论文

论文标题:Masked Autoencoders Are Scalable Vision Learners
发表于:CVPR2021
论文链接:https://arxiv.org/pdf/2111.06377.pdf
论文代码:https://github.com/facebookresearch/mae
李沐讲解:MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili
李沐视频笔记:MAE 论文逐段精读【论文精读】 - 哔哩哔哩
拟代码:别再无聊地吹捧了,一起来动手实现 MAE(Masked Autoencoders Are Scalable Vision Learners) 玩玩吧! - 知乎
知乎分享:如何看待何恺明最新一作论文Masked Autoencoders? - 知乎
Abstract
本文为计算机视觉领域提出一种可扩展的自监督学习方法:MAE(Masked Autoencoders,掩膜自编码器)。MAE的做法是:随机遮盖输入图片的子块,然后重建丢失像素。其核心设计为:
非对称的编码-解码架构:
编码器的输入为没有被mask的子块;解码器为轻量级(解码器仅在图像重建的预训练中起作用,因此解码器设计可以独立于编码器,且灵活和轻量级),输入为编码器的输出和被mask部分的位置信息,输出为待重建的丢失像素的值。
高比例mask情况下的自监督:
高比例指75%;作者认为这对计算机而言不容易,但有意义。
通过以上两点,可加速模型训练(3倍或以上,因为编码器只输入未被mask的部分,数据量少)、提高准确率、泛化性好(因其可扩展而可训大模型)。仅使用 ImageNet-1K 数据,vanilla ViT-Huge 模型实现了最佳准确率 (87.8%,超过了之前所有只使用ImageNet-1K数据的结果)。并且其下游任务的迁移也优于监督训练,证明可扩展能力很可观。
极致精简版
用下面几句话来简单说明下这篇文章:
-
恺明出品,必属精品!MAE延续了其一贯的研究风格:简单且实用;
-
MAE兴起于去噪自编码,但兴盛于NLP的BERT。那么是什么导致了MAE在CV与NLP中表现的差异呢?这是本文的出发点。
-
角度一:CV与NLP的架构不同。CV中常采用卷积这种具有”规则性“的操作,直到近期ViT(Vision Transformer)才打破了架构差异;
-
角度二:信息密度不同。语言是人发明的,具有高语义与信息稠密性;而图像则是自然信号具有重度空间冗余:遗失块可以通过近邻块重建且无需任何全局性理解。为克服这种差异,我们采用了一种简单的策略:高比例随机块掩码,大幅降低冗余。
-
角度三:自编码器的解码器在重建方面的作用不同。在视觉任务方面,解码器进行像素重建,具有更低语义信息;而在NLP中,解码器预测遗失的词,包含丰富的语义信息。
-
基于上述三点分析,作者提出了一种非常简单的用于视觉表达学习的掩码自编码器MAE。
-
MAE采用了非对称的编解码器架构,编码器仅作用于可见图像块(即输入图像块中一定比例进行丢弃,丢弃比例高达75%)并生成隐式表达,解码器则以掩码token以及隐式表达作为输入并对遗失块进行重建。
-
搭配MAE的ViT-H取得了ImageNet-1K数据集上的新记录:87.8%;同时,经由MAE预训练的模型具有非常好的泛化性能。
Method
所提MAE是一种非常简单的自编码器方案:基于给定部分观测信息对原始信号进行重建 。类似于其他自编码器,所提MAE包含一个将观测信号映射为隐式表达的编码器,一个用于将隐式表达重建为原始信号的解码器。与经典自编码器不同之处在于:我们采用了非对称设计,这使得编码器仅依赖于部分观测信息(无需掩码token信息),而轻量解码器则接与所得隐式表达与掩码token进行原始信号重建(可参见下图)。

基本流程:
- 对图片切分 patch, 随机挑选少部分(比如文中25%)作为网络输入;
- 输入通过 encoder 得到对应编码后的 encoded patches
- 将 encoded patches 还原到对应的原始位置,并在缺失的部分补上 masked patches
- 送入 decoder, 每个 decoder 预测对应 patch 的图像像素点;
- 计算预测的像素和原始图片的像素之间 MSE 作为 loss。
- 取训练完的模型的 encoder 部分作为下游任务的 basemodel 并在下游任务下 finetune。
Masking 参考ViT,我们将输入图像拆分为非重叠块,然后采样一部分块并移除其余块(即Mask)。我们的采样策略非常简单:服从均匀分布的无重复随机采样 。我们将该采样策略称之为“随机采样”。具有高掩码比例的随机采样可以极大程度消除冗余,进而构建一个不会轻易的被近邻块推理解决的任务 (可参考下面图示)。而均匀分布则避免了潜在的中心偏置问题。

