SoftMax---学习笔记
softMax分类函数
首先给一个图,这个图比较清晰地告诉大家softmax是怎么计算的。
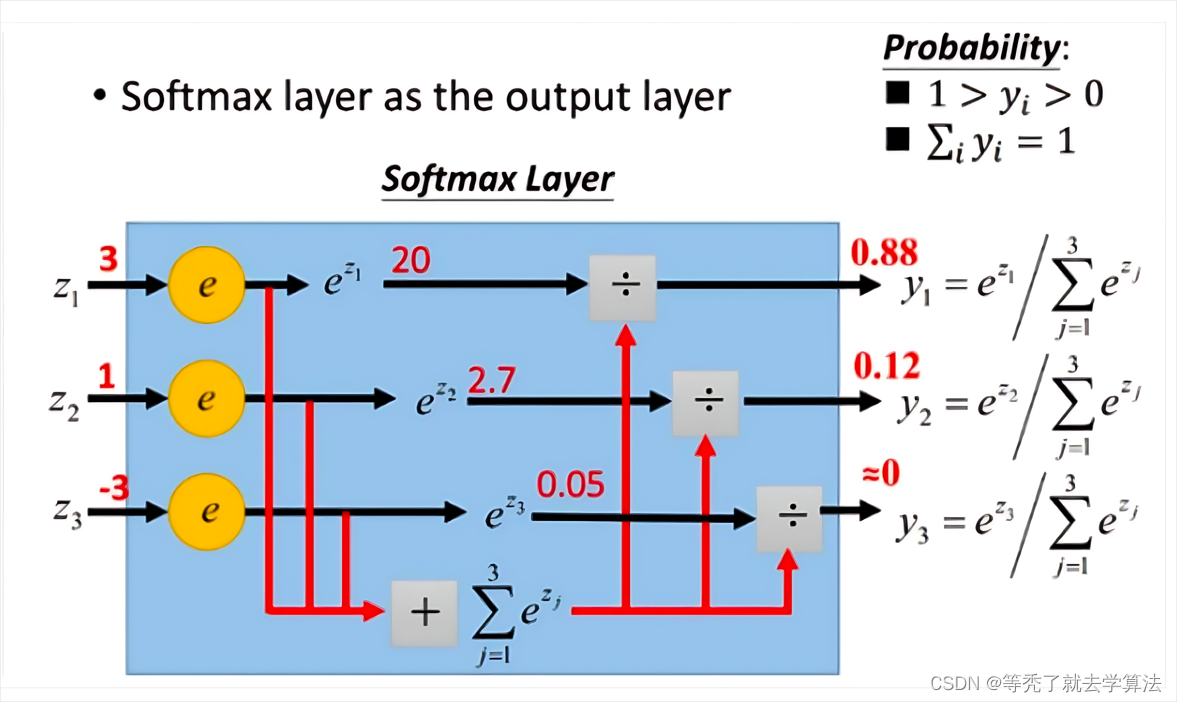 (图片来自网络)
(图片来自网络)
定义:
给定以歌 n × k n×k n×k矩阵 W = ( w 1 , w 2 , . . . , w k ) W=(w_1,w_2,...,w_k) W=(w1,w2,...,wk),其中, w j ∈ R n w_j\in R^n wj∈Rn为 n × 1 n×1 n×1列向量( 1 ≤ j ≤ k 1\leq j\leq k 1≤j≤k),Softmax模型 h w : R n → R k h_w:R^n →R^k hw:Rn→Rk为:
h W ( x ) = ( e < w 1 , x > ∑ t = 1 k e < w t , x > , e < w 2 , x > ∑ t = 1 k e < w t , x > , . . . , e < w k , x > ∑ t = 1 k e < w t , x > ) ( 样本 m × k ) h_W(x)=(\frac{e^{<w_1,x>}}{\sum_{t=1}^{k}e^{<w_t,x>}},\frac{e^{<w_2,x>}}{\sum_{t=1}^{k}e^{<w_t,x>}},...,\frac{e^{<w_k,x>}}{\sum_{t=1}^{k}e^{<w_t,x>}})_{(样本m×k)} hW(x)=(∑t=1ke<wt,x>e<w1,x>,∑t=1ke<wt,x>e<w2,x>,...,∑t=1ke<wt,x>e<wk,x>)(样本m×k)
样本 x 1 x_1 x1的softmax值为:
h W ( x 1 ) = ( e < w 1 , x 1 > ∑ t = 1 k e < w t , x 1 > , e < w 2 , x 1 > ∑ t = 1 k e < w t , x 1 > , . . . , e < w k , x 1 > ∑ t = 1 k e < w t , x 1 > ) ( 1 × k ) h_W(x_1)=(\frac{e^{<w_1,x_1>}}{\sum_{t=1}^{k}e^{<w_t,x_1>}},\frac{e^{<w_2,x_1>}}{\sum_{t=1}^{k}e^{<w_t,x_1>}},...,\frac{e^{<w_k,x_1>}}{\sum_{t=1}^{k}e^{<w_t,x_1>}})_{(1×k)} hW(x1)=(∑t=1ke<wt,x1>e<w1,x1>,∑t=1ke<wt,x1>e<w2,x1>,...,∑t=1ke<wt,x1>e<wk,x1>)(1×k)
且可知 ∑ 1 k h w ( x 1 ) = 1 \sum_1^kh_w(x_1) = 1 1∑khw(x1)=1
类别数k要小于特征维度n
如果类别数大于特征维度,那么就会出现过多的未知参数需要学习,导致模型过于复杂,难以训练和泛化。因此,通常是将类别数设定为特征维度的一个较小的值,以保证模型的简洁性和可行性。
softmax分类损失函数
交叉熵的理论部分在上一篇文章:Logistic回归
前面提到,在多分类问题中,我们经常使用交叉熵作为损失函数
L o s s = − ∑ t i l n y i Loss = -\sum t_ilny_i Loss=−∑tilnyi
其中 t i t_i ti表示真实值, y i y_i yi表示求出的softmax值。当预测第i个时,可以认为 t i t_i ti=1.此时损失函数变成了 L o s s i = − l n y i Loss_i=-lny_i Lossi=−lnyi
代入 y i = h W ( x i ) y_i=h_W(x_i) yi=hW(xi),求梯度
▽ L o s s i = y i − 1 ▽Loss_i=y_i-1 ▽Lossi=yi−1上面的结果表示,我们只需要正向求出 y i y_i yi,将结果减1就是反向更新的梯度,导数的计算是不是非常简单!
总结一下:


