
- self->modelUpdatePars[3] = self->modelUpdatePars[1];
// Feature quantities. // Spectral flatness (start on threshold). self->featureData[0] = SF_FEATURE_THR; self->featureData[1] = 0.f; // Spectral entropy: not used in this version. self->featureData[2] = 0.f; // Spectral variance: not used in this version. // Average LRT factor (start on threshold). self->featureData[3] = LRT_FEATURE_THR; // Spectral template diff (start on threshold). self->featureData[4] = SF_FEATURE_THR; self->featureData[5] = 0.f; // Normalization for spectral difference. // Window time-average of input magnitude spectrum. self->featureData[6] = 0.f; // Histogram quantities: used to estimate/update thresholds for features. memset(self->histLrt, 0, sizeof(int) * HIST_PAR_EST); memset(self->histSpecFlat, 0, sizeof(int) * HIST_PAR_EST); memset(self->histSpecDiff, 0, sizeof(int) * HIST_PAR_EST); // Update flag for parameters: // 0 no update, 1 = update once, 2 = update every window. self->modelUpdatePars[0] = 2; self->modelUpdatePars[1] = 500; // Window for update. // Counter for update of conservative noise spectrum. self->modelUpdatePars[2] = 0; // Counter if the feature thresholds are updated during the sequence. self->modelUpdatePars[3] = self->modelUpdatePars[1];白噪声和粉红噪声
- self->signalEnergy = 0.0;
- self->sumMagn = 0.0;
- self->whiteNoiseLevel = 0.0;
- self->pinkNoiseNumerator = 0.0;
- self->pinkNoiseExp = 0.0;
self->signalEnergy = 0.0; self->sumMagn = 0.0; self->whiteNoiseLevel = 0.0; self->pinkNoiseNumerator = 0.0; self->pinkNoiseExp = 0.0;
ComputeSpectralFlatness
频谱平坦度计算,该算法假设语音比噪声有更多的谐波。语音频谱往往会在基频(基音)和谐波中出现峰值,而噪声频谱则相对平坦。因此其作为区分噪声和语音的一个特征。
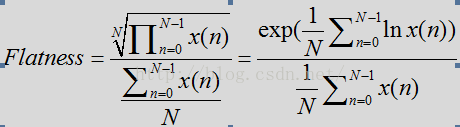
频谱度计算时N表示STFT后频率点数,B代表频率带的数量,K是频点指数,j是频带指数。每个频带包括大量的频率点。就128个频率点可分成4个频带(低带,中低频带,中高频带,高频),每个频带32个频点。对于噪声Flatness偏大且为常数,而对于语音,计算出的数量则偏下且为变量。这四个频段对于语音信号差异是比较大的,对于噪声是比较小的,根据上面的公式,如果接近于1,则是噪声,(噪声的幅度谱趋于平坦),二对于语音,上面的N次根是对乘积结果进行N次缩小,相比于分母部分,缩小的数量级是倍数的,所以语音的平坦度较小,是趋近于0的。
- // Compute spectral flatness on input spectrum.
- // |magnIn| is the magnitude spectrum.
- // Spectral flatness is returned in self->featureData[0].
- static void ComputeSpectralFlatness(NoiseSuppressionC* self,
- const float* magnIn) {
- size_t i;
- size_t shiftLP = 1; // Option to remove first bin(s) from spectral measures.
- float avgSpectralFlatnessNum, avgSpectralFlatnessDen, spectralTmp;
- // Compute spectral measures.
- // For flatness.
- avgSpectralFlatnessNum = 0.0;
- avgSpectralFlatnessDen = self->sumMagn;
- for (i = 0; i < shiftLP; i++) {
- //跳过第一个频点,即直流频点Den是denominator(分母)的缩写,avgSpectralFlatnessDen是上述公式分母计算用到的
- avgSpectralFlatnessDen -= magnIn[i];
- }
- // Compute log of ratio of the geometric to arithmetic mean: check for log(0) case.
- // 计算分子部分,numerator(分子),对log(0)是无穷小的值,所以计算时对这一情况特殊处理。
- for (i = shiftLP; i < self->magnLen; i++) {
- if (magnIn[i] > 0.0) {
- avgSpectralFlatnessNum += (float)log(magnIn[i]);
- } else {
- //TVAG是time-average的缩写,对于能量出现异常的处理。利用前一次平坦度直接取平均返回。这里平滑因子是0.3.
- self->featureData[0] -= SPECT_FL_TAVG * self->featureData[0];
- return;
- }
- }
- // Normalize.