MAE Encoder MAE中的编码器是一种ViT,但仅作用于可见的未被Mask的块。类似于标准ViT,该编码器通过线性投影于位置嵌入对块进行编码,然后通过一系列Transformer模块进行处理。然而,由于该编解码仅在较小子集块(比如25%)进行处理,且未用到掩码Token信息。这就使得我们可以训练一个非常大的编码器 。
MAE Decoder MAE解码器的输入包含:(1) 编码器的输出;(2) 掩码token。正如Figure1所示,每个掩码Token共享的可学习向量,它用于指示待预测遗失块。此时,我们对所有token添加位置嵌入信息。解码器同样包含一系列Transformer模块。
注:MAE解码器仅在预训练阶段用于图像重建,编码器则用来生成用于识别的图像表达 。因此,解码器的设计可以独立于编码设计,具有高度的灵活性。在实验过程中,我们采用了窄而浅的极小解码器,比如默认解码器中每个token的计算量小于编码器的10% 。通过这种非对称设计,token的全集仅被轻量解码器处理,大幅减少了预训练时间。
Reconstruction target 该MAE通过预测每个掩码块的像素值进行原始信息重建 。解码器的最后一层为线性投影,其输出通道数等于每个块的像素数量。编码器的输出将通过reshape构建重建图像。损失函数则采用了MSE,注:类似于BERT仅在掩码块计算损失。
我们同时还研究了一个变种:其重建目标为每个掩码块的规范化像素值 。具体来说,我们计算每个块的均值与标准差并用于对该块进行归一化,最后采用归一化的像素作为重建目标提升表达能力。
Simple implementation MAE预训练极为高效,更重要的是:它不需要任何特定的稀疏操作。实现过程可描述如下:
-
首先,我们通过线性投影与位置嵌入对每个输入块生成token;
-
然后,我们随机置换(random shuffle)token序列并根据掩码比例移除最后一部分token;
-
其次,完成编码后,我们在编码块中插入掩码token并反置换(unshuffle)得到全序列token以便于与target进行对齐;
-
最后,我们将解码器作用于上述全序列token。
正如上所述:MAE无需稀疏操作。此外,shuffle与unshuffle操作非常快,引入的计算量可以忽略。
Experiments
我们在ImageNet-1K数据集上进行自监督预训练,然后再通过监督训练评估预训练模型的表达能力。
Main Properties

Baseline:ViT-Large 。我们采用ViT-Large作为消融实验的骨干,上表为从头开始训练与MAE微调的性能对比。可以看到:从头开始训练(200epoch),ViT-L的性能为82.5%且无需强正则技术;而MAE(注:仅微调50epoch)则取得了大幅性能提升。

上表则从不同角度进行了消融实验对比,一一道来。
Decoder Design 从Table1(a)与Table1(b)可以看到:解码器的设计可以非常灵活 。总而言之,默认解码器非常轻量,仅有8个模块,维度为512,每个token的计算量仅为编码的9%。
- Decoder depth:decoder 的深度对 linear probing 影响很大, 因为 decoder 越深,那么训练时过程中会使它的浅层对应的特征与预训练的重建任务越无关,也就是越抽象,利于迁移。而 finetune 因为会在新任务上重新学习,所以深度对他影响要小很多。
- Decoder width:decoder的宽度对 linear probing 影响很大, 对finetune 影响很小。
- 所以作者最后的模型选择 finetune 方式迁移到下游任务,且采用比较浅比较窄的 decoder(8 个 blocks, 512-d width), 这样能够加速且省显存。
Mask Token MAE的的重要设计:在编码阶段跳过掩码token,在解码阶段对其进行处理。Table1(c)给出了性能对比,可以看到:编码器使用掩码token则会导致性能下降 。
- encoder 是否使用 mask token:文中取可见 patches 的方式是对输入的所有 patch (假设一共有 N 个patch)先 shuffle 一下, 然后把后 N * masking_ratio 的 patch 丢掉,只有前面部分过网络。
- 另一种可能的方法是在 encoder 那增加一个 mask token 指代哪些 patch 需要保留哪些不需要保留。 实验结果表明这样做效果明显变差了, 原因使用 mask encoding 在训练时模型见到的是一些残缺的输入, 但是在实际下游任务中见到的确实完整的输入, 这会带来很大的 gap。
Recontruction target 重建目标 Table1(d)比较了不同重建目标的性能:1. 直接对原始像素重建;2. 以 patch 内像素的统计量对 patch 做 norm 后的像素重建;3.PCA 后重建; 4. dVAE。可以看到:引入块归一化可以进一步提升模型精度 。
Data Augmentation 数据增广 Table1(e)比较了不同数据增广的影响,可以看到:MAE仅需crop即可表现非常好,添加ColorJitter反而会影响性能 。另外,令人惊讶的是:当不使用数据增广时,MAE性能也非常优秀 。
Mask Sampling Table1(f)比较了不同掩码随机采样策略,可以看到:不同的采样策略均具有比较好的性能,而随机采样则具有最佳性能 。
Masking ratio 下图给出了掩码比例的影响,可以看到:最优比例惊人的高 。掩码比例为75%有益于两种监督训练方式(端到端微调与linear probing)。这与BERT的行为截然相反,其掩码比例为15%。

