摘要
人脸识别数据集的规模越来越大,这使得我们能够训练用于人脸识别的强卷积网络。虽然已经设计了各种架构和损失函数,但我们对现有数据集固有的标签噪声的来源和后果的理解仍然有限。我们做出了以下贡献:1)我们贡献了流行人脸数据库的清洁子集,即MegaFace和MS-Celebe-1M数据集,并构建了一个新的大规模噪声控制的IMDb人脸数据集。2)利用原始数据集和清洗后的子集,我们对MegaFace和MS-Cele1m的标签噪声特性进行了剖析和分析。我们表明,要达到干净子集产生的相同精度,需要多几个数量级的样本。3)我们研究了不同类型的噪声(即标签翻转和异常值)与人脸识别模型的准确性之间的关联。4)我们研究了提高数据清洁度的方法,包括对数据标注策略对标注准确性影响的全面用户研究。IMDb人脸数据集已经在https://github.com/fwang91/IMDb-Face.发布
1引言
数据集是人脸识别发展的关键。从早期的FERET数据集[16]到最近的LFW [7]、MegaFace [8,13]和MSCeleb-1M [5],人脸识别数据集在推动新技术的发展方面发挥着主要作用。数据集不仅变得更加多样化,数据的规模也在急剧增长。例如,MS-Celebe-1M[5]包含大约1000万张10万名名人的照片,远远超过FERET [16],FERET[16]只有1199名个人的14126张照片。近年来,大规模数据集和深度学习的出现导致了人脸识别的巨大成功。
大规模数据集不可避免地会受到标签噪声的影响。这个问题是普遍存在的,因为大规模的标注良好的数据集收集起来非常昂贵和耗时。这促使研究人员求助于便宜但不完美的替代品。一种常见的方法是在搜索引擎上通过名人的名字查询他们的图像,然后用自动或半自动的方法清除标签[15,11,4]。其他方法引入了对社交照片共享网站有约束的聚类。上述方法提供了一种方便地缩放训练样本的可行方法,但是也带来了不利于模型的训练和性能的标签噪声。我们在图1中展示了一些带有标签噪声的示例。可以看出,MegaFace [13]和MSCeleb-1M [5]包含大量不正确的身份标签。一些嘈杂的标签很容易去除,而许多标签很难清洗。在MegaFace中,也有许多冗余图像(显示在最后一行)。

本文的第一个目标是通过深度卷积神经网络(CNN) [19,18,23,6,1,26]了解标签噪声的来源及其对人脸识别的影响。我们寻求这样的问题的答案:需要多少噪声样本才能达到相当于干净数据的效果?噪音和最终性能有什么关系?注释人脸身份最好的策略是什么?更好地理解上述问题将有助于我们设计更好的数据收集和清理策略,避免训练中的陷阱,并制定更强的算法来处理现实世界的问题。为了便于我们的研究,我们手动清理了两个最流行的人脸识别数据库的子集,即MegaFace [13]和MSCeleb-1M [5]。我们观察到,仅用32%的MegaFace或20%的MS-Celebe-1M清洁子集训练的模型,已经可以获得与在各自完整数据集上训练的模型相当的性能。实验表明,如果使用噪声样本,人脸识别模型训练需要多几个数量级的样本。
我们研究的第二个目标是为社区构建一个干净的人脸识别数据集。该数据集有助于训练更好的模型,并有助于进一步理解噪声和人脸识别性能之间的关系。为此,我们构建了一个名为IMDb面的干净数据集。数据集包括从IMDb网站1的电影截图和海报中收集的170万张59K名人的图像。由于数据源的性质,图像在比例、姿态、光照和遮挡方面呈现出很大的差异。我们仔细清理数据集,并通过在训练标签上注入噪声来模拟损坏。实验表明,随着标签噪声的增加,人脸识别的准确率呈非线性快速下降。特别是,我们确认了一个共同的信念,即人脸识别的性能对标签翻转(示例被错误地赋予数据集内另一个类别的标签)比对异常值(图像不属于所考虑的任何类别,但错误地具有它们的一个标签)更加敏感。我们还进行了一个有趣的实验来分析注释人脸识别数据集的不同方式的可靠性。我们发现标签的准确性与花在注释上的时间相关。这项研究有助于我们找到错误标签的来源,然后设计更好的策略来平衡注释成本和准确性。
我们希望本文能够揭示数据噪声对人脸识别任务的影响,并指出潜在的标签策略来缓解一些问题。我们向社区贡献新数据“IMDb面孔”。它可以作为一个相对干净的数据,便于今后在大规模人脸识别中对噪声的研究。正如我们将在实验中展示的那样,它还可以用作训练数据源来提高现有方法的性能。
2现有数据有多嘈杂?