- avgSpectralFlatnessDen = avgSpectralFlatnessDen / self->magnLen;
- avgSpectralFlatnessNum = avgSpectralFlatnessNum / self->magnLen;
- // Ratio and inverse log: check for case of log(0).
- spectralTmp = (float)exp(avgSpectralFlatnessNum) / avgSpectralFlatnessDen;
- // Time-avg update of spectral flatness feature.
- self->featureData[0] += SPECT_FL_TAVG * (spectralTmp - self->featureData[0]);
- // Done with flatness feature.
- }
// Compute spectral flatness on input spectrum.
// |magnIn| is the magnitude spectrum.
// Spectral flatness is returned in self->featureData[0].
static void ComputeSpectralFlatness(NoiseSuppressionC* self,
const float* magnIn) {
size_t i;
size_t shiftLP = 1; // Option to remove first bin(s) from spectral measures.
float avgSpectralFlatnessNum, avgSpectralFlatnessDen, spectralTmp;
// Compute spectral measures.
// For flatness.
avgSpectralFlatnessNum = 0.0;
avgSpectralFlatnessDen = self->sumMagn;
for (i = 0; i < shiftLP; i++) {
//跳过第一个频点,即直流频点Den是denominator(分母)的缩写,avgSpectralFlatnessDen是上述公式分母计算用到的
avgSpectralFlatnessDen -= magnIn[i];
}
// Compute log of ratio of the geometric to arithmetic mean: check for log(0) case.
// 计算分子部分,numerator(分子),对log(0)是无穷小的值,所以计算时对这一情况特殊处理。
for (i = shiftLP; i < self->magnLen; i++) {
if (magnIn[i] > 0.0) {
avgSpectralFlatnessNum += (float)log(magnIn[i]);
} else {
//TVAG是time-average的缩写,对于能量出现异常的处理。利用前一次平坦度直接取平均返回。这里平滑因子是0.3.
self->featureData[0] -= SPECT_FL_TAVG * self->featureData[0];
return;
}
}
// Normalize.
avgSpectralFlatnessDen = avgSpectralFlatnessDen / self->magnLen;
avgSpectralFlatnessNum = avgSpectralFlatnessNum / self->magnLen;
// Ratio and inverse log: check for case of log(0).
spectralTmp = (float)exp(avgSpectralFlatnessNum) / avgSpectralFlatnessDen;
// Time-avg update of spectral flatness feature.
self->featureData[0] += SPECT_FL_TAVG * (spectralTmp - self->featureData[0]);
// Done with flatness feature.
}
ComputeSpectralDifference
有关噪声频谱的另一个假设是,噪声频谱比语音频谱更稳定。因此,可假设噪声频谱的整体形状在任何给定阶段都倾向于保持相同。这第三个特征用于测量输入频谱与噪声频谱形状的偏差。
计算公式变成如下:
- // avgDiffNormMagn = var(magnIn) - cov(magnIn, magnAvgPause)^2 / var(magnAvgPause)
// avgDiffNormMagn = var(magnIn) - cov(magnIn, magnAvgPause)^2 / var(magnAvgPause)
ComputeSnr
根据分位数噪声估计计算前后信噪比。
后验信噪比指观测到的能量与噪声功率相关的输入功率相比的瞬态SNR:
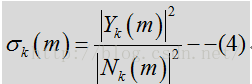
其中Y是输入含噪声的频谱,见公式1.N是噪声频谱,先验SNR是与噪声功率相关的纯净(未必是语音)信号功率的期望值,可表示为:
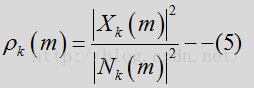
其中X是指输入的纯净信号,这里对应的指语音信号。在WebRTC实际的计算中,并没有采用平方数量级,而是采用了量级数量级。
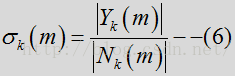
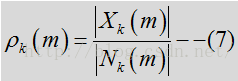
由于纯净信号是未知信号,先验SNR的估计是上一帧经估计的先验SNR和瞬态SNR 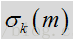
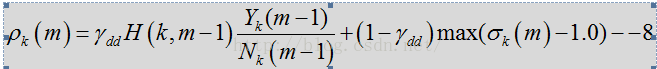
上式中H对应与代码中的smooth是上一帧的维纳滤波器,用于对瞬时SNR平滑,前一项是上一帧的先验SNR,后一项是先验SNR的瞬态估计。其通过判决应道DD进行跟新,时间平滑参数是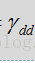
- static void ComputeSnr(const NoiseSuppressionC* self,
- const float* magn,
- const float* noise,
- float* snrLocPrior,
- float* snrLocPost) {
- size_t i;
- for (i = 0; i < self->magnLen; i++) {
- // Previous post SNR.