与此同时,从上图可以看到:端到端微调与linear probing两种方式存在不同的趋势:
-
对于linear probing而言,模型性能随掩码比例非常稳定的提升直到达到最高点,精度差约为20%;
-
对于微调来说,模型性能再很大范围的掩码比例内均极度不敏感,而且所有微调结果均优于linear probing方式。
Training Schedule 下图给出了不同训练机制的性能对比(此时采用了800epoch预训练),可以看到:更长的训练可以带来更定的精度提升 。作者还提到:哪怕1600epoch训练也并未发现linear probing方式的性能饱和。这与MoCoV3中的300epoch训练饱和截然相反 :在每个epoch,MAE仅能看到25%的图像块;而MoCoV3则可以看到200%,甚至更多的图像块。

Comparisons with Previous Results

上表给出了所提MAE与其他自监督方案的性能对比,从中可以看到:
-
对于ViT-B来说,不同方案的性能非常接近;对于ViT-L来说,不同方案的性能差异则变大。这意味着:对更大模型降低过拟合更具挑战性 。
-
MAE可以轻易的扩展到更大模型并具有稳定的性能提升。比如:ViT-H取得了86.9%的精度,在448尺寸微调后,性能达到了87.8% ,超越了此前VOLO的最佳87.1%(尺寸为512)。注:该结果仅使用了ViT,更优秀的网络表达可能会更好。
Transfer Learning Experiments

上表给出了COCO检测与分割任务上的迁移性能对比,可以看到:相比监督预训练,MAE取得了全配置最佳 。当骨干为ViT-B时,MAE可以取得2.4AP指标提升;当骨干为ViT-L时,性能提升达4.0AP。

