【机器学习实战】利用回归算法实现电流预测
实验背景
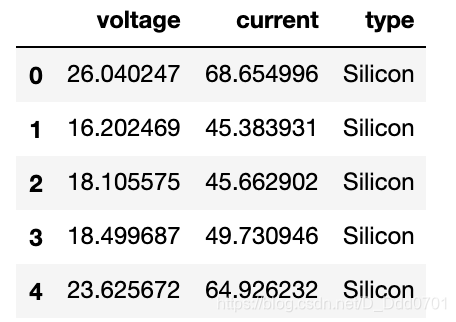
变压器是否稳定可靠决定着一套电力系统能否正常运转。这里有150组数据,包含了vlotage(电压),current(电流),type(类型),三个参数,其中type包含了50个Carbon,50个Silicon,50个Germanium数据。我们需要用这150组数据实现不同类型的电流预测。
以下是数据概览:
涉及到的方法
1、Pandas对数据进行整理;
2、线性回归模型预测;
3、算法的评价——回归方程的损失函数(拟合度评价);
4、程序优化。
思路
我们需要实现电流的预测,所以学习的“答案”应该是电流,电压和类型是“习题”。
那么本项目涉及两个难点:
1、type是文本类型,监督学习的特征值应该是数字类型,这里需要用get_dummies对文本分类进行虚拟转化。
2、均方误差来进行算法评价,如果较差则需要优化程序。
实战
引入类库
import seaborn as sns
import pandas as pd
sns.set(font_scale=1.5)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model #算法
#评估算法
from sklearn.metrics import mean_squared_error #均方误差,损失函数
from sklearn.metrics import mean_absolute_error #绝对值
引入数据集
df_vc = pd.read_csv("voltage_current_data.csv")
print(df_vc)# vlotage:电压,current:电流,type:类型

利用Pandas处理数据
设置虚拟变量
# 电压(voltage)和材料(type)是数据,电流(current)是结果
two_features = ['voltage', 'type'] #创建列表list,设置索引
two_feature_data = pd.DataFrame(df_vc[two_features]) #创建一个DataFrame,仅保留voltage和type
dummies = pd.get_dummies(two_feature_data['type']) #将‘type’变量设置为虚拟变量
data_w_dummies = pd.concat([two_feature_data, dummies], axis=1)#连接两个DataFrame,其中axis=1代表水平连接