- // Previous estimate: based on previous frame with gain filter. 此处公式7加了平滑,对应公式8的前半部分
- float previousEstimateStsa = self->magnPrevAnalyze[i] /
- (self->noisePrev[i] + 0.0001f) * self->smooth[i];
- // Post SNR.
- snrLocPost[i] = 0.f;
- if (magn[i] > noise[i]) {
- snrLocPost[i] = magn[i] / (noise[i] + 0.0001f) - 1.f;//实际上magn中包括语音和noise,减一是将噪声减去,获得后验snr
- }
- // DD estimate is sum of two terms: current estimate and previous estimate.
- // Directed decision update of snrPrior.
- snrLocPrior[i] =
- DD_PR_SNR * previousEstimateStsa + (1.f - DD_PR_SNR) * snrLocPost[i];//此处是公式8的计算
- } // End of loop over frequencies.
- }
static void ComputeSnr(const NoiseSuppressionC* self,
const float* magn,
const float* noise,
float* snrLocPrior,
float* snrLocPost) {
size_t i;
for (i = 0; i < self->magnLen; i++) {
// Previous post SNR.
// Previous estimate: based on previous frame with gain filter. 此处公式7加了平滑,对应公式8的前半部分
float previousEstimateStsa = self->magnPrevAnalyze[i] /
(self->noisePrev[i] + 0.0001f) * self->smooth[i];
// Post SNR.
snrLocPost[i] = 0.f;
if (magn[i] > noise[i]) {
snrLocPost[i] = magn[i] / (noise[i] + 0.0001f) - 1.f;//实际上magn中包括语音和noise,减一是将噪声减去,获得后验snr
}
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of snrPrior.
snrLocPrior[i] =
DD_PR_SNR * previousEstimateStsa + (1.f - DD_PR_SNR) * snrLocPost[i];//此处是公式8的计算
} // End of loop over frequencies.
}
SpeechNoiseProb
- 该函数参数的意义。
- // |magn| is the input magnitude spectrum.输入信号幅度谱,包括信号和噪声
- // |noise| is the noise spectrum.
- 以下两个概率由ComputeSnr函数计算得到。
- // |snrLocPrior| is the prior SNR for each frequency.
- // |snrLocPost| is the post SNR for each frequency.
该函数参数的意义。 // |magn| is the input magnitude spectrum.输入信号幅度谱,包括信号和噪声 // |noise| is the noise spectrum. 以下两个概率由ComputeSnr函数计算得到。 // |snrLocPrior| is the prior SNR for each frequency. // |snrLocPost| is the post SNR for each frequency.
代码中和第一个特征相关的计算是:
- // Compute feature based on average LR factor.
- // This is the average over all frequencies of the smooth log LRT.
- logLrtTimeAvgKsum = 0.0;
- for (i = 0; i < self->magnLen; i++) {
- tmpFloat1 = 1.f + 2.f * snrLocPrior[i];
- tmpFloat2 = 2.f * snrLocPrior[i] / (tmpFloat1 + 0.0001f);
- besselTmp = (snrLocPost[i] + 1.f) * tmpFloat2;
- self->logLrtTimeAvg[i] +=
- LRT_TAVG * (besselTmp - (float)log(tmpFloat1) - self->logLrtTimeAvg[i]);
- logLrtTimeAvgKsum += self->logLrtTimeAvg[i];
- }
- logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (self->magnLen);
- self->featureData[3] = logLrtTimeAvgKsum;
// Compute feature based on average LR factor.
// This is the average over all frequencies of the smooth log LRT.
