Label Noise Reduction in Entity Typing by Heterogeneous Partial-Label Embedding
已有的方法在学习后得到实体的类别有很多,但有的不需要的噪音。
如图,对特朗普的定位是person,politician,businessman,artist,actor。但在不同的语境下,其实并不能把特朗普打上这些所有的标签,其实只是其中的一部分。
其实论文主要的方法就是建立一个网络,然后创建目标方程对顶点进行嵌入学习。
总流程:
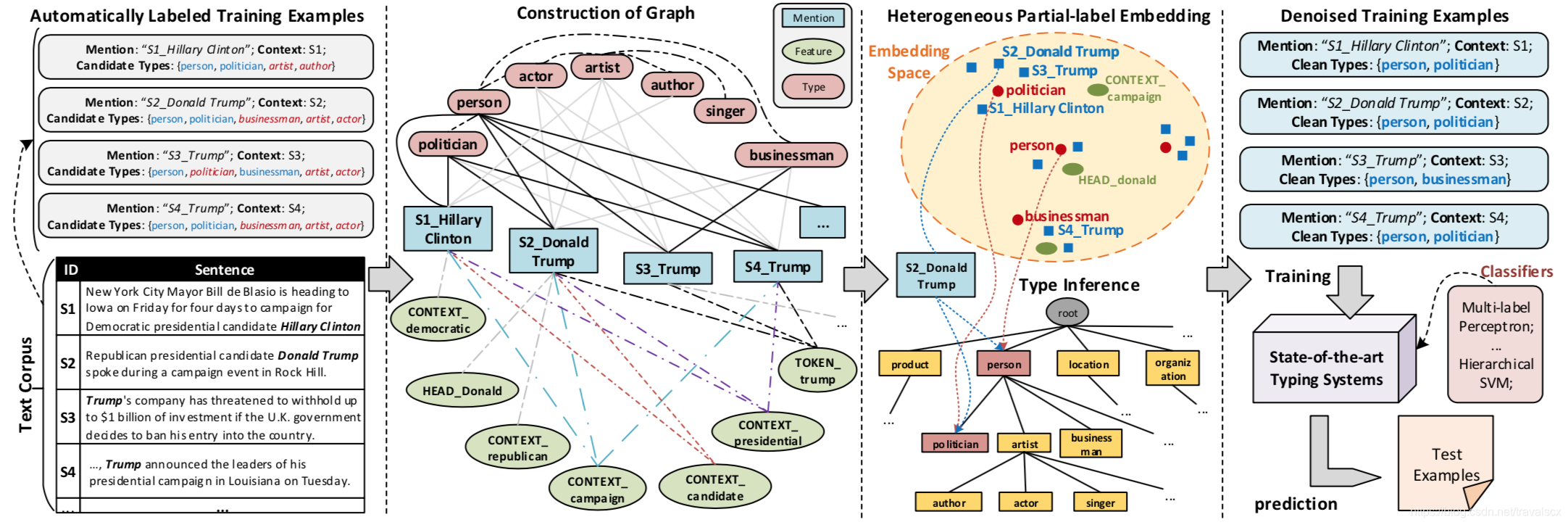
- 建立网络
*
有三部分。
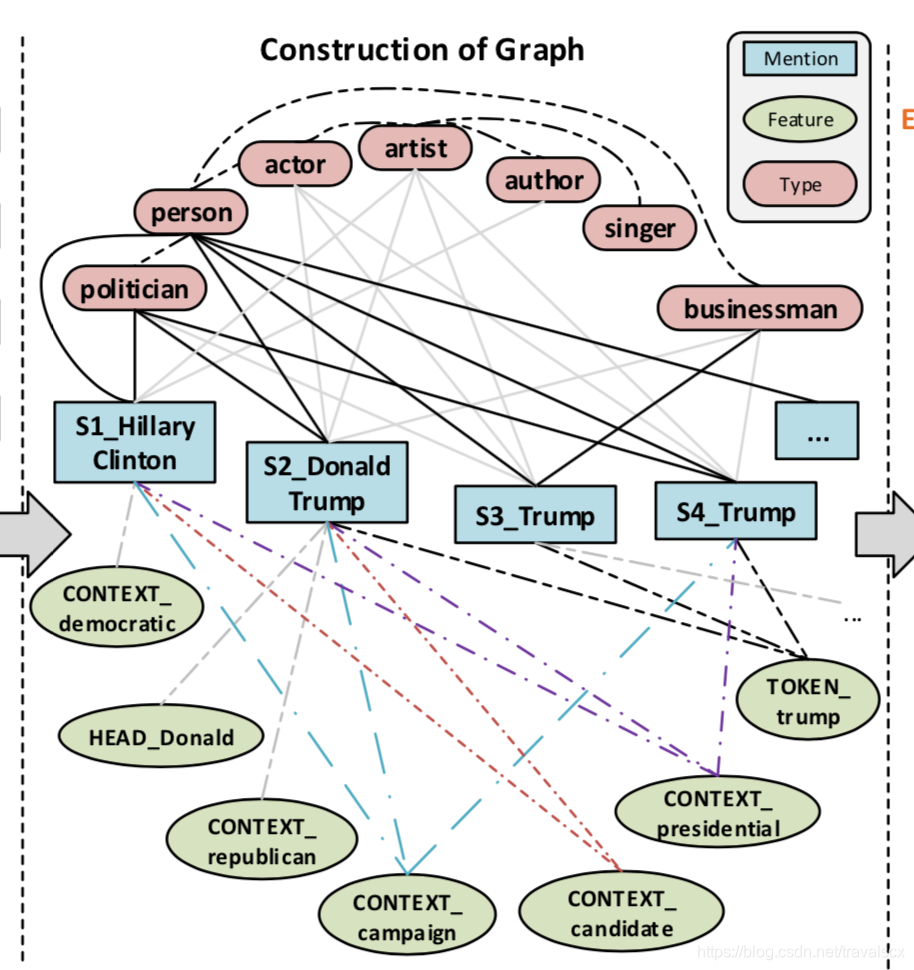
第一部分:是实体M和type y连接,也就是可以建立成一个二分图,使用已有的数据创建,比如维基百科,就有现成的数据,人物和人物的标签,这个网络就是上图的实现的部分,网络的权重是1。
第二部分:是实体M和text特征F连接,首先要把和M有关的text提取特征,文章使用了已有的其他论文提出的方法,将text分成下表很多特征,然后进行连接。图中就是带有点的线的地方。