我们首先介绍了人脸识别研究中常用的一些数据集,然后对它们各自的信噪比进行了近似。
2.1人脸识别数据集
表2.1总结了人脸识别研究中使用的代表性数据集。
LFW:标签人脸在野外(LFW) [7]可能是迄今为止最流行的基准人脸识别方法的数据集。该数据库由1680名名人的13000张面部图像组成。图像是通过运行维奥拉-琼斯人脸检测器从雅虎新闻收集的。受探测器的限制,LFW的大多数面孔都是正面的。尽管报告了一些标记不正确的匹配对,但数据集被认为足够干净。LFW勘误表在http://vis-www.cs.umass.edu/lfw/.提供
CelebFaces:CelebFaces[19,20]是公开的早期人脸识别训练数据库之一。它的第一版包含5436个名人和87628张图片,一年后升级到10177个身份和202599张图片。CelebFaces中的图像是从搜索引擎中收集的,并由工作人员手动清理。
VGGFace:VGGFace[15]包含2622个身份和260万张照片。每个名人从搜索引擎下载的图片超过2000张。作者将前50张图像视为阳性样本,并训练线性SVM来选择前1000张人脸。为了避免大量的手动注释,数据集被“逐块”验证,即每个身份的分级图像被显示在块中,并且注释者被要求验证块作为一个整体。在这项研究中,我们没有把重点放在VGG脸[15],因为它应该有类似的“搜索引擎偏见”的问题与微软名人-1M [5]。
CASIA-Webface:CASIA-Webface[25]中的图像是从IMDb网站上收集的。该数据集包含50万张10K名人的照片,并通过标签约束相似性聚类进行半自动清洗。作者从每个名人的主要照片和那些只包含一张脸的照片开始。然后在特征相似度和名称标签的约束下,将人脸逐渐添加到数据集中。CASIA-WebFace使用与提议的IMDb-Face数据集相同的源。然而,受特征和聚类步骤的限制,CASIA-WebFace可能无法召回许多具有挑战性的人脸。
MS-Celebe-1M:MS-Celebe-1M[5]包含10万名名人,根据他们的受欢迎程度从1M名人列表中选择。然后利用公共搜索引擎为每个名人提供大约100幅图像,从而产生大约1000万幅网络图像。出于几个原因,数据被故意不清理。具体来说,收集这种规模的数据集需要付出巨大的努力来清理数据集。也许更重要的是,以这种形式留下数据鼓励研究人员设计新的学习方法,可以自然地处理固有的噪音。
MegaFace:Kemelmacher-Slizerman等人[13]通过提出从YFCC100M数据集聚类和过滤人脸数据的算法,清理了Flickr上发布的大量图像。对于每个用户的相册,作者合并距离比平均距离的β倍更近的人脸对。包含三个以上面的簇被保留。然后,他们删除“垃圾”组,并清除每个组中潜在的异常值。共收集到672K个身份,470万张图片。MegaFace2避免了像VGG-Face [15]和MSCeleb-1M [5]那样的“搜索引擎”偏见。然而,我们发现这种基于聚类的方法引入了新的偏差。MegaFace更喜欢具有高度重复图像的小群组,例如,从同一视频捕获的人脸。受聚类基本模型的限制,MegaFace中相当多的群组包含噪声,或者有时会将同一群组中的多个人搞得一团糟
2.2信噪比的近似值
由于数据来源和清洗策略的原因,现有的大规模数据集总是包含标签噪声。在这项研究中,我们的目标是在现有的数据集轮廓噪声分布。我们的分析可能会为未来研究如何利用这些数据的分布提供线索。