上表给出了ADE20K语义分割任务上的迁移性能对比,可以看到:MAE可以大幅改善ViT-L的性能,比监督训练高3.7。
Conclusion
本文提出了一种简单高效的视觉自监督训练方法,作者从图像和语言的信号本质特征出发,考虑通过使用NLP领域中较为成熟的技术提高视觉自监督框架的性能,同时认真分析和处理二者之间的差距。本文也观察到,所提的MAE方法可以从局部推断出复杂的整体重建,表明它已经学习到了许多视觉概念,即语义。本文也提醒我们在视觉Transfromer火热的当下,我们更应该从特征学习的本质出发来思考视觉学习的问题。“扩展性好的简单算法是深度学习的核心”。
如何看待何恺明最新一作论文Masked Autoencoders?
来源/ 知乎
作者/ Bowen Cheng
时间/ 2021.11.12
哪怕不看作者我也很喜欢这篇paper,忍不住分享一下我喜欢这篇paper的原因以及一些思考:
- 我认为这篇文章从某种方面证明了过去一年对ViT的各种改变可能都是没有意义的,用MAE做pre-training只用ImageNet-1k就能达到>87% top 1 accuracy,超过了所有在ImageNet-21k pre-training的ViT变种模型。所以它说明了纯Transformer确实很强,只不过特别难训练。一个很有意义的follow-up方向是:MAE是不是唯一的或者最好的训练目标?有没有其他没有人试过的训练目标能达到同样或者更好的结果?
- 如果把MAE里encoder的ViT换成其他带convolution的ViT或者local attention的ViT结果会变好还是变差呢?我觉得这是一个很重要的实验并且也是一个low hanging fruit,因为它的结果很有可能让过去一年内基于ViT的工作变得没有意义 (如果结论是这些改动都没用那就有意思了)。
- 不知道这篇文章对self supervised learning community有多大影响,下一步是不是要从contrastive pre-training挪到generative pre-training了?
- 我觉得这篇文章算是开了一个新坑。因为在我看来MAE只是验证了“Masked image encoding”的可行性,但是看完paper我并不知道为啥之前的paper不work而MAE就work了。特别是ablation里面的结果全都是80+ (finetuning), 给我的感觉是我们试了一下这个objective就神奇的work了。我估计肯定会有一批人去研究它能work的原因 (就像现在很多人研究contrastive learning work的原因一样)。
不管这篇文章有没有所谓的“novelty”,能引发我的思考让我觉得有follow的价值就是好文章。
来源/ 知乎
作者/ 田永龙
时间/ 2021.11.13
我一般判断看一篇方法类文章将来是否有影响力从下面三个角度(重要程度依次递减)
(1) 惊人程度,Surprise
研究的目的就是探索前人不知道的知识,挖掘新的信息。我认为MAE在这点上很棒,它告诉了我直接reconstruct image原图也可以做到很work,这改变了我们绝大多数人的认知(之前iGPT没有很work; 其他答案提的BEIT也并不是reconstruct原图,而是reconstruct feature)。
在NLP reconstruct效果很好是因为文字本身就是highly semantic,所以模型预测的目标信息量大,而噪音小; 图片相比而言语意信息密度低,如果模型要完全预测对目标的话就要浪费capacity去model那些不重要的玩意儿。因此我一直觉得reconstruction这个学习目标不太对。
但这篇文章似乎是换了种方式来解决这个问题(个人偏见),就是压根就没想让模型完全恢复原图,MAE只输入很少的patch,那无论如何也恢复不了原图。同时我们都知道,相比高频信号而言,神经网络更擅长抓住低频的信号。高频是局部细节,低频更多是high level semantics。所以netwok最后可能以fit低频信号为主学到了high-level feature? 论文里面的visualization看起来也比较契合。
以前CovNets时代做不了,如果把mask的图丢给convnet,artifacts太大了,预训练时候模型时既得费劲入管mask out掉的region,预训练完了后还造成了跟后面完整图片的domain gap,吃力不讨好,我之前用convnet试过这种mask patch的相关的东西,结果乱七八糟的不work。但MAE里Transformer可以很好避开这个坑,太妙了。我的导师也评价说我们AI的ecosystem一直在变,所以方法的有效性和相对优越性也在evolve,不是一层不变的。
还有一个小点是MAE也让我学到了linear acc和fine-running acc可以完全uncorrelated甚至反过来。之前就看到有论文讨论linear和fine-tuning关联并不强,但没想到能差别这么大。以后的evaluation都得变了⋯⋯看来做实验不能盲目follow之前的metric了…
(2) 简单性 simplicity
这篇文章非常idea非常简单,实现起来也快捷,有趣的是文章里面一个公式都没放哈哈。我受导师的影响,认为在保持核心idea不变的情况下,或者说surpriseness不变的情况下,我们应该最小化系统的复杂度。因为越简单,也会愈发凸显惊讶程度。害,说起来我最开始接触科研老想着瞎加玩意儿,即使现在也经常做加法而不是减法,确实比较菜…
(3) 通用性 generality
其实(2)和(3)我也不确信哪个更重要,有时候(2)和(3)也相辅相成,越简单越通用。无疑MAE在(3)也做的很棒,几乎影响所有vision里面的recognition类别的任务,不过这也是做representation learning这方向的好处…死磕基础问题。
所以,综合这几点我觉得无疑是visual representation learning今年最有影响力的文章…像这种能改变我的认知,启发我更多思考的文章,对我来说就是好的novel的。novelty应该不只是technical这个维度…
P.S. 看到有个答案说KM的研究品味不高,我完全不敢同意,每个人喜好做不同类型的工作罢了,在做方法算法这块,KM的的品味绝对是最top的,传闻就有做graphics的很solid的教授评价他: whatever this guy touches become gold。当然如果不是方法类的研究,而是要做一件从0到1的事,或者挖坑带领大家前进,那影响力就不能从这三个标准来看了,得看vision了
来源/ 知乎
作者/ 田柯宇
时间/ 2021.11.15
属于是一个不错的 learning algorithm 工作。是把古早的 pixel-level inpainting[1]在自监督 (ssl) 上又做超过 contrastive learning 了. 这件事情:
(1)反常识。图像这种2d信号本身高维、连续、高不确定性、低语义密度,看起来 pixel reconstruction 并不会是好的 pretext-task,BEiT[2]也验证了 pixel reconstruction 相比 discrete token prediction 更难学好,iGPT[3]的性能也体现了这一点,audio 模态也有类似做 vector-quantized[4]来避免直接重建信号而是去 token prediction 的做法。但这篇 MAE 就是直接大比例重建 pixel + MSE 优化(看起来 mask 比例大到质变)。
(2)大势所趋。最近爆火的 contrastive learning 存在过度依赖 augmentation 的固有问题被渐渐挖出[5][6][7],而比较优雅的、在 nlp 领域全面开花的 generative ssl 在 vision 上却一直处于“低估/未被充分探索”的状态(可能原因之一是对 linear probe classification 过于看重,所以 contrastive 这种鼓励学全局语义的 discriminative ssl 就容易发挥优势)。那么众望所归的大势,就可能是让一种比 contrastive learning 更通用的 ssl 方式一扫视觉领域。
(3)开了新坑。比如高 mask rate + MSE loss 意味着什么?比如用上图像数据存在很多天然 augmentation 的优势会不会更好?在出现真正横扫视觉领域的 ssl 之前,这里还有很多新路要走。MAE 的价值在于把视角重新引导回 generative,把对 contrastive 可能存在的过多偏爱给拨正。
先摆明立场:
非常期待非 contrastive learning 的 ssl 方式在视觉领域的突破性进展(也算是轮回了)。
同时要辩证看待。“造神”的一些言论确实稍过了。另外虽然这篇完全不能和 resnet 这样的工作比,个人也不赞同“认为 BEiT/MAE 是 BERT 的机械搬运”的观点。能把一个大胆的想法/一个无现成解法的问题做work(远超 iGPT,linear probe 和 finetune 都很高),本身也是 solid 的体现,其中应该也包含了有价值的insight和细节处理可以挖(实际 BERT 在 nlp 也不是第一个做 biLM 的工作,但的确是方案最成熟,也是时间见证了最有 impact 的那一支工作)。期待后续这类工作的原因分析和拓展。
