一、引言
二、线性回归算法
2.1 算法介绍
目的:预测数值型的目标值
得到求取目标值的回归方程、回归系数
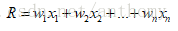
求这些回归系数w的过程称为回归
数据存放在矩阵X,回归系数存放在向量W中
对于给定的输入数据X’,预测结果

如何确定权值W的值呢?我们拥有一些x和对应的y,找出使得误差(预测出的y值与真实y值之间的差值)最小的W,使用该误差的简单累加能使得正差值与负差值相互抵消,这里采用平方误差。


令上式等于零,解得w的最优解 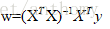
程序中采用NumPy库的矩阵方法OLS(普通最小二乘法),可以实现上述功能。
2.2 程序调试
2.2.1 数据集ex0.txt
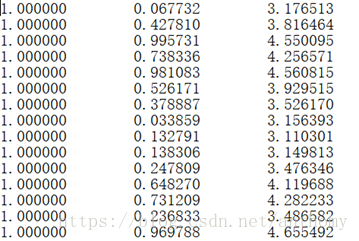
2.2.2 数据可视化(散点图)

2.2.3 线性回归拟合出的最佳回归曲线

2.2.4 预测值yHat序列和真实值y序列的匹配程度,需要计算这两个序列的相关系数。
numpy库中通过命令corrcoef(yEstimate,yActual)来计算预测值与真实值得相关性
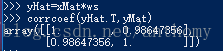
对角线的值为1,yHat和yMat对自己的匹配是最完美的,预测值yHat与实际值yMat的匹配度为98.64%。
三、局部加权线性回归
3.1 算法介绍
线性回归有可能出现欠拟合现象,因为求的是具有最小均方差的无偏估计值,这样就无法得到较好的预测效果,所以我们在估计中引入一些偏差,从而降低预测的均方误差,局部加权线性回归(LWLR)就是其中一种,给待测点附近的点赋予一定的权重,在这个子集上基于最小均方差来进行普通的回归,每次预测需要实现选出对应的数据子集。
解出回归系数w: 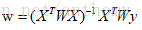
LWLR使用“核函数“来对附近的点赋予更高的权重,核函数的类型可以自由选择,这次仍采用高斯核函数
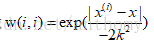
这样就构建了一个只含有对角元素的权重矩阵W,并且点x与x(i)越近,w(i,i)将会越大,上述核函数公式还包含参数k,k决定了对附近的点赋予多大的权重。
LWLR也存在一个问题,增加了计算量,因为对每个点做预测是都必须使用整数个数据集。
3.2 程序调试
3.2.1 数据集ex0.txt
数据可视化见2.2.2
3.2.2 k在三种取值下的拟合结果
<1>k=1.0

此时权值很大,如同将所有的数据视为等权重,得出的最佳拟合直线与标准回归一致,出现欠拟合。
<2>k=0.01

得到了较好的效果,抓住了数据的潜在模式。
<3>k=0.003
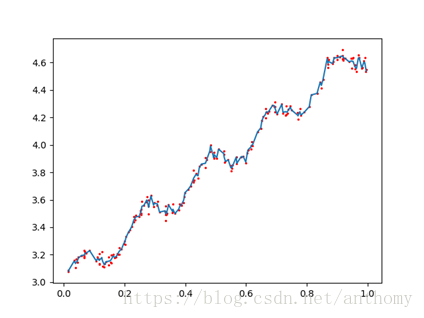
纳入了很多的噪声点,拟合的直线与数据点过于接近,出现过拟合。
四、预测鲍鱼的年龄
4.1 数据集 abalone.txt
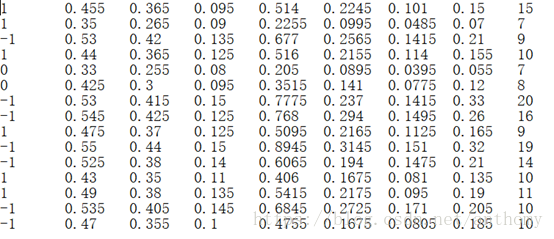
4.2 分析预测误差
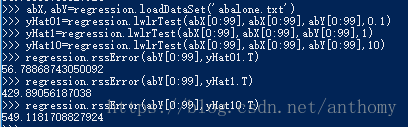
可以看出,使用较小的核函数会得到较低的误差,但不能再所有的数据集上使用最小的核函数,因为可能会造成过拟合,对新数据集不一定能达到最好的预测效果。
4.3 新数据集上的误差分析
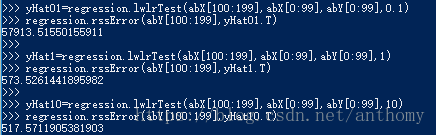
核函数大小等于10时的误差最小,但是在训练数据集中误差是最大的。
4.4 简单线性回归的误差分析

简单线性回归达到了与 LWLR类似的效果。
五、总结与体会
六、参考文献
【1】《机器学习实战》
非常感谢阅读!如有不足之处,请留下您的评价和问题。