data_w_dummies
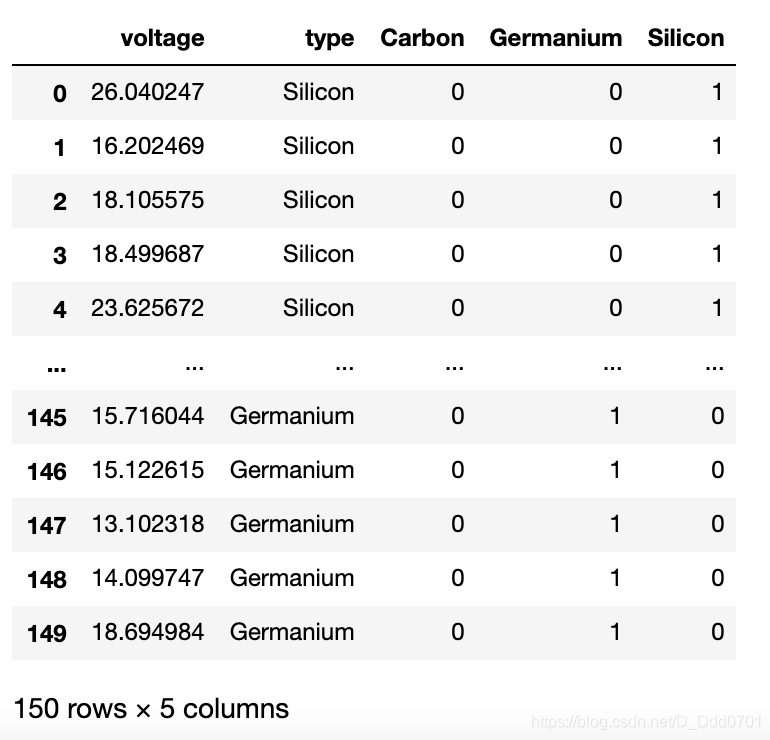
这样,就把三个类型的虚拟变量设置出来。这里有一个问题需要思考:这三个类型的权重是否一致。在设置虚拟变量时,如果权重不一致,需要考虑加权问题。
删除原有Type列
data_w_dummies = data_w_dummies.drop(['type'], axis=1)
#type已经recoding成为虚拟变量,删除原有的tpye变量
建立机器学习模型
# 创建线性回归模型
f_with_type = linear_model.LinearRegression()
# 把data_w_dummies和电流训练
f_with_type.fit(data_w_dummies, df_vc['current'])
评价机器学习
权重值
f_with_type.coef_
#voltage、Carbon、Germanium、Silicon分别的权重值
array([ 4.03744567, -1.04996567, 26.83843466, -25.78846899])
θ0值
线性回归实现预测,其实是多特征加权求解的过程,即:f(x)=θ0 + θ1X1 + θ2X2 + … + θnXn。这一个方程可以用矩阵的形式写出来:f(x)=θ0 + [θ1,θ2,…,θn]T * [X1,X2,…,Xn],可以依靠计算机强大的算力,把[θ1,θ2,…,θn]T求解,得出最优值,那么这个方程即为预测曲线。具体的计算方法有两种:极大似然法和最小二乘法。在这里不对数学推导做展开。
# θ0值
f_with_type.intercept_
-0.35351803812466187
均方误差(MSE)
mean_squared_error(f_with_type.predict(data_w_dummies), df_vc['current'])
62.54279342259103
这个均方误差过大,说明拟合的程度不好。
可视化展示学习效果
因为MSE评价出来机器学习的效果不是特别好,所以我们大概的画一下可视化图,看看情况怎么样。
plt.figure(figsize=(10,6), dpi = 100)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('电流预测')
plt.xlabel('电压')
plt.ylabel('电流')
plt.scatter(data_w_dummies['voltage'],df_vc['current'], label='实际电流')