具体 comments:
一直觉得近期的 augmentation-based contrastive learning 并不是 ssl for vision 最优雅的方式:
- 虽然这波方法用上了图像数据上有良好先验的 data augmentation 这个文本数据没有的超大优势,但似乎用的太过,导致存在一个很大的固有问题:本质是学了一堆 transformation-invariant 的 representation. 而要判断用哪些 augmentation 是好的,i.e. 要判断让模型学到什么样的 transformation invariance 是好的,本身就依赖于要知道下游任务具体要干什么(比如下游任务如果认为颜色语义很重要,那么 color-based augmentation 就不应该用在 pretrain 中),导致“要想上游 pretrain 得好,就得先知道下游任务需要哪些语义信息”的奇怪尴尬局面。
- 这个问题在[5]中也有指出。另外最近一些工作[6][7]似乎也在尝试让 contrastive learning 不仅仅只学 invariance(例如同时保持对各种 transformation 的 variant 和 invariant,从而让下游自己去挑选),以期望得到一个更 general 的 ssl algorithm.
其实早些阵子的 vision ssl,pretext-task 很五花八门,主要是一些 discriminative(rotation degree prediction,location prediction,jigsaw,etc.)和 generative(inpainting[1])的方法。个人认为 generative 还是更优雅一些,也更接近 self-supervised 的本质:pretend there is a part of the input you don't know and predict that(LeCun's talk[8]),同时,也没有类似上述的奇怪局面。
但图像数据相比文本数据天然有更弱的语义性/语义密度、更强的连续性和不确定性,导致 pixel-level inpainting 一直被认为难做到像 BERT 那样的惊艳效果。再加上在 vision 大家都很关注的 linear probe setting,又天然不利于 generative ssl 施展拳脚,就导致了现在 contrastive learning 大行其道、非 contrastive learning 被冷落的局面。
也许有人会 argue 说是因为早期 inpainting ssl 使用的模型太弱。但最近的 ViT[9],SiT[10],iGPT[3],甚至是 BEiT[2] 的 ablation,也说明了即便用上了先进的 ViT,探索一条不是 contrastive learning 的 ssl 道路仍然是艰难的。
所以,现在看到 BEiT、MAE 这样的工作,真的很欣慰。期待后续更多追溯原因和更深层解读的 paper。也希望 visual represent learning 能走的更好,感觉一组很强的 pretrained vision model 带来的社会价值真的很高。另外,有一些点真的很有意思,例如 BEiT 似乎体现了用 dVAE 去 tokenize 可以一定程度上缓解 pixel-level 带来的高连续性和不确定性的问题(这是二维信号图像;对于一维信号audio,vq-wav2vec[4]也给了类似 tokenize 做法),但 MAE 发现 tokenize 是没有必要的,而且用 MSE 学就够了。所以后续也会 post 上一些详细解读的笔记,简单梳理一下 vision ssl 然后重点理解探讨下 BEiT 和 MAE,包括 coding 细节,希望能和大家多多交流~
参考
- ^ab【inpainting】Pathak, Deepak, et al. "Context encoders: Feature learning by inpainting." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. https://openaccess.thecvf.com/content_cvpr_2016/papers/Pathak_Context_Encoders_Feature_CVPR_2016_paper.pdf
- ^ab【BEiT】Bao, Hangbo, Li Dong, and Furu Wei. "BEiT: BERT Pre-Training of Image Transformers." arXiv preprint arXiv:2106.08254 (2021). https://arxiv.org/abs/2106.08254
- ^ab【iGPT】Chen, Mark, et al. "Generative pretraining from pixels." International Conference on Machine Learning. PMLR, 2020. http://proceedings.mlr.press/v119/chen20s/chen20s.pdf
- ^ab【vq-wav2vec】Baevski, Alexei, Steffen Schneider, and Michael Auli. "vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations." International Conference on Learning Representations. 2019. https://openreview.net/pdf?id=rylwJxrYDS
- ^ab【InfoMin】Tian, Yonglong, et al. "What makes for good views for contrastive learning?." arXiv preprint arXiv:2005.10243 (2020). https://arxiv.org/abs/2005.10243
- ^abXiao, Tete, et al. "What should not be contrastive in contrastive learning." arXiv preprint arXiv:2008.05659 (2020). https://arxiv.org/abs/2008.05659
- ^abDangovski, Rumen, et al. "Equivariant Contrastive Learning." arXiv preprint arXiv:2111.00899 (2021). https://arxiv.org/abs/2111.00899
- ^Self-Supervised Learning. AAAI-20/IAAI-20/EAAI-20 Invited Speaker Program. Yann Lecun. https://drive.google.com/file/d/1r-mDL4IX_hzZLDBKp8_e8VZqD7fOzBkF/view
- ^【ViT】Dosovitskiy, Alexey, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale." International Conference on Learning Representations. 2020. https://arxiv.org/abs/2010.11929
- ^【SiT】Atito, Sara, Muhammad Awais, and Josef Kittler. "Sit: Self-supervised vision transformer." arXiv preprint arXiv:2104.03602 (2021). https://arxiv.org/abs/2104.03602
来源/ 知乎
作者/ 胡瀚
时间/ 2021.11.12
趁着写论文的间歇来写个回答,讲几个感想:
1. 除了idea和实验方面的天赋,还想说恺明对于技术趋势的敏锐性和革命前夕的神准把握方面实在太牛了。一直觉得创新本身不是最重要的,更重要的是带来改变领域走向的理解或者技术,恺明这篇论文无疑是会达到这一成就的,MoCo和Mask R-CNN也是如此,大巧无工,但真的改变了领域。
2. 过去我们过于看重linear probe这个指标,MAE无疑会改变这一现状,以及让我们重新去看待contrastive learning和mask image modeling的未来。很巧的是,一年前,我们NLC组的同事Hangbo Gao、 @董力 以及韦福如和我们提到要做和MAE类似路线的方法:BEIT,那时还觉得这个路线的方法学到的特征会太low-level,没想到半年后他们居然搞出来了,结果非常惊艳,事实上也改变了我的认知。MAE这个工作无疑也会让BEIT也大火起来, 尽管过去4、5个月BEIT其实在小范围内已经很受关注,但它受到的关注显然小于它实际的贡献。恺明大神这次的论文,让这个方向工作的重要性得到了应有的证明。

