- 超多分类的Softmax
参考:https://zhuanlan.zhihu.com/p/34404607
https://zhuanlan.zhihu.com/p/35027284
http://manutdzou.github.io/2017/08/20/loss-design.html
2014年CVPR两篇超多分类的人脸识别论文:DeepFace和DeepID
Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification [C]// CVPR, 2014.

DeepFace:4.4M训练集,训练6层CNN + 4096特征映射 + 4030类Softmax,综合如3D Aligement, model ensembel等技术,在LFW上达到97.35%。
Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes [C]// CVPR, 2014.
DeepID:20W训练集,训练4层CNN + 160维特征映射 + 10000类Softmax,加多尺度多patch特征,加Joint Bayesian分类器,在LFW上达到97.45%。
以上两个早期深度人脸识别方法,框架为CNN + Softmax,以“超多分类”这样一种比较难的任务训练CNN,强迫网络在第一个FC层形成比较紧凑的,判别力很强的深度人脸特征,之后用于人脸识别。
Softmax Cross-Entropy Loss
简称为softmax loss,公式如下,xi表示第i维特征,分子中的指数项表示xi预测指为yi所得的分数。用softmax函数做压缩,用来表示多类预测的概率,整体是将其带入交叉熵公式所得。m表示对应的mini-batch样本数。偏置b分析时候可以省略影响不大,因为其和输入的xi没有关系。
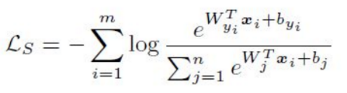
如果cnn网络使用softmax loss的话,可以将其分类前提取到的特征xi投影到2d平面上,如下图所示。由于fc层其实就是一个近似线性的分类器,从下图可以看出其决策边界,可以注意到,类间基本可分,但是类内分布并不均匀。

标准CNN训练流程如下图所示:

Softmax优缺点
Softmax是soft(软化)的max。在CNN的分类问题中,我们的ground truth是one-hot形式,下面以四分类为例,理想输出应该是(1,0,0,0),或者说(100%,0%,0%,0%),这就是我们想让CNN学到的终极目标。
网络输出的幅值千差万别,输出最大的那一路对应的就是我们需要的分类结果。通常用百分比形式计算分类置信度,最简单的方式就是计算输出占比,假设输出特征是
,这种最直接最最普通的方式,相对于soft的max,在这里我们把它叫做hard的max:

而现在通用的是soft的max,将每个输出x非线性放大到exp(x),形式如下:

hard的max和soft的max到底有什么区别呢?看几个例子

相同输出特征情况,soft max比hard max更容易达到终极目标one-hot形式,或者说,softmax降低了训练难度,使得多分类问题更容易收敛。
到底想说什么呢?Softmax鼓励真实目标类别输出比其他类别要大,但并不要求大很多。对于人脸识别的特征映射(feature embedding)来说,Softmax鼓励不同类别的特征分开,但并不鼓励特征分离很多,如上表(5,1,1,1)时loss就已经很小了,此时CNN接近收敛梯度不再下降。
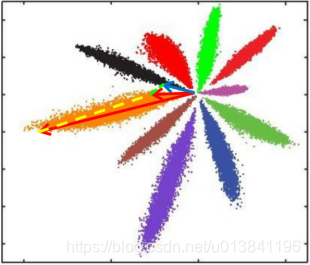
Softmax Loss训练CNN,MNIST上10分类的2维特征映射可视化如下:

不同类别明显分开了,但这种情况并不满足我们人脸识别中特征向量对比的需求。人脸识别中特征向量相似度计算,常用欧式距离(L2 distance)和余弦距离(cosine distance),我们分别讨论这两种情况:
L2距离: L2距离越小,向量相似度越高。可能同类的特征向量距离(黄色)比不同类的特征向量距离(绿色)更大
cos距离: 夹角越小,cos距离越大,向量相似度越高。可能同类的特征向量夹角(黄色)比不同类的特征向量夹角(绿色)更大
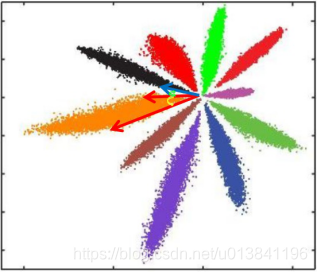
总结来说:
1.Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
2.但Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠。
3.所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
Softmax loss实现:
def get_softmax_loss(features,one_hot_labels):
prob = tf.nn.softmax(features + 1e-5)
cross_entropy = tf.multiply(one_hot_labels,tf.log(tf.clip_by_value(prob,1e-5,1.0)))
loss = -tf.reduce_mean(cross_entropy)
return loss