logLrtTimeAvgKsum = 0.0;
for (i = 0; i < self->magnLen; i++) {
tmpFloat1 = 1.f + 2.f * snrLocPrior[i];
tmpFloat2 = 2.f * snrLocPrior[i] / (tmpFloat1 + 0.0001f);
besselTmp = (snrLocPost[i] + 1.f) * tmpFloat2;
self->logLrtTimeAvg[i] +=
LRT_TAVG * (besselTmp - (float)log(tmpFloat1) - self->logLrtTimeAvg[i]);
logLrtTimeAvgKsum += self->logLrtTimeAvg[i];
}
logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (self->magnLen);
self->featureData[3] = logLrtTimeAvgKsum;要看懂上述代码所蕴含的物理和数学意义,必须先看动下面的推导。
计算speech/nosie的probability。该概率返回在probSpeechFinal参数中,
先推到语音/噪声概率计算方法,先来看语音/噪声的概率模型,定义语音状态为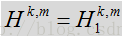
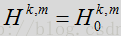
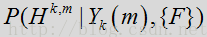
这一概率取决于观测到的额噪声输入频谱系数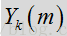
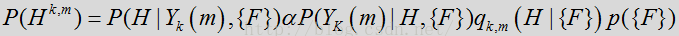
其中p({F})是以信号的特征数据为基础的先验概率,该值在下方一个或多个表达式中被设为一个常数。数量
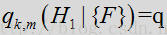
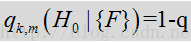
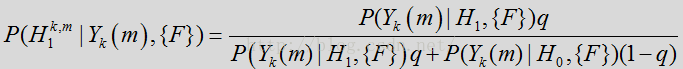
上式简写为:
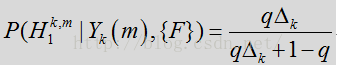
其中似然比(LR)为:
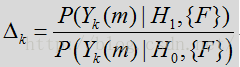
在上述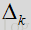
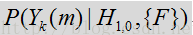
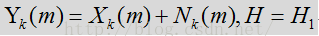
噪声状态下是:
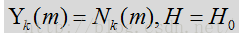
假设高斯概率密度函数使用复杂系数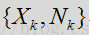
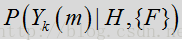
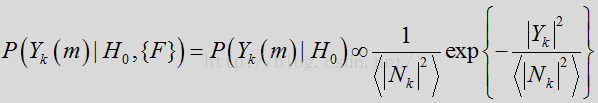
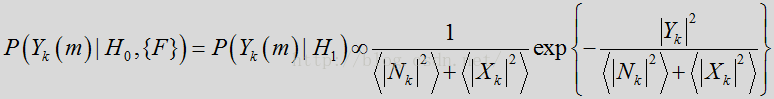
由于完全可以根据线性模型和高斯PDF假设确定概率,因此可将特征依赖从上述表达式中删除。这样,似然比
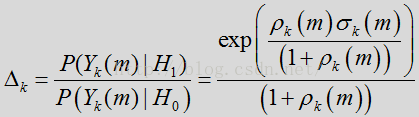
其中,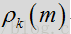
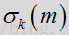
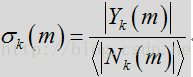
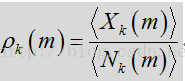
根据上述表达式,语音/噪声状态概率可通过似然比
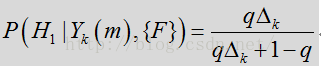
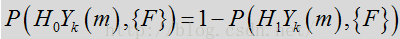
有时帧到帧之间的频变似然比因子
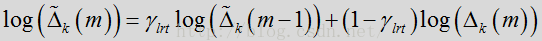
上面这个公式就是先前代码所做的事情,但是代码里又没有完全按照这里的公式推导来的。这里先用
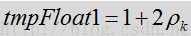
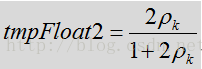
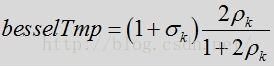
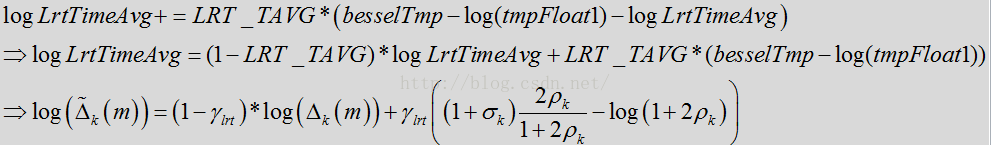
该式的最后一项是如下式子取对数所得。值得注意的是上述的代码并未完全按照公式计算得来。
经过时间平滑处理的似然比因子的几何平均数(包括所有频率)可用作对基于帧的语音/噪声分类的可靠测量结果:
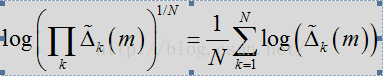
- logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (self->magnLen);
logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (self->magnLen);
在语音/噪声概率计算时,使用高斯假设作为语音PDF模型,从而获得似然比。在其它模型中,概率密度PDF模型也可以用作测量似然比的基础,包括拉普拉斯算子,伽马,超高斯。举个例子,当高斯假设可合理表示噪声时,该假设并不一定适用于语音,尤其是在较短的时帧中(如~10ms)。在这种情况下,可以使用另一种语音PDF模型,但这很可能会增加复杂性。
