文章目录
- 论文地址:https://arxiv.org/pdf/2101.05974.pdf
- 源码:CAW
- 来源:ICLR, 2021
- 关键词:Link Prediction, Causal Anonymous Walk, Temporal Graph
1 前言
该论文就动态网络的模式抽取问题,针对现有方法中的一些弊端:如主要依靠结点id和丰富的边的属性且难以抽取复杂的模式,提出了CAW(Cusal Anonymous Walk)以inductive的形式表示动态图。CAW也是一种游走,在Temporal networks中以anonymization的策略游走生成CAWs,将这些CAWs作为motifs来表示动态网络。CAWs不需要传统的基于核方法中的选择什么样的motifs、统计motifs个数不同。再者,论文中提出了神经网络模型CAW-N用于编码CAWs。
2 问题定义
动态网络中存在众多的模式,例如三角闭包以及一些更复杂的模式,目标就是在动态网络的表示中能够包含这些复杂的模式。当前对与动态网络的表示只能表示一些简单的模式或者主要停留在静态网络上。对于动态网络的研究主要由三个挑战:1)动态网络中结构和时序的混合,需要一个更好的模型对动态网络进行建模;2)模型的伸缩性,动态网络会不断地被新到来的数据更新;3)能够学习训练数据中出现过的数据,并提取出它的模式。
这里介绍一下inductive和transductive:Transduction is reasoning from obeserved, specific (training) cases to specific (test) cases. In contrast, induction is reasoning from obeserved training cases to gerneral rules, which are then applied to the test cases.
论文中用 E = { ( e 1 , t 1 ) , ( e 2 , t 2 ) , . . . } \mathcal{E}=\{(e_1, t_1), (e_2, t_2), ...\} E={ (e1,t1),(e2,t2),...}表示动态网络,其中的含义显然易见。这个序列的边就编码的网络的动态性,那么,动态网络的表示模型的表示能力就取决于能否准确地基于以往的信息预测结点之间的连接。论文中也使用链接预测来作为模型的指标。
再介绍一些用到的符号: E v , t = { ( e , t ′ ) ∈ E ∣ t ′ < t , v ∈ e } \mathcal{E}_{v, t}=\left\{\left(e, t^{\prime}\right) \in \mathcal{E} \mid t^{\prime}<t, v \in e\right\} Ev,t={
(e,t′)∈E∣t′<t,v∈e}表示在 t t t之前与 v v v相连的边集;下式表示一个CAW,注意其中时间使从大到小的,及新的边放在前面, W [ i ] W[i] W[i]表示第 i i i个结点-时间对。
W = ( ( w 0 , t 0 ) , ( w 1 , t 1 ) , … , ( w m , t m ) ) , t 0 > t 1 > ⋯ > t m , ( { w i − 1 , w i } , t i ) ∈ E for all W=\left(\left(w_{0}, t_{0}\right),\left(w_{1}, t_{1}\right), \ldots,\left(w_{m}, t_{m}\right)\right), t_{0}>t_{1}>\cdots>t_{m},\left(\left\{w_{i-1}, w_{i}\right\}, t_{i}\right) \in \mathcal{E} \text { for all } W=((w0,t0),(w1,t1),…,(wm,tm)),t0>t1>⋯>tm,({
wi−1,wi},ti)∈E for all
3 CAW思路
在CAW之前有Anonymous walks(AW)1,如下图所示,AW很像随机游走,但是又与之有点不同 — 用结点在walks中出现的顺序替代结点的id。这里也给我一个较大的启示:实践中对结点的编号并不能体现graph中的模式,在学习模式的表征时,应尽可能将实践时引入的编号等一些辅助信息与graph的结构、模式等区分开来。但是在实践时有时需要一个明确的表示的,可以借助一个中间的表示,将在不同应用场景下的表示转化为中间表示,用中间表示来表示模式。这有点类似于虚拟机和神经机器翻译中的概念。

