这是今年4月份读的一篇论文了,个人认为这篇文章idea非常有趣,可解释性较强,符合VQA方向的发展趋势。
本文从一个新的角度来研究VQA模型的鲁棒性:visual context
• 作者认为VQA模型过度依赖visual context,即图像中不相关的对象来进行预测。提出一种名为 SwapMix 的扰动方法,来诊断模型对visual context的依赖与评估模型的鲁棒性。• 在模型训练阶段,还能使用SwapMix进行 数据增强 。• 在MCAN和LXMERT模型上进行实验。
论文链接:https://arxiv.org/abs/2204.02285
code: https://github.com/vipulgupta1011/swapmix
背景
当前主流的VQA模型主要有两类,一类是基于注意力的模型,最具代表性的就是MCAN,另一类是大规模预训练模型,比如说LXMERT、ViLBERT。正如之前介绍GQA数据集时所说的那样,数据集是存在统计偏差和先验信息的,所以VQA模型总是会利用语言先验、统计偏差等数据集缺陷来回答问题。因此以往的鲁棒性研究工作基本都是以语言为切入点,从language context 的视角来研究模型鲁棒性,这篇文章第一次从从 visual context 来研究。
Visual Context
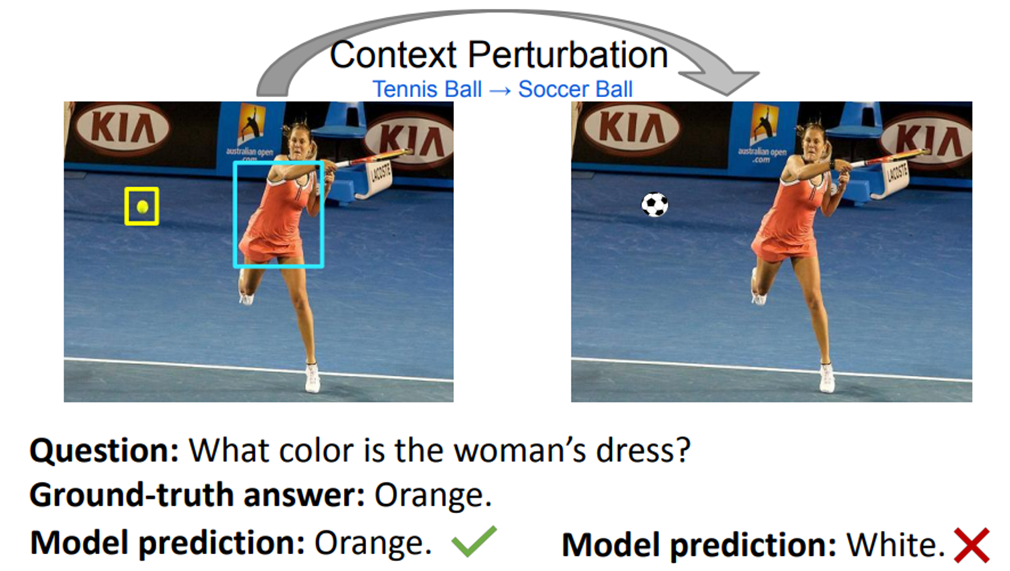
visual context 指的是图像中的背景或者是在回答问题时与推理过程无关的对象。比如说问上图女性的衣服是什么颜色,那么显然这些背景信息和这个球是与这个问题无关的上下文。在理想情况下,具有真实感知和推理能力的模型应该对这些不相关的上下文具有鲁棒性。 然而,上图反映了 VQA 模型容易受到上下文变化的影响,这表明模型过度依赖图像中不相关的上下文。所以本文提出了SwapMix的方法研究模型对视觉上下文的依赖。
SwapMix概述
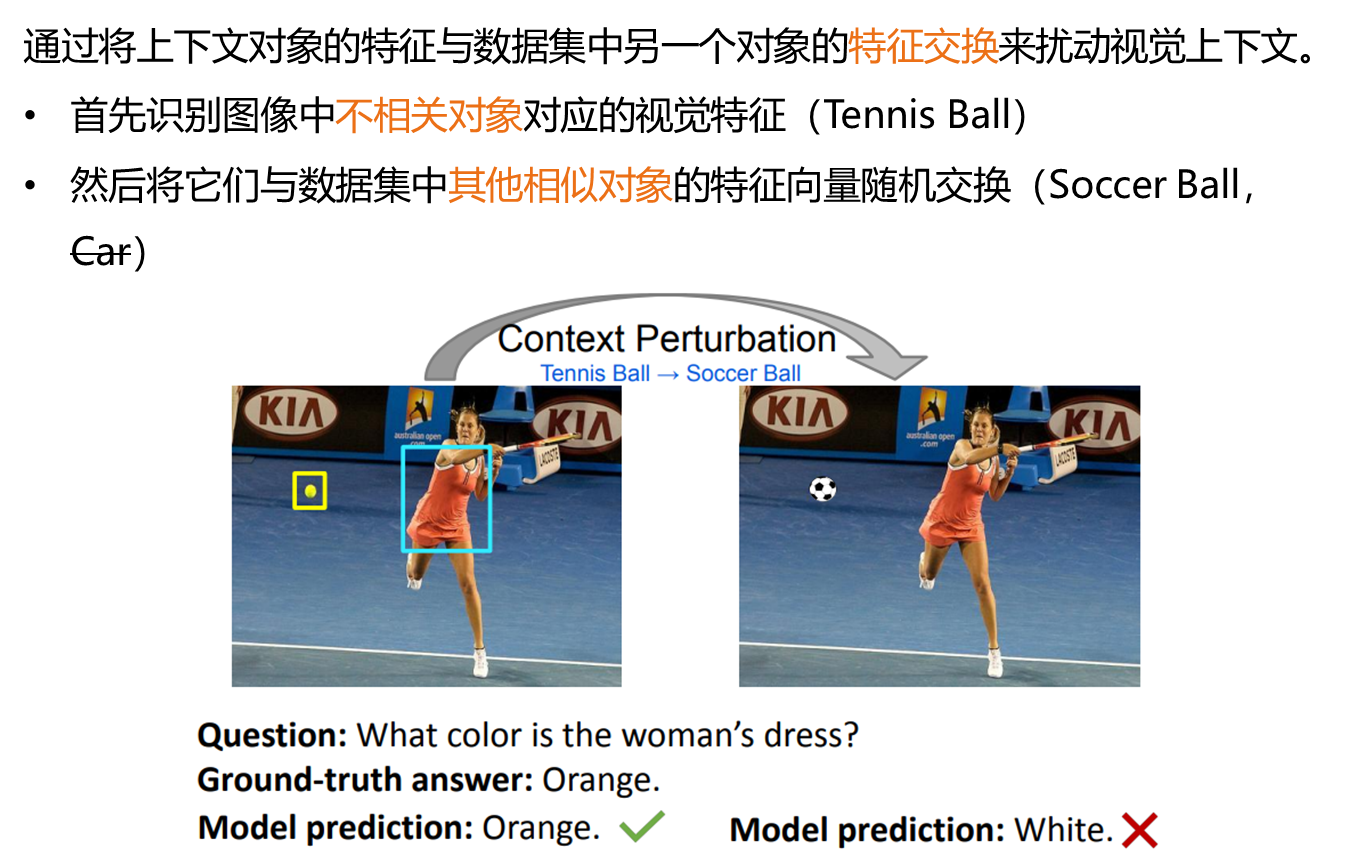
SwapMix执行的操作就是将图中的上下文对象的特征与数据集中另一个对象的特征交换来达到扰动视觉上下文的目的。所以第一步就是先要识别图像中不相关对象对应的视觉特征,第二步就是将刚刚识别出来的视觉特征与数据集中其他相似对象的特征向量交换。这里就存在两个问题,第一个是哪些对象才是不相关的对象,第二是相似的对象是什么,比如说网球可以换成是足球,但是换成一辆车就不合适了。
Method
Definition of Visual Context

然后来看具体的方法。先是第一步,提取视觉上下文,也就是找出与问题不相关的对象。对于一张图像,先用Faster RCNN提取出所有对象的特征,然后再根据GQA数据集里面的注释信息区分出与问题相关的和不相关的对象,再筛选出这些不相关对象的特征。
VQA Model with Perfect Sight

这里作者还介绍了一个具有完美视觉的VQA模型。作者猜想VQA模型的鲁棒性与视觉特征的质量有关。现成的目标检测器提取的视觉特征可能包含噪声和遗漏重要信息,这会迫使模型从不相关的视觉上下文中学习不合理的数据相关性。所有为了研究不完美视觉感知特征的影响,文中训练了一个具有完美视觉的模型作对照实验,使用的GQA数据集的场景图注释信息来得到完美视觉特征,就是对图像中所有对象的类别标签、属性信息和bounding box信息进行编码,再取平均值。
SwapMix
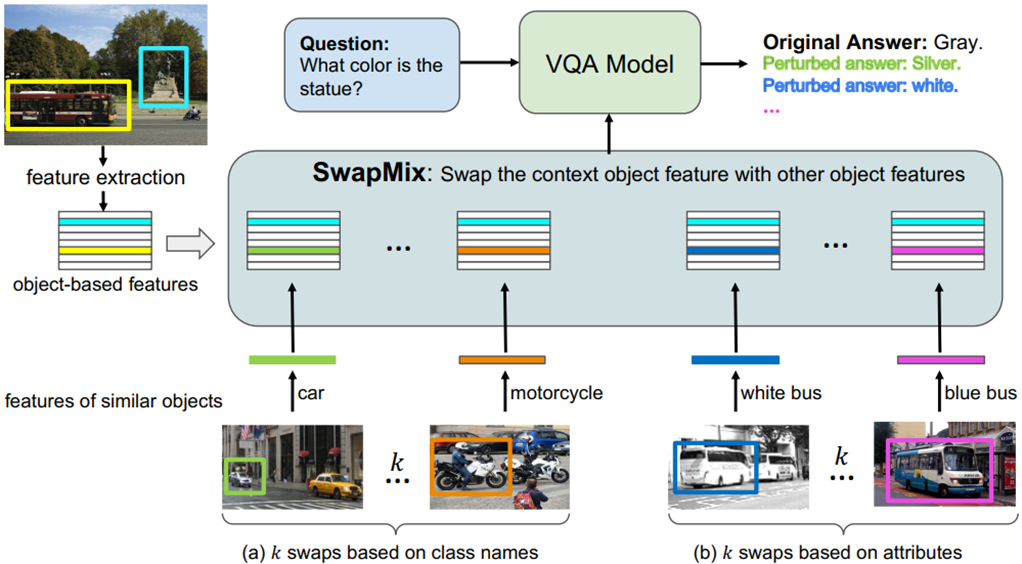
SwapMix的流程图如上图所示,特征提取刚刚说过了,然后来看具体是怎么执行扰动的。对于每个上下文对象的特征,我们表示为![]() ,o表示类别特征,a表示属性信息,然后执行的扰动分为两种,类别标签扰动和属性扰动,每种扰动都执行k次,最终可以获得2k种扰动。
,o表示类别特征,a表示属性信息,然后执行的扰动分为两种,类别标签扰动和属性扰动,每种扰动都执行k次,最终可以获得2k种扰动。
Swapping the context class
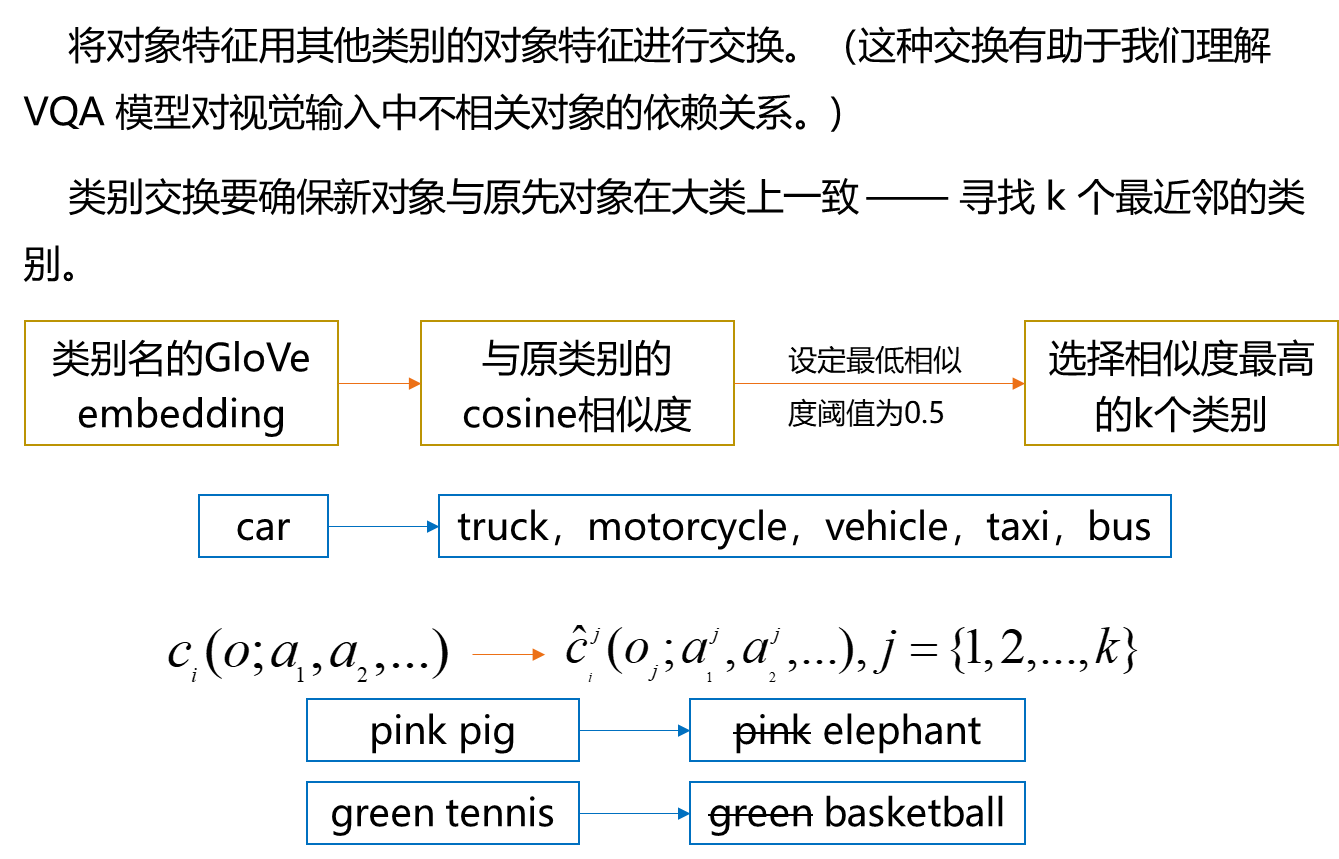
类别标签扰动就是将对象特征用其他类别的对象特征进行交换,这种交换有助于我们理解 VQA 模型对视觉输入中不相关对象的依赖关系。但在类别交换的过程中要确保新对象与原先对象在大类上一致,那么我们就需要寻找 k 个最近邻的类别。方法就是用自然语言里面的工具对类别进行编码,然后计算他们与原类别的cosine相似度,选择最相似的k个类别。 对于一个类别为o的上下文对象,我们选择了k个最近邻的新类别来替换o。然后需要对这k个类别进行实例化,我们会从数据集中随机选择一个属于该类别的具体对象,新的特征表示也就包含了新的类别信息和它对应的属性信息。 这里没有保持原类别的属性信息,主要是因为原类别属性对于新类别来说可能是不合理的,比如说上图这两个例子。
Swapping the context attributes
然后属性就是保持对象类别不变,只改变对象属性。与对象类别扰动相比,属性扰动是一种更可控的扰动。 为了获得k个具体对象,我们从数据集中具有不同属性的同一类的对象中随机选择k个对象,来替换原来的对象。 对于每个上下文对象,我们可以获得2k种扰动,那么对于一个包含m个上下文对象的图像来说,我们就可以获得2mk个扰动了。
SwapMix as a training strategy
另外,在模型训练阶段使用SwapMix可以用来进行数据增强,相当于可以使模型在不同的epoch内看到具有不同视觉上下文的图像,这会迫使模型尽量少地关注这些不相关的上下文,而专注于图像中相关的对象来回答问题。
Experiment

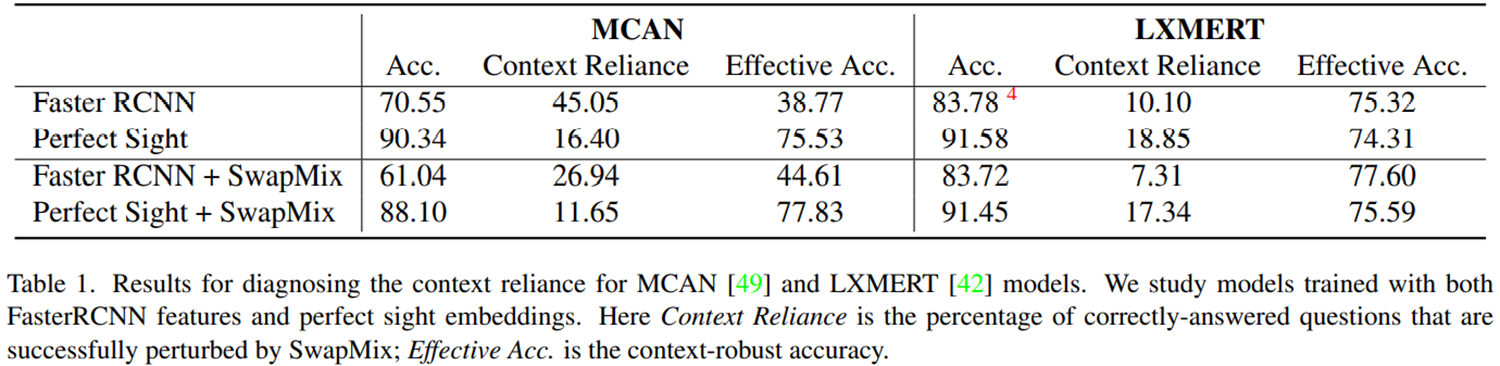
这篇文章里面主要的实验结果就是这个表。先看第一行,两个模型都是用的Faster RCNN提取的图像特征,表示的是不具有完美视觉的模型,两个模型整体的准确率分别为70.55和83.78,加入上下文扰动后,对于MCAN模型来说,在他原本能够回答正确的问题中,他会改变45%的答案,有效的准确率只有38.77,非常低。 