https://ancientmooner.github.io/doc/self-supervised-learning-cv-valse.pdf
3. 看到恺明Intro里的一句话:”The idea of masked autoencoders, a form of more general denoising autoencoders [48], is natural and applicable in computer vision as well. Indeed, closely related research in vision [49, 39] preceded BERT.” 要特别赞一下这句话,其实也是有共鸣的,今年在RACV上讲了一个态度比较鲜明(或者极端吧。。)的talk,说要“重建CV人的文化自信”,就拿它作为其中一个例子:Mask Image Modeling或者视觉里叫Inpainting的方法在CV里做的蛮早的,在BERT之前就已经有一些。

RACV2021观点集锦 | 视觉transformer 从主干encoder 到任务decoder: 现状与趋势 (qq.com)
4. 想再次感叹一下,CV和NLP以及更多领域的融合看来真的是大势所驱了,希望不同领域的人多多合作,一起来搞事情。前几天见到董力和福如,他们提到有个多模态的工作因为挂了Arxiv不能投ACL了,我提议他们投CVPR,不晓得他们最后是什么决定。无论如何,CV的会议是很开放和包容的,理论的、偏工程的、交叉的、基于toy data做的,只要有点意思都有机会被接收,相信这也是CV领域能够长期这么繁荣的重要原因之一。在AI各个子领域技术趋同的背景下,它们之间的联系和跨界也会越来越紧密,这正是CV这个社区体现开放和包容心态的时候,吸引更多NLP的同仁们加入CV或者交叉研究中,以及我们自己去尝试给其他AI子领域进行贡献的时候,最终的目标就是和各个领域一起共舞,共同推进AI的进展。
来源/ 知乎
作者/ bearbee
时间/ 2021.11.14
首先谈谈读完论文后的整体感受:
(1)Kaiming的讲故事能力和实验能力,一如既往的强。整篇论文没有一个公式,通俗易懂地将论文出发点、创新点以及方法解释清楚,实验部分不仅佐证了论文方法,而且引人深思。
Introduction中“We ask: what makes masked autoencoding different between vision and language? ”,相信这个问题大家都有想过。在无监督学习任务上,CV和NLP的区别是啥,在NLP任务中,Bert已经一统江湖,各子任务(如翻译、生成、文本理解等)均可使用相同的无监督预训练模型。但是在CV任务中却各玩各的,有对分类任务的无监督学习(如SimCLR、MoCo、BYOL),也有对检测任务的无监督学习(如DenseCL、DetCo),各个子任务都要自己单独搞一套无监督学习,谈何统一。那是什么原因导致的呢?Kaiming给出了三点原因:(1)基础架构不同,NLP目前都采用Transformer,而CV之前是CNN主导,CNN输入非常不灵活,难以引入位置编码等信息。在方法中,论文也解释了位置编码的重要性,没有该编码,mask tokens就缺失了在图像位置信息;(2)Languages是人创造的,具有强语义、高信息密度特点,而Image则是自然信号,具有低信息密度特点,Image的信息量是非常大的,而且存在较大的冗余性。对Languages进行15%比例的Mask,Bert就可以很好学习,而该Mask比例对Image来说远远不够,模型很容易偷懒,简单地从邻居信息就可以脑补学习,最终导致学不到高层语义信息,解决办法也非常简单,既然太简单了模型会偷懒,那就加大难度,于是对Image进行75%比例的Mask,加大难度后模型就学好了,这也是本文的核心,简单但有效!(3)解码器不同,Languages任务的解码器是直接reconstruct文本,目标任务也就是文本补全,最终目标和reconstruct目标是一致的,因此Bert的解码器非常简单,MLP即可。而Image任务的解码器则是reconstruct pixel(本文)或reconstruct feature(BEiT),目标任务却是分类,最终目标和reconstruct目标差异较大,为了学到高层语义的特征表示,需要针对性设计解码器。
基于以上出发点,设计了Masked Autoencoders,方法非常简洁:

将一张图随机打Mask,未Mask部分输入给encoder进行编码学习,再将未Mask部分以及Mask部分全部输入给decoder进行解码学习, 最终目标是reconstruct出pixel,优化损失函数也是普通的MSE。这里面需要注意的点是,encoder和decoder都是采用Transformer,Mask后的每个Patch都用位置编码进行描述,另外decoder是轻量级网络,这是因为作者发现在fine-tuning模式下对深层decoder的依赖性不大。
实验部分也非常精彩,仅选其中一个最有意思的实验说:

有两点:其一是fine-tuning的效果全面碾压linear probing,linear probing是衡量无监督学习效果的一个通用评价方式,单看linear probing下的指标,MAE是远不如大部分的contrastive learning无监督学习的,但是Kaiming没有放弃,而是换用了fine-tuning方式,指标则有大幅提升,不得不佩服大佬的思维(摆脱现有限制)。其实想想也合理,论文里也提到了“Linear probing has been a popular protocol in the past few years; however, it misses the opportunity of pursuing strong but non-linear features—which is indeed a strength of deep learning ”,深度学习最厉害的不就是非线性拟合能力吗?不过,fine-tuning的方式也没能彻底说服我,略担心fine-tuning后会不会导致模型是task-specified的,其迁移能力可能较弱,这样的话,也就无法统一CV任务了。好在BEiT验证了在分割任务上的效果,如何保证无监督学习的特征强表达能力,同时兼顾泛化能力,仍然是一个值得探讨的话题。

其二是Mask比例在75%时,linear probing和fine-tuning下效果才能最好。这也符合在Introduction中介绍的,图像是低信息密度的,因此需要较大比例的Mask。看到75%Mask,甚至90%Mask下的reconstruct可视化效果,我是跪了。

单独依赖局部区域的纹理或边缘等特征是很难reconstruct出原图的,因此在如此难的问题设定下,模型可能通过推理来学习全局表征。不由得联系到GAN,在图像生成任务中,GAN通过对抗学习设计,逐步替换了VAE,最初也有一些工作在尝试用GAN来学习更好的特征表达,从而用于分类等任务,但是效果均不明显。现在Kaiming将MAE调出来了,未来是不是可以同样用GAN替换AE呢?
(2)Kaiming对技术趋势的把握能力,对学术/工业届需求的把握能力,同样的强。
如同Mask RCNN一样,工业界对物体精细描述的需求增大(不仅需要检测框,也需要物体边缘),同时又希望有一套简单有效的方法实现(对现有检测框架改动较少),Mask RCNN完美契合了该需求,因此在提出后立刻在工业界大规模使用。尽管如今有非常多Anchor Free的Instance Segmentation方法提出,Mask RCNN地位仍不可撼动,而且在很多时候,Mask RCNN的效果还是最优的。现如今,工业界对CV需求也很明确,如何得到一个通用的预训练模型,能够在各任务上表现优异,如同Bert在NLP任务中一样。在此方面,本文不是首创,BEiT是第一个洞察到的,Kaiming的MAE是把效果推上了巅峰。当大家都在研究contrastive learning的无监督学习时,这两篇论文提出了不一样的见解,并且扎扎实实地将效果做了出来,背后肯定也是付出了很大的努力。当然,contrastive learning和reconstruct learning并不矛盾,能否同时引入两者呢,即将Mask图像当做强数据增强,构造正负样本进行contrastive learning,同时Mask图像也需要进行reconstruct learning,两者互相监督,是否能学到更优的特征表达呢?
接下来再借此论文,聊聊以下两个话题的看法:
(1)数据 or 模型?
在解决CV具体问题时,经常会遇到这个争论,是补充数据解决Corner Case呢,还是优化模型解决呢?学术上对此关注较少,这也能理解,主要是为了公平比较,如果用了额外数据,怎么证明是提出模型的效果呢?但实际上,这个问题个人觉得非常值得探讨,数据对深度学习的成功有着至关重要的作用,分类有ImageNet数据,检测有COCO数据,分割有ADE数据,这些数据集极大推动了模型的优化。但目前,在这些数据集上的指标越来越高,再继续优化的必要性又有多大呢?打比赛时,经常会遇到这样问题,优化了半天模型不如加点训练数据,那这样的模型优化又有多大意义呢?因此,个人觉得关注数据是比关注模型更重要的。那又怎么补充数据呢,直接标注的话则会带来较大标注成本,而且迟早有一天也会被模型优化到极致,因此无监督学习、半监督学习才是更优的方式,这也是Lecun提到的自监督学习是深度学习最大的一块蛋糕。再回到解决Corner Case上,补充相应数据是一种非常直接的解法,核心在于如何补充数据。在这方面,自动驾驶公司(特斯拉、百度、Momenta)已有非常深入的探索,在视觉感知系统中贯彻了数据闭环,通过数据驱动模型优化,如下所示(转自特斯拉的技术分享):

