上一篇讲了线性可分的SVM推导,现在讲一讲基本线性可分的情形,后面还会介绍多分类的使用以及核函数的使用。
outlier 的处理
给定数据集 ,当样本数据大部分为线性可分的,存在少量异常值使得数据线性不可分,或者导致分离超平面被挤压,可以通过一些方法仍然按照线性可分的方式处理,异常值的情况如下图所示:
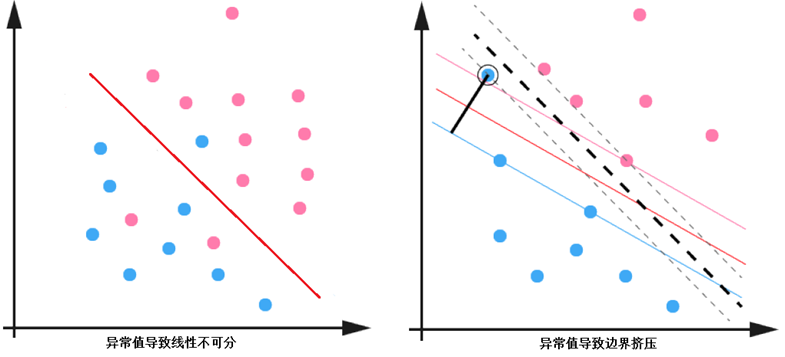
以上情况意味着某些样本点的函数间隔并不满足大于 1 的要求。为了解决这个问题,为每个样本引入一个松弛变量, 使得函数间隔可以小于 1 ,即满足
,这里显然
不能任意大,因为那会导致任意样本点都满足要求,所以要把优化目标改成如下的形式:
上面将不等式约束都已经化成了的形式了,为方便使用拉格朗日乘子法与KKT条件。
这里 叫做惩罚参数,上述的不等式约束记做
的形式,同样通过对偶的形式求解,首先构造拉格朗日函数:
拉格朗日函数中的乘子 , 且
,很明显的有:
因此原始问题转化为:
对于上述问题应用对偶可得:
接下来求解对偶问题,对于极小部分的参数 求导:
将以上结果带入对偶问题,极小部分便得到一个关于 的函数:
注意这里根据 与
消去了
。
使原始问题满足KKT条件,则原问题与对偶问题具备强对偶性。(其实在这里可以通过Slater条件成立推出强对偶性,再从强对偶性推出原问题满足KKT条件,Slater条件为两个,1是原问题为凸优化问题,这个显而易见。2是原问题存在严格满足不等式约束的解,这个也是显而易见的,对于所有不是支持向量的点,都是严格满足这个条件的。故Slater条件是成立的。)