而对于这个预训练模型来说。他的上下文依赖性要小得多,有效准确率也没下降那么多,说明它对于上下文扰动要稳健得多,作者猜想可能是因为这个模型在预训练阶段见了大量的数据,所以他能更鲁棒。
第二行是具有完美视觉的VQA模型,就不用Faster RCNN提取视觉信息了,直接用的数据里里面的注释信息进行编码成视觉特征,两个模型都可以达到90%多的准确率,对于MCAN模型来说,上下文依赖小了很多,有效准确率提升了非常多。这说明有完美视觉的模型比用faster rcnn提取的模型更鲁棒。 这里其实还有一个比较奇怪的现象,就是这个预训练模型它的上下文依赖反而增大了,有效准确率反而降低了,没有按照预想的方向发展,论文里面作者也没有解释。作者只说在这样的实验设定下,两个模型的指标差不多,如果说这个预训练模型没有见过那么多数据,那它的准确率和鲁棒性可能都不如MCAN。
然后第三四行分别就是前两行的对比实验了,使用SwapMix作为数据增强手段用于两个模型的训练。加入了这个手段后,模型相对于原来,上下文依赖都有大幅的下降,有效准确率都有所提升。 但是仔细观察这个数据,可以发现,虽然这两个指标都在朝着我们想要的方向发展,但是模型回答问题的准确率其实是在下降的,这里就需要在模型的鲁棒性和整体准确率之间进行权衡了。这个现象也说明了,原先的模型就是在利用数据的偏差来回答问题的。
其他
作者提供的代码可以跑通!这篇文章的idea挺有趣的,跑了一下作者的代码,有时间将会深入研究一下代码,并整理分享。