要在噪声估计和过滤流程中确定语音/噪声的概率,这不仅需要本地SNR(即先验SNR和瞬态SNR)的引导,还要结合从特征建模中获得的语音模型/认知内容。将语音模 型/认知内容并入到语音/噪声概率确定中,能让噪声抑制流程更好地处理和区分极不稳定的 噪声水平。如果仅依靠本地SNR,可能会造成可能性偏差。这里对包含本地SNR和语音特征/模型数据的每个帧和频率更新和适应基于特征的概率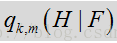
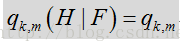
基于特征的概率的更新可采用一下模型:
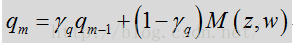
其中,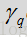
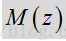
在噪声估计和过滤流程中,确定语音/噪声可能性时,会考虑语音信号的以下特征:(1)LRT均值,可以基于本地SNR得出,(2)频谱平坦度,可基于语音谐波模型得出,以及(3)频谱模板差异测量。还可以使用其它语音信号特征作为补充或替代特征。
1.LRT均值特征
经过时间平滑处理的似然比(LR)因子的几何平均数是语音/噪声状态的可靠指标:
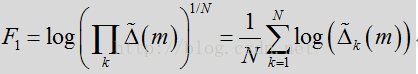
其中经过时间处理的LR因子根据前文所述表达式得出。使用LRT均值特征时,映射函数M(z)的一个示例可能是“S”型曲线函数,例如:

- // Compute indicator function: sigmoid map.
- indicator0 =
- 0.5f *
- ((float)tanh(widthPrior * (logLrtTimeAvgKsum - threshPrior0)) + 1.f);
// Compute indicator function: sigmoid map.
indicator0 =
0.5f *
((float)tanh(widthPrior * (logLrtTimeAvgKsum - threshPrior0)) + 1.f);
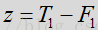
其中,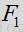
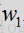
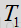
2.频谱平坦度特征
为获得频谱平坦度特征,假设语音比噪声有更多的谐波行为。然而,语音频谱往往会在基频(基音)和谐波中出现峰值,而噪声频谱则相对平坦。因此,至少在某些布置中,本地频谱平坦度测量的综合可用做区分语音和噪声的良好判断依据。
在计算频谱平坦度时,N代表频率槽的数量,B代表频率带的数量。k是频率槽指数,j是频率带指数。每个频率带将包括大量的频率槽。举例来说,128槽的频率频谱可分成4个频率带(低,中低,中高,高)。每个频率带包括32个槽。在另一个示例中,仅使用一个包括所有频率的频率带。频谱平坦度可以通过计算输入幅度谱的几何平均数与算术平均数的比值得出:
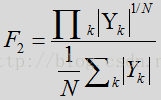
其中N表示频率带中的频率数。对于噪声,计算出的数量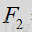
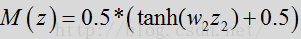
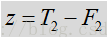
- // Compute indicator function: sigmoid map.
- indicator1 =
- 0.5f *
- ((float)tanh((float)sgnMap * widthPrior * (threshPrior1 - tmpFloat1)) +
- 1.f);
// Compute indicator function: sigmoid map.
indicator1 =
0.5f *
((float)tanh((float)sgnMap * widthPrior * (threshPrior1 - tmpFloat1)) +
1.f);
3.频谱模板差异特征
除了频谱平坦度特征的噪声相关假设之外,有关噪声频谱的另一个假设是,噪声频谱比语音频谱更温度。因此,可假设噪声频谱的整体形状在任何给定阶段都倾向与保持相同。模板频谱通过更新频谱(最初被设为零)中极有可能是噪声或语音停顿的区段来确定。该比较结果是对噪声的保守估计,其中仅对语音概率确定低于阈值(如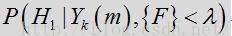
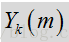
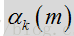
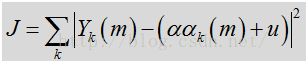
其中,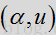
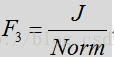
其中标准化是所有频率以及之前时帧在某些时间窗口的平均输入频谱。
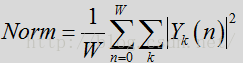
如上所述,频谱模板差异特征可测量出模板或习得噪声频谱与输入频谱的差异/偏差。至少在某些布置中,这种频谱模板差异特征可用于修正特征的语音/噪声概率
可以在频谱模板差异测量中加入佳琪期限
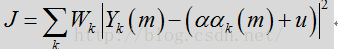
上述多个特征(LRT均值,频谱平坦度和频谱模板差异)可在语音/噪声概率的更新模板中同时出现,如下:
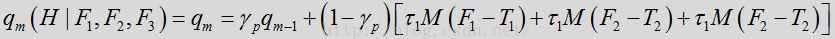
不同特征院子不同信息。这些呼吸补充,以提供一个更稳定,更具适应性的语音/噪声概率更新。
- // Combine the indicator function with the feature weights.