CAW中就采用了这种思想,将结点的编号用结点在某个特定位置出现的次数代替。对于给定的两个结点,当预测它们的边时,需要先分别以这两个结点为起点抽取CAWs,再用论文中的方法替换结点的编号,再分别对walks进行编码,最后在预测边的概率。论文中提出的CAW-N主要由以下这些部分组成。
3.1 Causal Anonymous Walk
Causal Anonymous Walk由两部分组成:Causality Extraction和Set-based Anonymization,如下图所示。
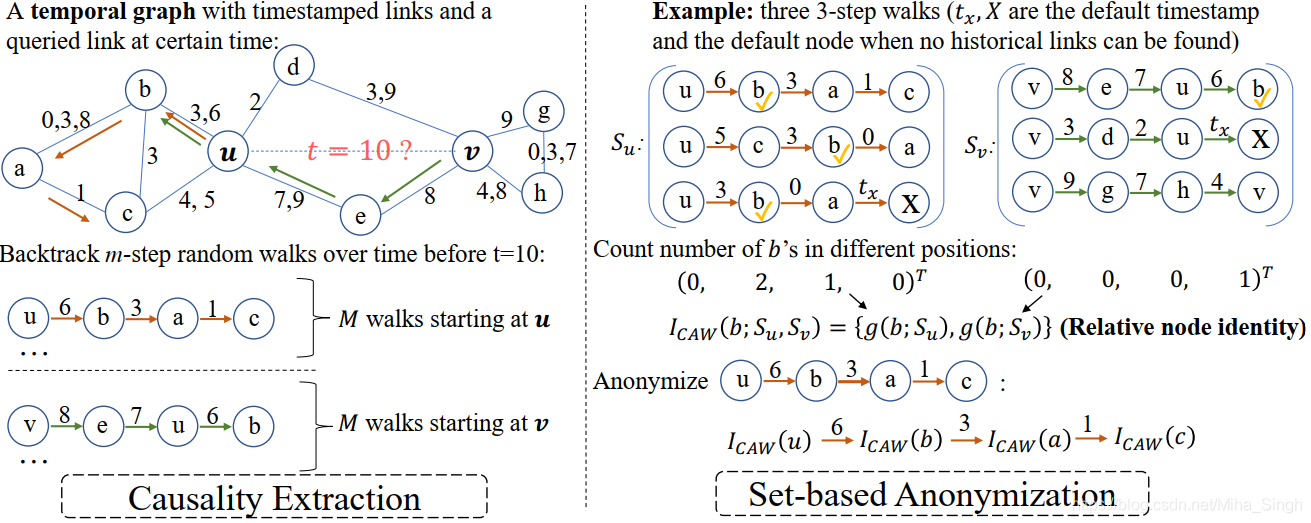
3.1.1 Causality Extraction
这一部分主要用于从动态网络中抽取出walks(这个时候还不能称为Causal Anonymous Walks),抽取算法如下图所示。

对于结点 u 0 , v 0 u_0, v_0 u0,v0,该算法会分别以 u 0 , v 0 u_0, v_0 u0,v0为起点得到长度为 m m m的 M M M条CAWs,分别为 S u , S v S_u, S_v Su,Sv。得到walks后,需要将中的结点id去掉,转化成“中间表示”。转换过程就由Set-based Anonymization完成。
3.1.2 Set-based Anonymization
这一部分就是将walks中的结点id w w w转化为相对结点id I C A W ( w ; { S u , S v } ) I_{CAW}(w; \{S_u,S_v\}) ICAW(w;{
Su,Sv})。1中只是基于一条路径进行转换,这是基于一个假设:任意两个AWs不会共享结点id。显然,该论文中的转换是基于 2 M 2M 2M条CAWs转换的,这也是基于一个假设:\textbf{CAWs之间的关系可能是动态图中模式的关键之处}。因此共享结点id的CAWs就相当于保留了这种关系。 I C A W ( w ; { S u , S v } ) I_{CAW}(w; \{S_u,S_v\}) ICAW(w;{
Su,Sv})定义如下。
I C A W ( w ; { S u , S v } ) ≜ { g ( w , S u ) , g ( w , S v ) } I_{C A W}\left(w ;\left\{S_{u}, S_{v}\right\}\right) \triangleq\left\{g\left(w, S_{u}\right), g\left(w, S_{v}\right)\right\} ICAW(w;{
Su,Sv})≜{
g(w,Su),g(w,Sv)}
对于 w 0 ∈ { u , v } w_0 \in \{u, v\} w0∈{
u,v}, g ( w , s w 0 ) ∈ Z m + 1 g(w, s_{w_0}) \in \mathbb{Z}^{m+1} g(w,sw0)∈Zm+1表示 w w w在集合 S w 0 S_{w_0} Sw0中各个位置出现的次数。于是对于每一个walk可以表示为:
W ^ = ( ( I C A W ( w 0 ) , t 0 ) , ( I C A W ( w 1 ) , t 1 ) , … , ( I C A W ( w m ) , t m ) ) \hat{W}=\left(\left(I_{C A W}\left(w_{0}\right), t_{0}\right),\left(I_{C A W}\left(w_{1}\right), t_{1}\right), \ldots,\left(I_{C A W}\left(w_{m}\right), t_{m}\right)\right) W^=((ICAW(w0),t0),(ICAW(w1),t1),…,(ICAW(wm),tm))
3.2 Neural Encoding for Causal Anonymous Walks
这一步是利用神经网络模型对 W ^ \hat{W} W^进行编码,再将所有编码后的 W ^ ∈ S u ∪ S v \hat{W} \in S_u \cup S_v W^∈Su∪Sv聚集起来。
3.2.1 Encode W ^ \hat{W} W^
文章采样的方法是将walk中的每个元素先进行编码,再输入到序列模型中,如下:
enc ( W ^ ) = RNN ( { f 1 ( I C A W ( w i ) ) ⊕ f 2 ( t i − 1 − t i ) } i = 0 , 1 , … , m ) , where t − 1 = t 0 \operatorname{enc}(\hat{W})=\operatorname{RNN}\left(\left\{f_{1}\left(I_{C A W}\left(w_{i}\right)\right) \oplus f_{2}\left(t_{i-1}-t_{i}\right)\right\}_{i=0,1, \ldots, m}\right), \text { where } t_{-1}=t_{0} enc(W^)=RNN({
