原理:
逻辑回归处理的是分类问题,具体来说,是处理二分类问题。为了实现逻辑回归分类器,我们可以在线性回归的基础上。添加一个sigmoid函数,进而得到一个范围在0~1之间的数值。任何大于0.5的数据会被分为1类,小于0.5即被分为0类。至于为什么会用到sigmoid函数,简单来说,是为了将标签归类为[0,1]的范围内;深层原因,sigmoid函数的使用是由指数分布族决定的。
预测值为:
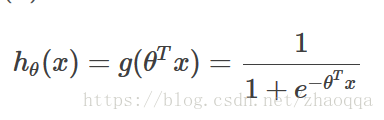


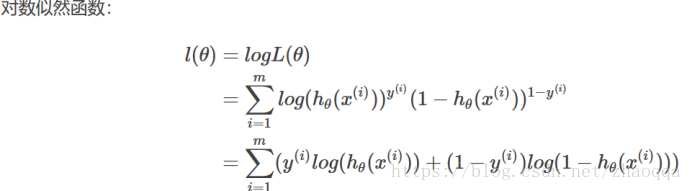


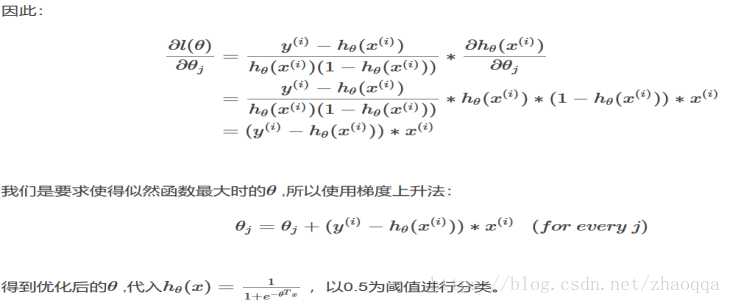
优点:
1)速度快,适合二分类问题
2)简单易于理解,直接看到各个特征的权重
3)能容易地更新模型吸收新的数据
缺点:
对数据和场景的适应能力有局限性,不如决策树算法适应性那么强。
问 逻辑回归的代价函数为什么用最大似然估计而不是最小二乘法?
1.可以证明逻辑归回的最小二乘法的代价函数不是关于分布参数θ的凸函数,求解过程中,会得到局部最优,不容易得到全局最优。但逻辑回归的对数似然函数可证明是关于θ的凸函数,且有最大值。
2.因为逻辑回归不是一种回归,而是一种分类算法。而逻辑回归的假设函数是属于指数分布族,且逻辑回归的样本给予满足伯努利分布而进行训练的,最大似然估计的出发点就是使得当前样本发生的可能性最大化,反向支持逻辑回归样本满足伯努利分布,而最小二乘法只是让预测值和真实值更拟合,而最大似然估计是保证计算出的特征值发生的概率正确率最大化,最大似然估计更满足逻辑回归是一种分类器。


Penalty:惩罚项,str类型,可选参数为L1与L2,默认为为L2.用于指定惩罚项中使用的规范。L1规范假设的模型参数是满足拉普拉斯分布,L2假设的模型参数满足高斯分布。
C:正则化系数λ的倒数,float类型,默认为1.0.必须是正浮点数。像SVM一样,越小的数值表示越强的正则化。
简单介绍一下正则化:
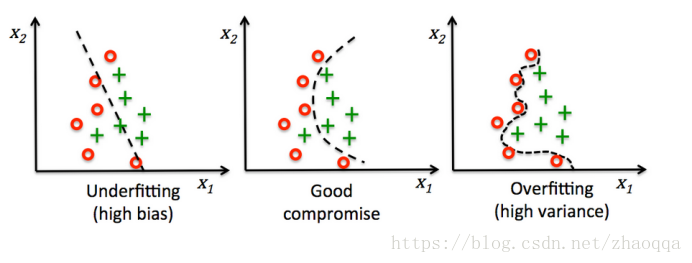

解决上述问题的一个方案就是正则化。正则化可以调整模型的复杂度,是解决共线性问题的一个很有用的方法,可以过滤掉数据中的噪声,最终防止过拟合。
原理:引入额外的信息对极端参数权重做出惩罚。
常用的正则化方法:L1正则化,L2正则化
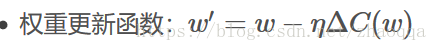
L1正则化:
在原始的代价函数C后面加上一个L1正则项,即所有权重w的绝对值的和乘以λ/n.
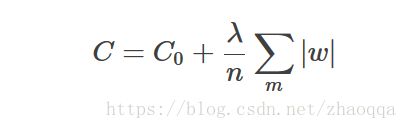
计算导数:
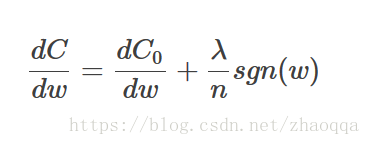
权重w的更新公式
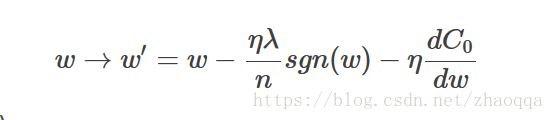

L2正则化:
L2正则化就是在代价函数后面再加上一个正则化项:
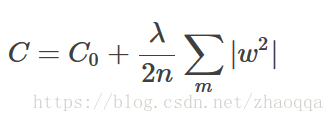
所有参数w的平方的和,除以训练集的样本大小n,λ就是正则化项系数。
为什么会有系数1/2?仅仅是为了后面求导的方便而已。
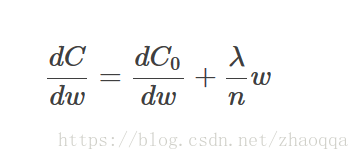
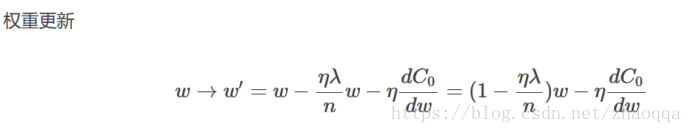
在不使用L2正则化时,求导结果中w前的系数为1,现在w前面的系数为1-λη/n,因为η,λ,n都是正的,所以1-λη/n小于1,它的效果是减小w,这就是权重衰减的由来。
更新的权重w从某种意义上来说,表示网络的复杂度更低,对数据的拟合刚刚好。而在实际应用中,也证明了这一点,L2正则化的效果往往好于未经正则化的效果。
使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)