- indPrior = weightIndPrior0 * indicator0 + weightIndPrior1 * indicator1 +
- weightIndPrior2 * indicator2;
// Combine the indicator function with the feature weights.
indPrior = weightIndPrior0 * indicator0 + weightIndPrior1 * indicator1 +
weightIndPrior2 * indicator2;
最后把log转换到正常的概率。
- // Final speech probability: combine prior model with LR factor:.
- gainPrior = (1.f - self->priorSpeechProb) / (self->priorSpeechProb + 0.0001f);
- for (i = 0; i < self->magnLen; i++) {
- invLrt = (float)exp(-self->logLrtTimeAvg[i]);
- invLrt = (float)gainPrior * invLrt;
- probSpeechFinal[i] = 1.f / (1.f + invLrt);
- }
// Final speech probability: combine prior model with LR factor:.
gainPrior = (1.f - self->priorSpeechProb) / (self->priorSpeechProb + 0.0001f);
for (i = 0; i < self->magnLen; i++) {
invLrt = (float)exp(-self->logLrtTimeAvg[i]);
invLrt = (float)gainPrior * invLrt;
probSpeechFinal[i] = 1.f / (1.f + invLrt);
}
噪声估计 UpdateNoiseEstimate
语音/噪声概率确定后,将执行噪声估计更新,表示如下:
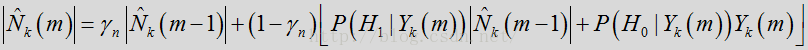
- probSpeech = self->speechProb[i];
- probNonSpeech = 1.f - probSpeech;
- // Temporary noise update:
- // Use it for speech frames if update value is less than previous.
- noiseUpdateTmp = gammaNoiseTmp * self->noisePrev[i] +
- (1.f - gammaNoiseTmp) * (probNonSpeech * magn[i] +
- probSpeech * self->noisePrev[i]);
probSpeech = self->speechProb[i];
probNonSpeech = 1.f - probSpeech;
// Temporary noise update:
// Use it for speech frames if update value is less than previous.
noiseUpdateTmp = gammaNoiseTmp * self->noisePrev[i] +
(1.f - gammaNoiseTmp) * (probNonSpeech * magn[i] +