由于数据集的规模,获得这些噪声的准确数量是不可行的。我们通过随机选择数据集的一个子集,并手动将它们分为三组——“正确的身份分配”、“可疑”和“错误的身份分配”,从而避开了这个难题。我们从MegaFace [13]和MS-Celebe-1M[5]中选择了2.7M图像的子集。对于CASIAWebFace [25]和CelebFaces [19,20],我们采样了30个身份来估计它们的信噪比。最终的统计数据如图2(a)所示。由于估计精确比率的困难,我们在估计过程中近似噪声数据的上限和下限。下限更乐观,认为可疑标签是干净数据。考虑到所有可疑案例都被贴上了不好的标签,上限更为悲观。我们在补充材料中提供了更多关于估计的细节。如图2(a)所示,噪声百分比随着数据规模的增加而急剧增加。考虑到数据标注的困难,这并不奇怪。值得注意的是,所提出的IMDbFace以非常高的信噪比(噪声低于全部数据的10%)推动大规模数据的包络。
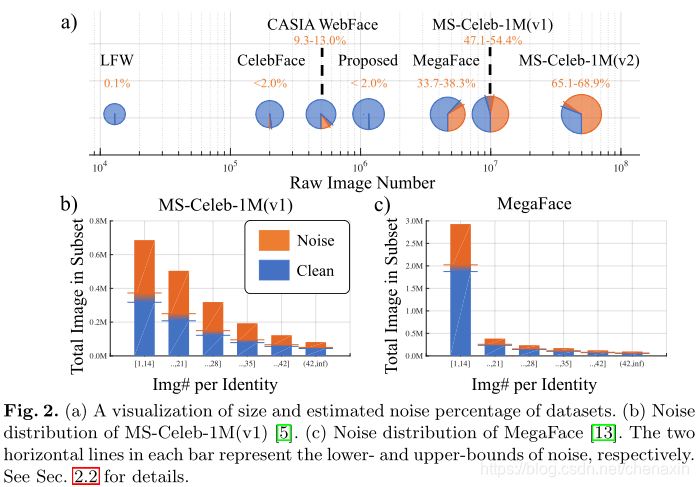
我们进一步研究了迄今为止最大的两个公共数据集,MS-Celebe-1M[5]和MegaFace [13]的噪声分布。我们首先根据图像的数量对数据集中的身份进行分类。总共建立了六个组/箱。然后,我们绘制一个直方图,显示沿着噪声下限和上限的每个仓的信噪比。如图2(b,c)所示,两个数据集都呈现出长尾分布,即大多数身份只有很少的图像。这种现象在MegaFace [13]数据集上尤其明显,因为它使用自动形成的聚类来确定身份,因此,相同的身份可能分布在不同的聚类中。与MS-Celebe-1M相比,MegaFace [13]中所有组的噪音都要少[5]。然而,我们发现MegaFace [13]干净部分的许多图像是重复的图像。秒。4.2,我们将在MegaFace和MS-Celebe-1M数据集上进行实验,以量化噪声对人脸识别任务的影响。
3构建噪声控制的人脸数据集
如前一节所示,规模超过一百万的人脸识别数据集通常具有高于30%的噪声比。建立一个大规模噪声控制的人脸数据集怎么样?它可以用来训练更好的人脸识别算法。更重要的是,可以用来进一步了解噪声与人脸识别性能的关系。为此,我们不仅寻求一种更干净、更多样的来源来收集人脸数据,而且寻求一种有效的方法来标记数据。
3.1 Celebrity Faces from IMDb
搜索引擎是我们可以快速构建大规模数据集的重要来源。广泛使用的ImageNet [3]是通过从Google Image中查询图像而构建的。大多数人脸识别数据集都是以相同的方式构建的(除了MegaFace [13])。虽然从搜索引擎查询提供了方便的数据收集,但它也引入了数据偏差。搜索引擎通常在高精度的状态下运行[2]。观察图3中查询的图像,它们往往有一个简单的背景,有足够的照明,并且对象通常处于接近正面的姿势。在一定程度上,这些数据比我们在现实中观察到的更受限制,例如视频中的人脸(IJB-A [9]和YTF [24])和自拍照片(兆脸中的数百万个干扰物)。从搜索引擎中抓取图像的另一个缺陷是召回率低。我们进行了一个简单的分析,发现对于我们查询的前200张特定姓名的照片,平均召回率仅为40%。
在这项研究中,我们将数据收集来源转向IMDb网站。IMDb更有条理。它包括每个名人档案下的各种照片,包括官方照片、生活方式照片和电影快照。我们认为,电影快照为训练一个健壮的人脸识别模型提供了必要的数据样本。那些截图很少通过查询搜索引擎来返回。此外,当我们在IMDb查询一个名字时,召回率要高得多(平均90%)。这远远高于搜索引擎的40%。IMDb网站列出了大约30万名拥有官方和画廊照片的名人。通过采集IMDb数据集,我们最终收集并清理了来自59K名人的170万张原始图像。
就这样吧 我累了