这里就不详细展开了,有时间再专门聊聊数据闭环的事情。
(2)Transformer or CNN?
前几天看到RACV上有这个话题的激烈讨论,感兴趣的可以去看 RACV2021观点集锦 | 视觉transformer 从主干encoder 到任务decoder: 现状与趋势
在此我简单谈下个人看法,
我是支持Transformer的,原因有两点:(1)相比CNN来说,Transformer的输入非常灵活,如Kaiming也提到的,CNN架构很难引入位置编码信息,尽管一些工作也说明CNN通过Padding也能学到位置信息,但是如何显式的表述位置仍然是个难题。尽管通过大Kernel的CNN设计+一堆优化技巧也能达到Transformer效果,但是既然已经有了Transformer架构,为啥不去拥抱呢?(2)Transformer更有机会统一CV和NLP,在NLP任务中Transformer已成为标配,在无监督学习探索上,NLP也明显走在前列,MAE也是借鉴了Bert思想的一次尝试。我们总是希望,科学的尽头是统一的。
但是,我对目前Transformer对特征提取的优化又是持悲观态度的。从ViT提出后,有着大量的工作进行改进,核心点都是怎么借鉴CNN设计经验,引入inductive bias,这是我最大的疑问点,我们已有的inductive bias是对的吗?学术上普遍认为Transformer是data-hungry的,我恰恰认为这是好事,就像Bert一样,经过大量的数据驱动,从而学习到通用的特征表达,所以问题还是怎么较好地利用该特性,例如通过自监督学习补充大量数据。
总而言之,Transformer还是非常值得去关注的。在特斯拉AI Day分享中,Andrej Karpathy介绍了多视角融合BEV(将多个摄像头拍摄的图像融合到BEV空间),其中核心技术就是Transformer,技术架构如下所示:
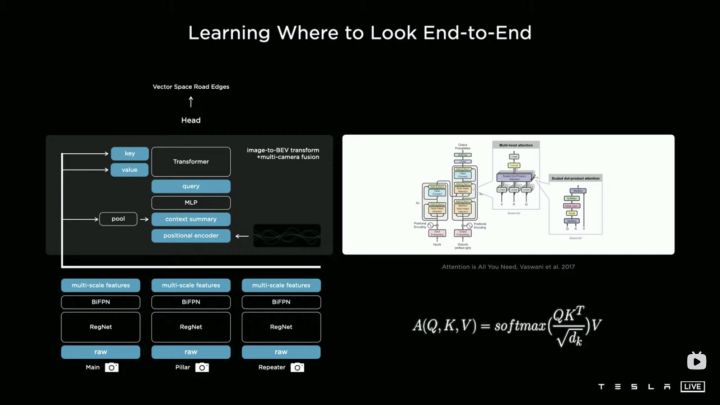
这个Transformer的设计有点instances as queries的概念,在BEV空间的一个点作为query,从图像中找到相关的信息,从而很好地实现融合。感兴趣的可以看看特斯拉AI Day分享,Tesla AI Day-2021年,特斯拉 AI day会议完整版_哔哩哔哩_bilibili
来源/ 知乎
作者/ 匿名
这篇paper,比起最后的result,不知道大家有没有思考过其中提到的一个重要问题:为什么MAE是在遮mask掉60%-70%的部分时在最后的任务时才会取得最佳呢?

从人类的视觉角度看来,当一副图片只剩下几个色块时,比如下图最右方时,这是什么东西我们人类可能都无法判断,更勿谈恢复原图像了,但是通过机器学习,我们竟然能够从几个方块恢复整个图块,这是多么神奇?!
而且通过这些方式,还能提升后续机器判别物体的能力,这又是多么神奇?

但是,如果换一种角度来想,这一切就并不奇怪了。
对于每一位机器学习初学者来说,绕不开的一课,一定是线性回归模型。

线性回归是这样的,对于N个点,我们需要找到一条线,让损失函数最小。
从信息容量的角度,我们是在用少量的参数,描述更大量的数据。
乙方抽象上说,我们寻找一条充分且最佳概括这些点的规律。

当数据变得复杂,我们就不能用简单的线性来概括,而是要升级到更复杂的自回归模型,乃至深度学习模型了。
但是本质依然是不变了,那就是用“小数据”来描述“大数据”,抽象“大数据”中的“规律”。
可是,这跟transform,bert,GPT乃至于今天的MAE有什么关系呢?
答案很简单,借用佛家“佛见一粒米,大如须弥山”的话。
不要把线性回归的点,看成一个点,要把它看成包含着一个N维矢量的小球。

线性回归模型,通过已有的N个点,预测下一个点的y值。
深度学习模式,通过N个矢量vector,预测下一个矢量vector。
如果你接受这个思想,你就会看到,不论nlp中一段文字,还是cv中一副图片,它都可以抽象成一个N个矢量的线性序列。
BERT:通过前后的序列,预测中间部分的“vector”。
GPT:通过前面的序列,预测下一部分的“vector”。
CV任务(补全):通过部分点的RGB序列,预测下一部分的“RGB”。
参考博客
何恺明最新工作:简单实用的自监督学习方案MAE,ImageNet-1K 87.8%!
Masked Autoencoders Are Scalable Vision Learners - 哔哩哔哩