probSpeech * self->noisePrev[i]);其中
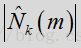 是帧/时间为m,频率槽为k时对噪声频谱量级的估计。参数
是帧/时间为m,频率槽为k时对噪声频谱量级的估计。参数
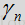 控制噪声更新的平滑度,第二个期限则使用输入频谱和上次噪声估计对噪声进行跟新,然后根据如上所述的语音/噪声概率进行加权,这可表示为:
控制噪声更新的平滑度,第二个期限则使用输入频谱和上次噪声估计对噪声进行跟新,然后根据如上所述的语音/噪声概率进行加权,这可表示为:
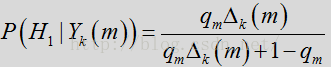
其中LR因子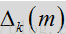
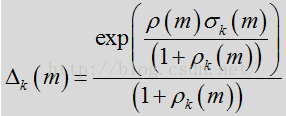
数量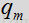
噪声估计更新流程收到语音/噪声概率和平滑参数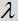
完成噪声估计更新后,噪声估计和过滤流程采用维纳增益滤波器以减少或消除来自输入帧的估计噪声量。标准维纳滤波器表达如下:、
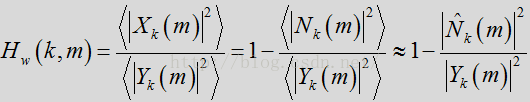
其中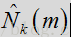
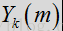
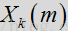
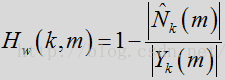
在一种或多种常规方法中,会对滤波器直接应用时间平均法,以减少任何的帧间波动。根据本发明的某些方面,维纳滤波器用先验SNR表示,而判决引导(DD)更新则用于对先验SNR进行时间平均计算。维纳滤波器可用先验SNR表示为:
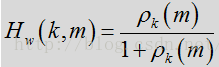
其中,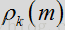
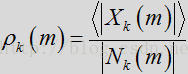
如上所述,按照DD更新估计先验SNR。该增益滤波器通过取底和过相减参数,可得出:

因为DD更新明确对先验SNR进行时间平均计算,所以不会对该增益滤波器再进行外部时间平均计算。参数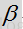
维纳滤波器应用到输入量级频谱中,以获得经抑制的信号。在噪声估计和过滤流程中采用维纳滤波器会得出:
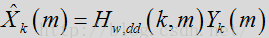
信号合成
信号合成包括各种后验噪声抑制处理,以生成包括纯净语音的输出帧。在应用维纳滤波器后,使用反向DFT将帧转换回时域。在一个或多个布置中,转换回时域可表达为:
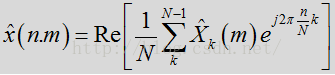
其中,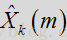
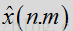
在反向DFT之后,作为信号合成流程的一部分,对经噪声抑制的信号实施能量缩放。能量缩放可用于帮助重建语音帧,且重建方式可增加经抑制后的语音的能量。例如,实施缩放时应确保只有语音帧会放大到一定程度,而噪声帧保持不变。由于噪声抑制可能降低语音信号水平,因此在缩放过程中对语音区段适当放大是有益处的。在一个布置中,根据语音帧在噪声估计和过滤流程中的能量损失,对该帧实施缩放。增益情况可通过该语音帧在噪声抑制处理前后的能量比来确定。