 第三部分:对类型y之间进行连接,首先建立成树状连接,使用知识库的数据进行补充最后心成图。补充的图是两个点之间相互连接,添加上权重。权重就是两个type之间有的重叠的数据。
第三部分:对类型y之间进行连接,首先建立成树状连接,使用知识库的数据进行补充最后心成图。补充的图是两个点之间相互连接,添加上权重。权重就是两个type之间有的重叠的数据。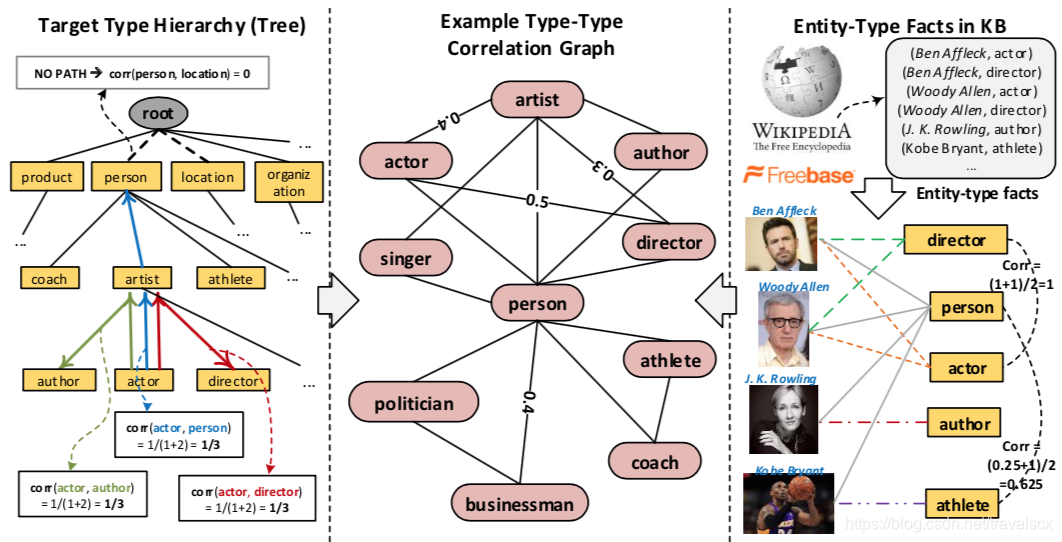
从图上可以看出,第一部分是一开始的树,第三部分是知识库中的数据,我们使用知识库中的数据,计算权重:
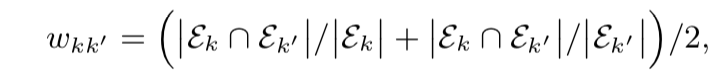
顶点k和k‘之间的权重和两者拥有的实例重叠有关。
- 对网络进行嵌入
网络的三部分分别进行目标公式的建立。
第一部分:
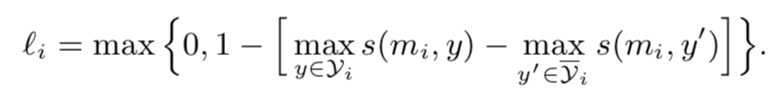
也就是建立成margin-based loss,让实体拥有的类别的点乘最大值和实体不拥有的类别的点乘最大值差别更大。
第二部分:
对实体的文本特征的嵌入目标公式,就是对概率,也就是相关的对的概率大,其实就是skip-gram的方法:
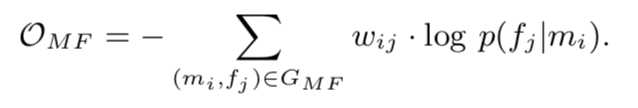
加上负样本:
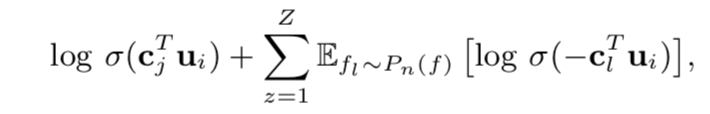
第三部分:
和第二部分一样,使用skip-gram的方法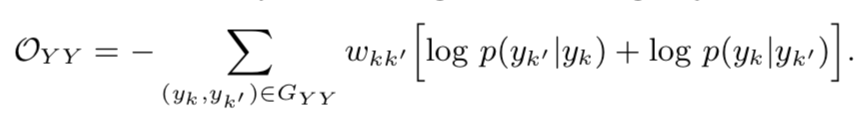
加入负样本: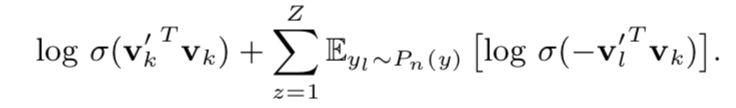
综合起来三部分:
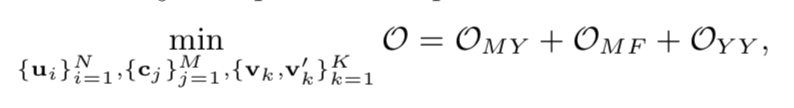
其中:
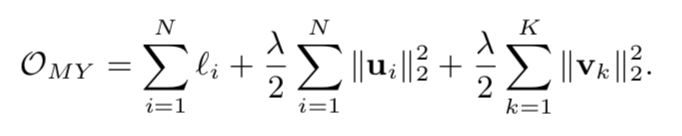
Omy后的两部分是约束正则项
- 总结:
其实就是考虑实体、type、text数据,建立成异构网络,结合skip-gram的概率目标函数和margin loss来形成神经网络进行学习。
注意论文中采用最靠近的type最为节点的最终type。