f1(ICAW(wi))⊕f2(ti−1−ti)}i=0,1,…,m), where t−1=t0
其中 f 1 , f 2 f_1, f_2 f1,f2分别是 I C A W ( w i ) , t i − 1 − t i I_{CAW}(w_i), t_{i-1} - t_i ICAW(wi),ti−1−ti的编码函数, f 2 f_2 f2就相当于2中的time encoding。 f 1 f_1 f1的实现可以是一个MLP,如 f 1 ( I C A W ( w i ) ) = M L P ( g ( w i , S u ) ) + M L P ( g ( w i , S v ) ) f_1(I_{CAW}(w_i)) = MLP(g(w_i, S_u)) + MLP(g(w_i, S_v)) f1(ICAW(wi))=MLP(g(wi,Su))+MLP(g(wi,Sv))。
3.2.2 Encode S u ∪ S v S_u \cup S_v Su∪Sv
这一步就是聚集各个walk的encoding作为 S u ∪ S v S_u \cup S_v Su∪Sv的encoding来进预测 u , v u, v u,v之间边的概率。论文中给出了两种参考的聚集方式:
- Mean-AGG( S u ∪ S v S_u \cup S_v Su∪Sv): 1 2 M ∑ i = 1 2 M e n c ( W ^ ) \frac{1}{2M} \sum_{i=1}^{2M} enc(\hat{W}) 2M1∑i=12Menc(W^)
- Self-Att-AGG( S u ∪ S v S_u \cup S_v Su∪Sv): 1 2 M ∑ i = 1 2 M s o f t m a x ( { e n c ( W i ^ T ) Q 1 e n c ( W j ^ ) } 1 ≤ j ≤ n ) e n c ( W i ^ ) Q 2 \frac{1}{2M} \sum_{i=1}^{2M} softmax(\{enc(\hat{W_i}^T) Q_1 enc(\hat{W_j})\}_{1 \le j \le n}) enc(\hat{W_i}) Q_2 2M1∑i=12Msoftmax({ enc(Wi^T)Q1enc(Wj^)}1≤j≤n)enc(Wi^)Q2,其中 Q 1 , Q 2 ∈ R d × d Q_1, Q_2 \in \mathbb{R}^{d \times d} Q1,Q2∈Rd×d
再将 S u ∪ S v S_u \cup S_v Su∪Sv的encoding输入到MLP中进行预测。
论文中还提到了如何扩展模型使之能够融入结点/边的属性,将属性拼接到 e n c ( W ^ ) enc(\hat{W}) enc(W^)的输入即可。
5 方法的优势/局限
5.1 优势
- 提出了一个新的动态网络的表征模型CAW-N,能够对temporal network motifs进行编码,且该模型是inductive的
- 提出了一种新的方法来将walks转换到一个中间的表示空间
- CAWs不仅保留了网络中的temporal-spatial结构,还保留了motifs之间的关系,能够捕捉更复杂的模式
5.2 局限
- 论文中只针对连接预测进行了实验,不知道在其他任务如结点分类等任务上效果怎么样
- 实验中对walk的长度取的都比较小,这样提取到的模式可能是比较短期的,较简单的模式
欢迎访问我的个人博客~~~
以及我的公众号【一起学AI】

Reference
Silvio Micali and Allen Zeyuan Zhu. Reconstructing markov processes from independent and anonymous
experiments. Discrete Applied Mathematics, pages 108–122, 2016. ↩︎ ↩︎da Xu, chuanwei ruan, evren korpeoglu, sushant kumar, and kannan achan.
Inductive representation
learning on temporal graphs. In International Conference on Learning Representations (ICLR), 2020. ↩︎