一、回归预测简介
现在我们知道的回归一词最早是由达尔文的表兄弟Francis Galton发明的。Galton在根据上一年的豌豆种子的尺寸预测下一代豌豆种子的尺寸时首次使用了回归预测。他在大量的对象上应用了回归分析,包括人的身高。他注意到,如果双亲的高度比平均高度高的话,则他们的子女也倾向于比平均身高高,但尚不及双亲。孩子的身高向着平均高度回退(回归)。Galton在多项研究上都注意到这个现象,所以尽管这个单词跟数值预测没有任何关系,但是仍然把这种方法称为回归。
二、线性回归
要了解回归方法,我们可以从二维平面上的回归开始先从直观上理解回归的含义。例如平面中有一系列的点(x1,y1),(x2,y2)...(xn,yn),如图1所示。我们可以很直观的发现这些数据有明显的线性关系,回归的目的就是找到这样一条直线,使得所有数据点尽可能的与直线接近。这条直线的方程称为回归方程。这样我们就能够根据直线的回归方程进行预测目标值的预测了。

图1
当推广到多维空间的时候同样可以采用相同的方法,只不过找出来的方程就是一个超平面了,这与我们在支持向量机中所说的超平面是相同的。下面我们将介绍如何求出这样的平面。
2.1线性回归的数学理论
对于含有m维特征向量的数据X(x1,x2,x3...xn),我们可以把回归模型写成如下的形式:

其中x1,x2...xn为n个自变量,ε为误差项,且服从正态分布N(0,0^2)。
b1,b2...bm为这m个自变量的系数。为方便起见,我们对m组实际观测到的样本数据引入矩阵记号:

其中X为模型设计矩阵,Y和ε是随机向量,并且有:
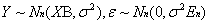 (En为n阶单位矩阵)
(En为n阶单位矩阵)
所以包含n个样本的回归模型式可以写成:
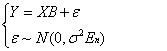
ε是补不可观测到的随机误差向量,B是回归系数构成的向量,系数需要待定。
2.2利用最小二乘法估计回归参数
设βi’为βi(i=1,2...m)的估计值,则当βi为βi’时的误差平方和为:
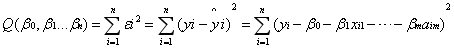
根据极限定理,当Q对B中各参数的偏导数为0时Q取得最小即:
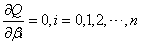
求解上式得:

经过整理之后得到正规方程组为:
由线性代数的知识可知当X为满秩的时候,上式表达式的解为:

2.3 python代码的实现
首先需要定义一个函数standRegress()函数,该函数输入训练集的特征矩阵和标签,返回权重值。如下所示
| def standRegres(xArr,yArr):#标准的回归预测 |
为了直观上的理解,我们仍然采用单变量数据来对回归预测进行说明。数据集为ex0.txt。改文件中每个数据都只包含了一个特征变量和一个目标值。利用上面的函数我们可以求得回归方程的系数,进而利用matlplotlib库中的绘图功能,将回归直线和训练集的散点图在同一个图像中绘制出来,结果如图2所示。
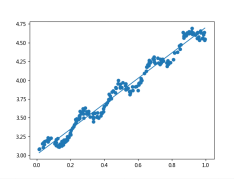
图2 回归直线
三、局部线性加权
从上面的实例来看我们发现所有数据点都较为均匀的分布在直线两侧,但是从直观上来看线性回归并不能很好的拟合数据点。这样模型预测出来的数据就有很大的偏差,不能够得到很好的预测结果。线性回归之所以出现这样的问题是因为在拟合过程中求得是最小均方误差的无偏估计,但是这样容易导致过拟合现象。而有些方法允许在估计中出现一些偏差,从而降低预测的均方误差。局部加权线性回归就是这样一个方法。
局部线性加权算法的思想就是,给待预测点附近的每一个点赋予一定的权重。然后在这个子集上基于最小均方差进行普通的回归。因此将上述线性回归的误差可以改成:

我们对上式求关于B的偏导数,并令其为0。最后计算出的结果为:

其中W是一个权重矩阵,用于给每个数据点赋予权重。在该算法中,使用“核”来对附近点赋予权重。核的类型可以自由选择,但最常用的就是高斯核,高斯核对应的权重为:

这样就够简称了一个只含有对角元素的矩阵B,并且点x与点x(i)越近,w(i,i)就会越大。高斯核函数只有一个待确定的参数k,k值的大小决定了对附近点赋予的权重大小。在x-w的曲线中,k值越大,该图像就越平;反之则图像月陡峭。我们预测点0.5处的附近点在不同k值下的x-w曲线如图3所示。

图3 不同k值下权重与距离的关系图
现在我们再利用和原来一样的数据集,来观察局部线性加权算法的效果。分别令k=0.003,0.01,1.0,结果如图4所示。
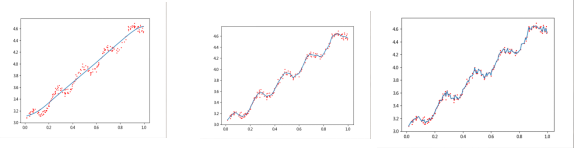
| k=1 k=0.01 k=0.03 |
图4 不同k条件下的局部加权算法结果
加权线性回归由于在预测每一个点的时候都需要重新确定权重,因此计算量非常庞大,这也是加权线性回归预测的一个缺点。因此在实际应用中,我们需要控制好参数k的大小,以免出现欠拟合和过拟合的现象。K值的合适的大小一般跟数据集本身有关,需要根据经验来进行选择。
代码实现:其中定义两个函数lwlr()和lwlrTest()前者用于计算局部线性回归的权重值,后者用于预测给定点预测值。
| def lwlr(testPoint,xArr,yArr,k=1.0):#局部加权线性回归 |
四、岭回归
当数据的特征比样本点的个数还多的时候,不能够再使用之前的线性回归和局部加权线性回归的方法。特征个数比样本点还多(n>m),也就是说输入数据的矩阵X不是列满秩矩阵,而非满秩的矩阵在计算(XTX)-1的时候会出现错误。
例如:对于矩阵X=[1,2,3;4,5,6]。它不是一个列满秩矩阵,我们计算一下XTX的逆,计算结果为(XTX)-1=0。也就是说它的行列式正好为零。在一般情况下都有相同的结果。可以证明r(AA’)=r(A),因此当A不是满秩的时候AA’也不是满秩,因此行列式为0.
为了解决上述出现的问题,统计学家提出了岭回归的概念。简单来说岭回归就是在XTX上加上一个λE(其中E为m*m的单位矩阵)。在这种情况下,回归系数的计算公式会变为:

这里需要指明一下岭回归中的“岭”的含义。岭回归中使用了单位矩阵乘于常量λ,我们观察其中的单位矩阵E可以看到值1贯穿整个对角线,其余元素都是0,在0构成的平面上有一条1组成的“岭”就是岭回归中的“岭”的来由。
我们将仍然利用上面的数据集,对岭回归的统计特性进行检验。下面是岭回归的python的岭回归实现代码:
| def ridgeRegres(xMat,yMat,lam=0.2):#用于计算回归系数 |
其中第一函数ridgeRes()实现了对给定的lambda下的岭回归求解,默认为lambda为0.2。另外为了使用岭回归和缩减技术,首先需要对特征进行标准化处理。第二个函数ridgeTest()中首先对数据进行了标准化处理,使得每一维的特征具有相同的重要性。然后可以输出30个不同lambda下的权重矩阵。然后绘制出岭回归图如图5所示。对于岭回归参数的确定我们可以采用岭迹法,即在岭迹图中个系数都比较稳定的地方所取的lambda值。也可以使用GCV广义交叉方法。

图5 岭回归系数变化图
岭回归最先用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里引入了λ来限制所有w之和,通过引入该惩罚项,能够减少不重要的参数,这种技术就做缩减。岭回归是对最小二乘回归的一个补充,它损失了无偏性,但换回了高的数值稳定性。
参考文献:
【1】机器学习实战
【1】百度百科.岭回归
【2】百度文库.岭回归和lasso
https://wenku.baidu.com/view/a1d929bd50e2524de4187e2a.html