1.前言
看了Andrew ng的课程,用python sklearn总结一下逻辑回归——多分类,数字识别。
2.python代码
(1)数据集用的sklearn自带,数字0~9分类
(2)采用和上篇博客一样的算法,稍作调整
(3)执行代码如下multi_class.py:
import util.logistic_regression as lr
from sklearn import datasets
def multi_class_classification():
digits = datasets.load_digits()
x = digits['data']
y = digits['target']
lr.logistic_regression(x, y)
multi_class_classification()(4)作调整后的逻辑回归算法util.logistic_regression.py
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 测试集,画图对预测值和实际值进行比较
def test_validate(x_test, y_test, y_predict, classifier):
x = range(len(y_test))
plt.plot(x, y_test, "ro", markersize=5, zorder=3, label=u"true_v")
plt.plot(x, y_predict, "go", markersize=8, zorder=2, label=u"predict_v,$R^2$=%.3f" % classifier.score(x_test, y_test))
plt.legend(loc="upper left")
plt.xlabel("number")
plt.ylabel("true?")
plt.show()
def logistic_regression(x, y):
# 对数据的训练集进行标准化
ss = StandardScaler()
x_regular = ss.fit_transform(x)
# 划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(x_regular, y, test_size=0.1)
lr = LogisticRegression()
lr.fit(x_train, y_train)
# 模型效果获取
r = lr.score(x_train, y_train)
print("R值(准确率):", r)
# 预测
y_predict = lr.predict(x_test) # 预测
print(y_predict)
print(y_test)
# 绘制测试集结果验证
test_validate(x_test=x_test, y_test=y_test, y_predict=y_predict, classifier=lr)3.验证结果
(1)红点是测试集真实结果,绿点是预测结果,红框部分出现了红绿点不重合部分数据,看到正确率r=0.967,预测正确/总数
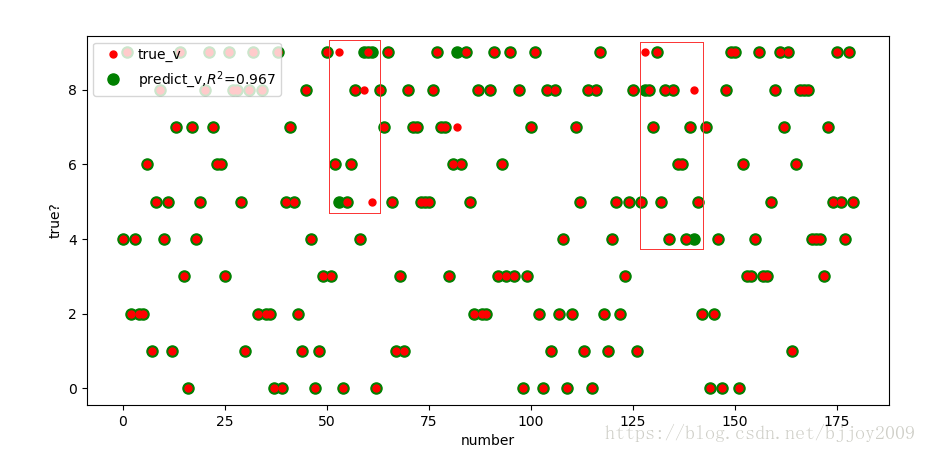
(2)输出结果,测试数据集y_test,和预测y_predict=lr.predict(x_test)。
红框找到几个不同的,这里还是写段代码查找比较好。