在当前示例中,可根据下方模型提取标度:
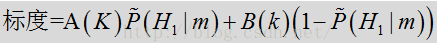
其中,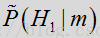
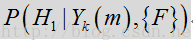
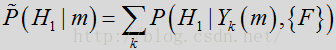
在上述标度方程中,如果概率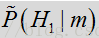
在上述标度方程中,参数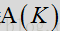
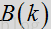
信号合成包括窗口合成操作,该操作提供估计得出的语音的最终输出帧。在一个示例中,窗口合成为:
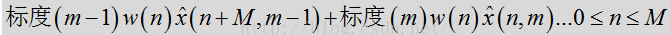
其中,标度参数由每个帧的上述标度方程式得出。
参数估计
基于特征的语音/噪声概率函数的更新模型包括应用到特征测量的多个特征加权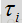
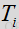
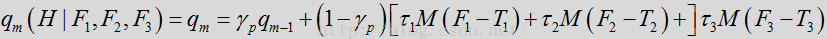
这些加权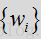

例如,如果给的输入的LRT均值特征F1不可靠.
结论,还是粘贴分析结果把
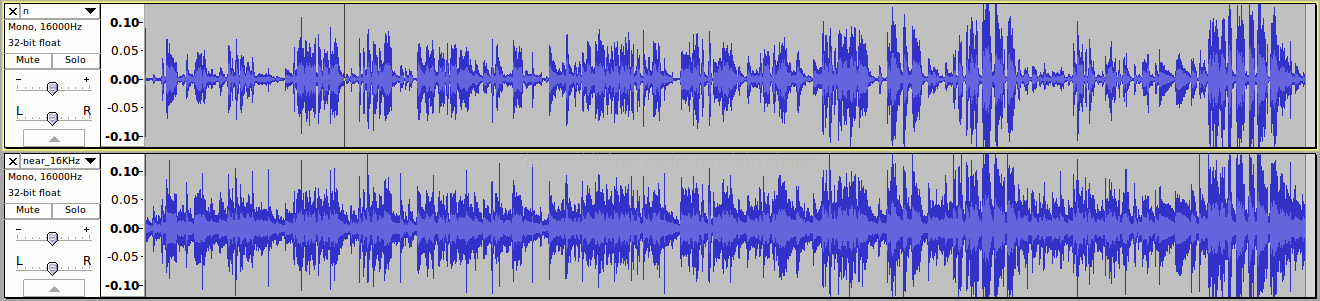
这里两张图,前一张是经过NS处理的,后一张是原始麦克风采集到的数据(实际是48KHz resample到16KHz的)。听感上声音质量确实变好了,但是不一定语音识别效果就好,这时由于语音识别系统和人耳判决准则的差异性导致的,看上面二者的频谱图
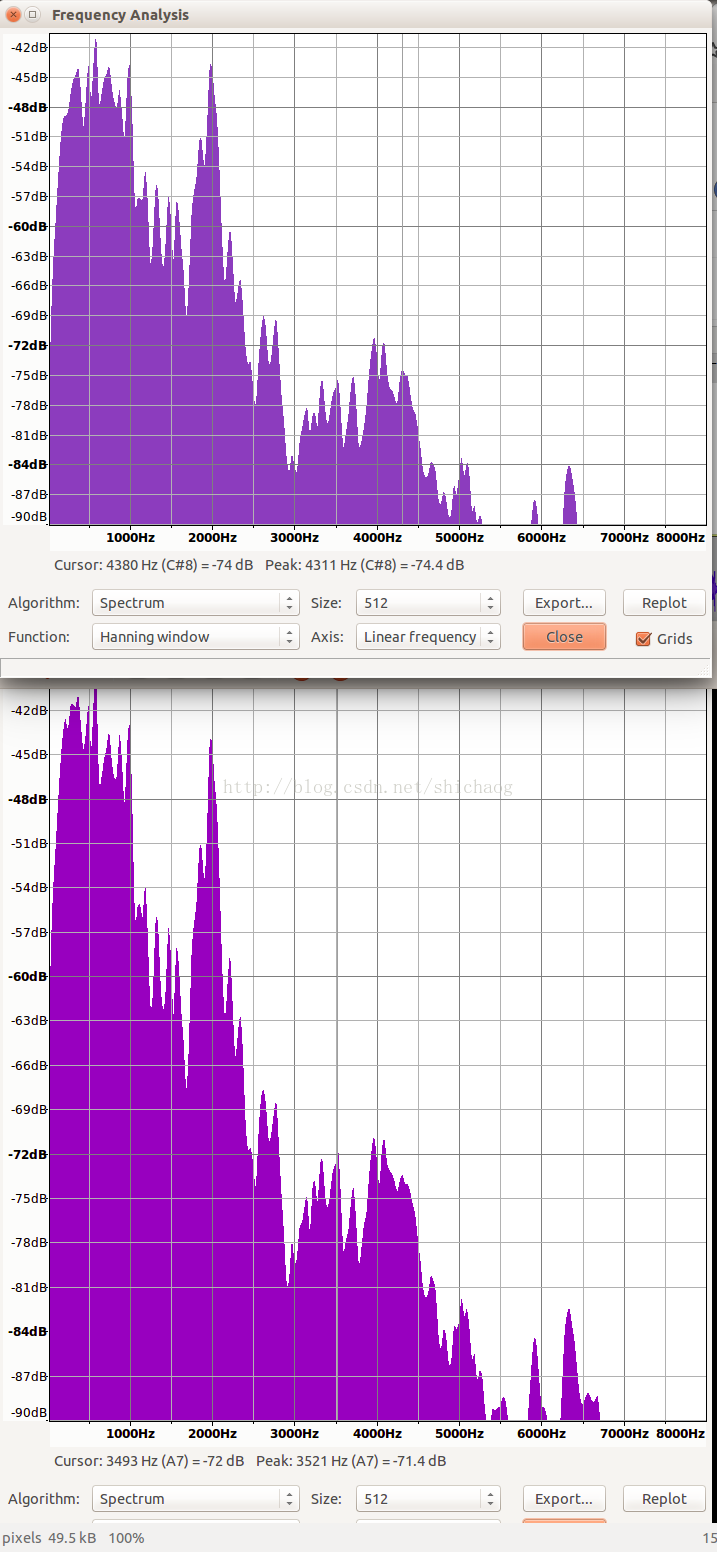
这张图上下两个之间的对应关系,细节差异自己看,语音识别采用梅尔倒谱时,上述频谱有变化,如果按有噪声的情况训练,那么噪声也可能被当成语音特征学习到,(如果语音采集在环境基本一致的情况下极其容易发生,而后处理也没有的话),这将导致识别率下降出现,但是如果噪声压制过于厉害,损伤到语音信号频谱,同样识别率也将下降;信号处理是细粒度的方法。
</div>
</div>
</article>
<div class="article-bar-bottom">
<div class="tags-box">
<span class="label">个人分类:</span>
<a class="tag-link" href="https://blog.csdn.net/shichaog/article/category/6914438" target="_blank">语音识别 </a>
</div>
</div>
<!-- !empty($pre_next_article[0]) -->
</div>
(function(){
var btnReadmore =
(window).height();
var articleBox =
(this).parent().remove();
})
}else{
btnReadmore.parent().remove();
}
}
})()