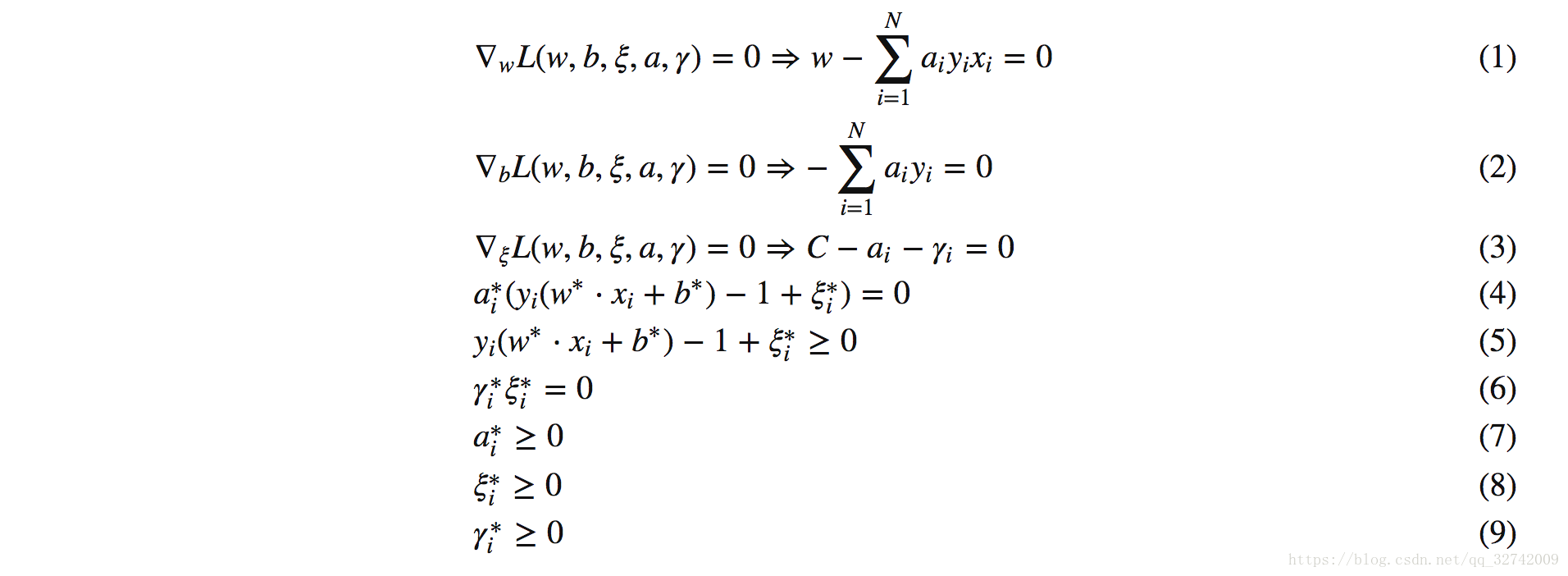
联立KKT条件与对偶问题约束最后可求解得出
首先由 KKT 条件 (1) 可得:
根据 KKT 条件(3) (4) (6) (9)可知若 ,则
,且存在
,使得:
因此便可求得 :
至此,可以总结出带有异常值的线性可分 SVM 的算法1.3:
Algorithm 1.3

下图中实线为分离超平面,虚线为间隔边界,且有间隔边界与分离超平面的函数距离为1,几何距离为 。在线性不可分的情况下,求解得到
的分量
对应的样本实例
中的
称为支持向量,这时的支持向量要比线性可分复杂一些,如下图的点,以下支持向量点到间隔边界的几何距离均已标注出为
。这个几何距离是这样计算的,点
到分离超平面的函数距离为
, 而分离超平面与间隔边界的函数距离为 1 ,所以点
到间隔边界的距离为
,几何距离只需除以
即可得到结果。
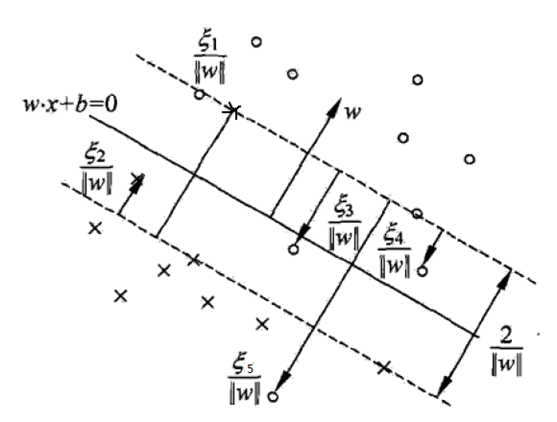
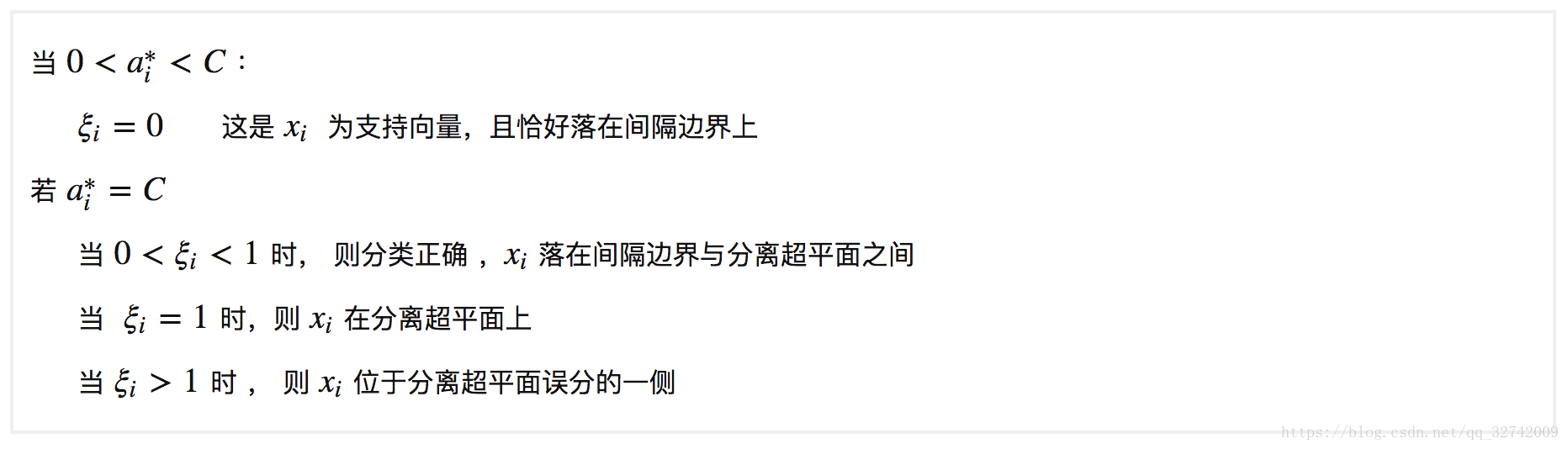
可见这时候的支持向量或者分布在间隔边界上,或者在间隔边界与超平面之间,或者在分离超平面误分的一侧。 根据 KKT 条件可以得出一些很有意思的结论,当 时,根据 KKT 条件 (3) 可得
,即
,又由于
可得
,根据 KKT 条件 (4) 可得
,所以当
时,可得
,这时样本便为支持向量,且落在间隔边界上;当
时且
,这时便为分类正确的且落在间隔边界之后的点,至于
的情况,根据
的不同取值,可分为不同的情况,总结起来便有:
至此,带有异常值的非线性可分的情况也解决了,但是还需要注意的是数据集是完全非线性可分的。这时便需要引入核方法了。核方法并不是 SVM 的专利,其可以解决一系列机器学习问题。
多分类
至于 K 分类问题 (K>2) ,最简单的方式便是 one-vs-all 的方法,如下图所示,该方法共训练 K 个分类器,对于待分类样本点,分别使用这 K 个分类器进行分类,对于样本 分类的计算如下:
,若只有一个 +1 出现,则其为样本对应类别 k ;但实际情况下构造的决策函数总是有误差的,此时输出不只一个 +1 (不只一类声称它属于自己),或者没有一个输出为 +1 (即没有一个类声称它属于自己),这时比较则比较
输出值,最大者对应类别为样本
的类别 k 。
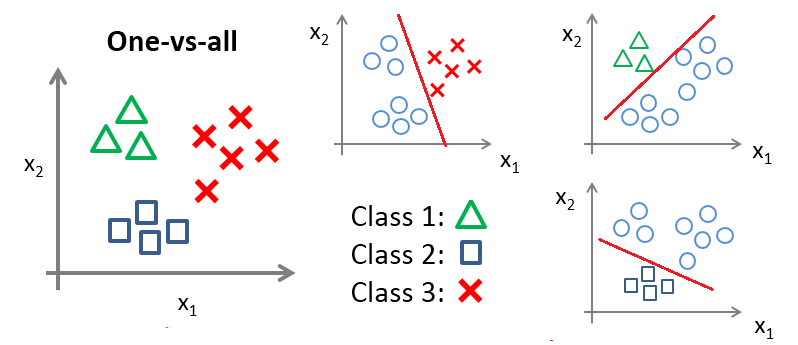
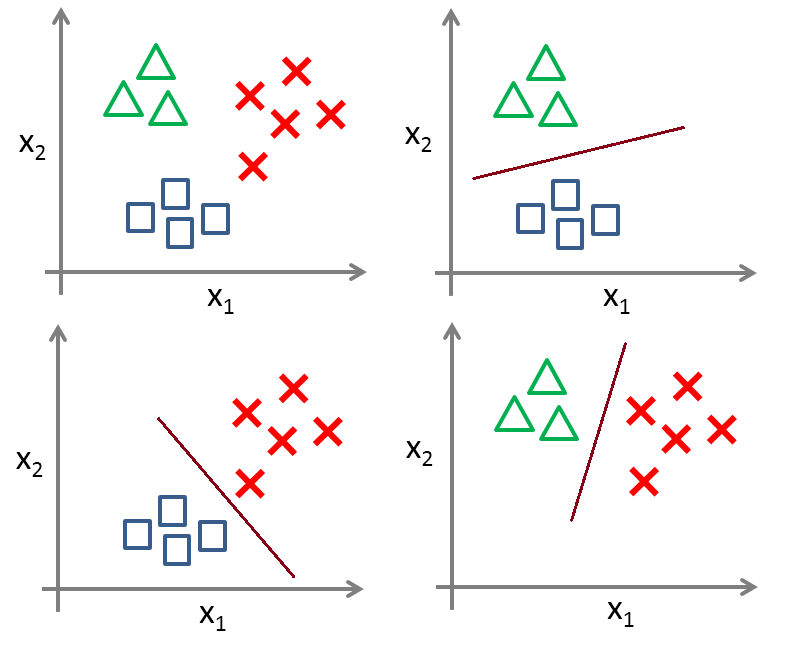
或者采用 LIBSVM 中 one-vs-one 的方法,其做法是在任意两类样本之间设计一个SVM,因此 k 个类别的样本就需要设计 个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。比如说 A,B,C 三类。在训练的时候针对 (A,B) (A,C) (B,C) 所对应的样本作为训练集,然后得到三个模型,在测试的时候,对应的分别对三个模型进行测试,然后采取投票形式得到最后的结果,如下图所示:
再就是直接使用 Hinge Loss 进行多分类了,这个接下来也会详细介绍。
参考文章:
致谢ooon大神,从他的博文中学到了很多东西!