plt.plot(data_w_dummies['voltage'],f_with_type.predict(data_w_dummies),'r--',label='预测电流')
plt.legend()
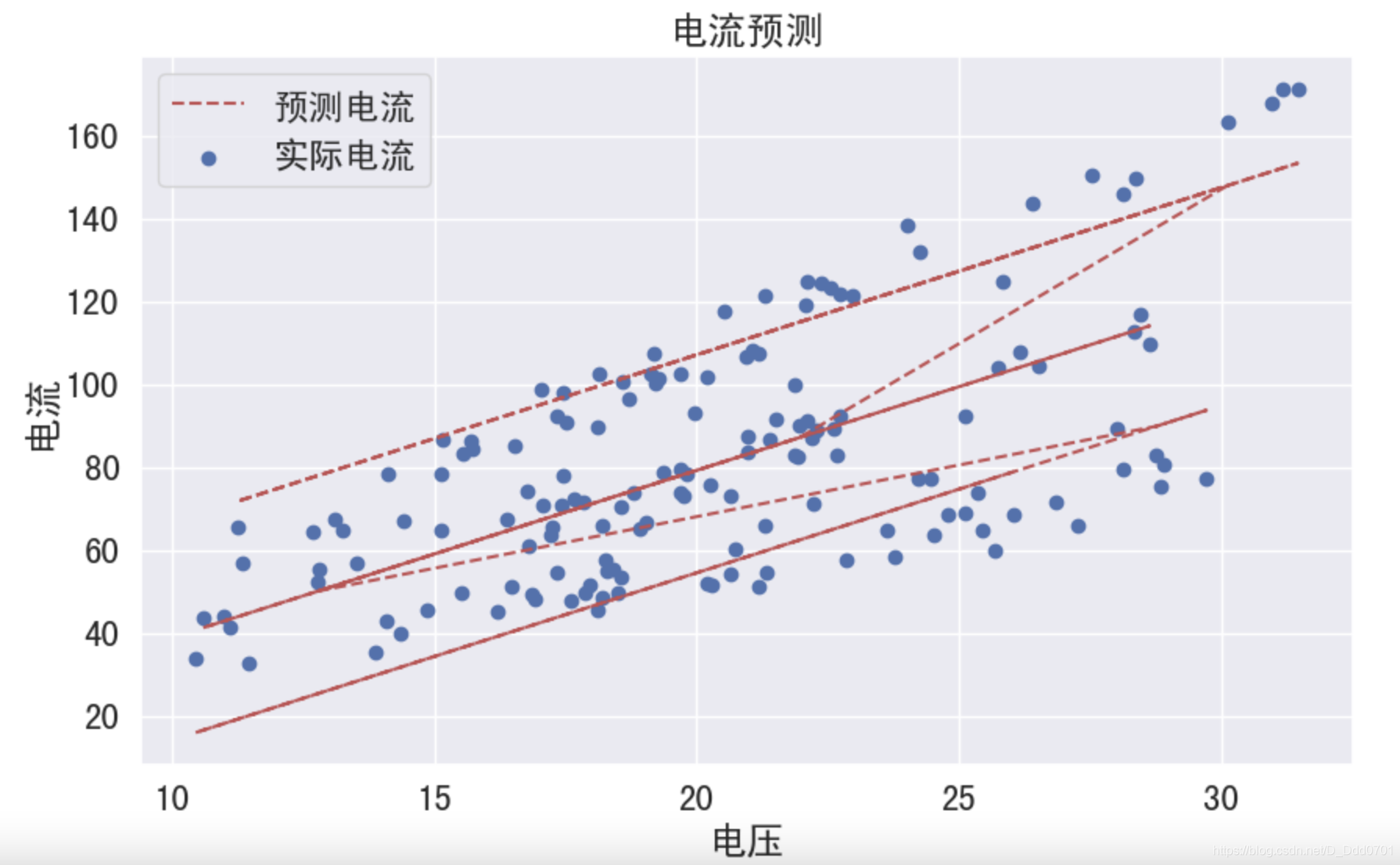
我们发现右上角和下方很多点都没有拟合进去,所以误差大是必然的。所以这里必须进行学习策略优化。
模型2
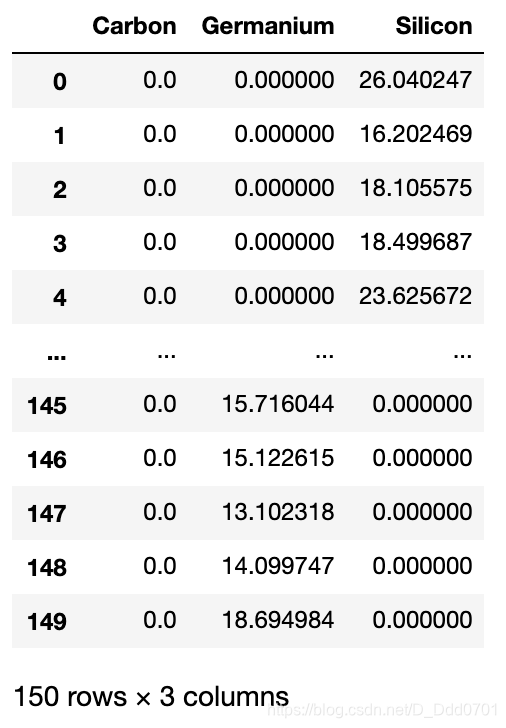
我们可以把电压和虚拟变量做乘法,这样就把一个4维的数据变成了3维。
data_w_scaled_dummies = data_w_dummies.copy()
data_w_scaled_dummies['Carbon'] = data_w_scaled_dummies['Carbon'] * data_w_scaled_dummies['voltage']
data_w_scaled_dummies['Germanium'] = data_w_scaled_dummies['Germanium'] * data_w_scaled_dummies['voltage']
data_w_scaled_dummies['Silicon'] = data_w_scaled_dummies['Silicon'] * data_w_scaled_dummies['voltage']
data_w_scaled_dummies = data_w_scaled_dummies.drop(['voltage'], axis=1)
data_w_scaled_dummies
# 这里是一个降维的思路,把电压和3个材料压缩成三个维度
检查均方误差
f_vc_with_scaled_type = linear_model.LinearRegression()
f_vc_with_scaled_type.fit(data_w_scaled_dummies, df_vc['current'])
mean_squared_error(f_vc_with_scaled_type.predict(data_w_scaled_dummies), df_vc['current'])
25.714214023084757
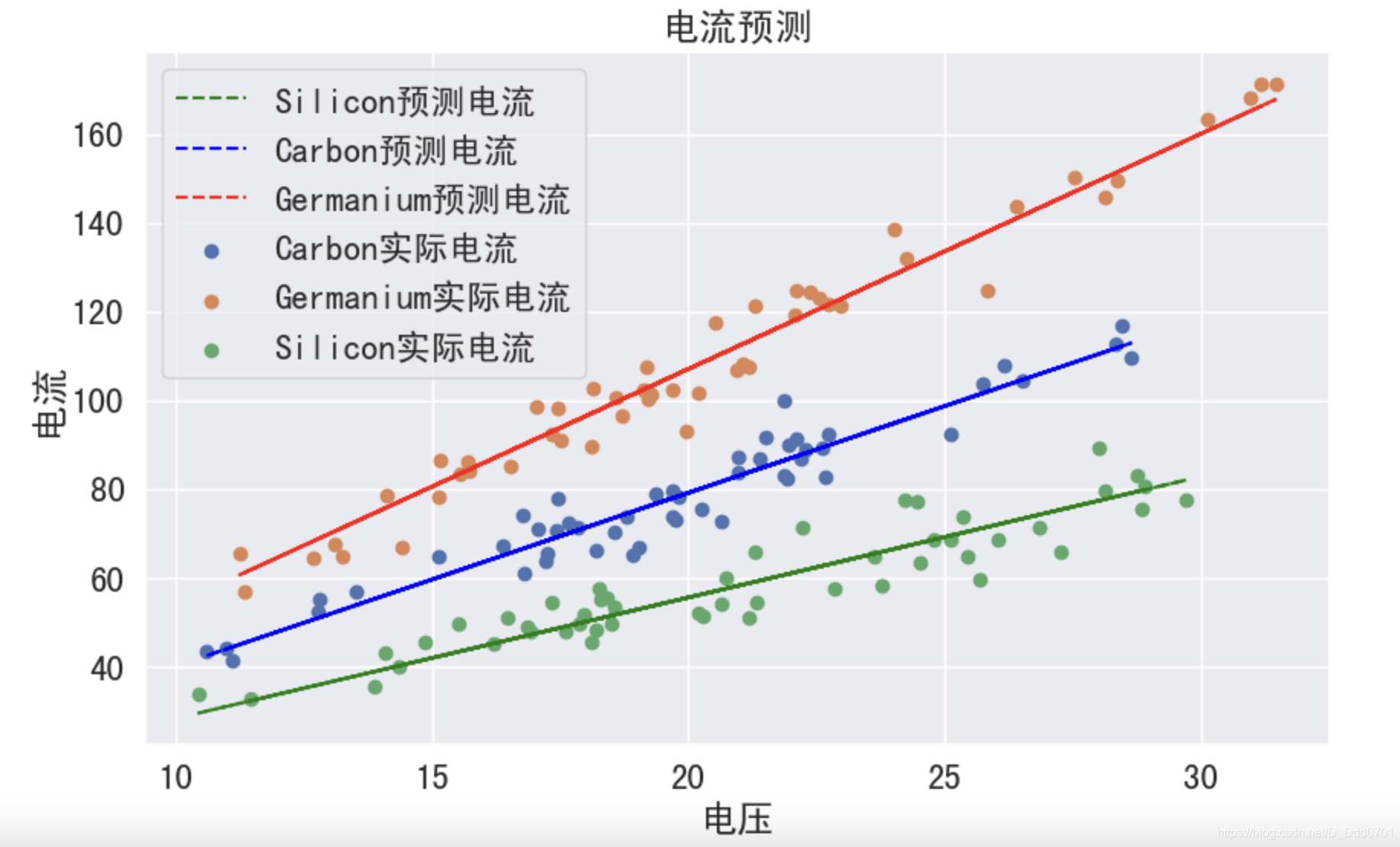
均方误差明显变小,说明降维之后确实对机器学习的效果有了提升。
权重值
f_vc_with_scaled_type.coef_#Carbon、Germanium、Silicon分别的权重值
array([3.9045347 , 5.29989642, 2.72432338])
θ0值
f_vc_with_scaled_type.intercept_
1.2044777216614193
绘制图像
# 三个材料分别是1-50,51-100,101-150行
# 取出不同材料对应的电流值进行分别绘图
plt.figure(figsize=(10,6), dpi = 100)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('电流预测')
plt.xlabel('电压')
plt.ylabel('电流')
plt.scatter(data_w_scaled_dummies['Carbon'][50:100],df_current['current'][50:100], label='Carbon实际电流')
plt.scatter(data_w_scaled_dummies['Germanium'][100:150],df_current['current'][100:150], label='Germanium实际电流')
plt.scatter(data_w_scaled_dummies['Silicon'][0:50],df_current['current'][0:50], label='Silicon实际电流')
plt.plot(data_w_scaled_dummies['Silicon'][0:50],f_vc_with_scaled_type.predict(data_w_scaled_dummies)[0:50],c='green',linestyle='--',label='Silicon预测电流')
plt.plot(data_w_scaled_dummies['Carbon'][50:100],f_vc_with_scaled_type.predict(data_w_scaled_dummies)[50:100],c='blue',linestyle='--',label='Carbon预测电流')
plt.plot(data_w_scaled_dummies['Germanium'][100:150],f_vc_with_scaled_type.predict(data_w_scaled_dummies)[100:150],c='red',linestyle='--',label='Germanium预测电流')
plt.legend()